publications
Reverse-chronological. See Google Scholar for the most up-to-date list.
2026
- RecSys
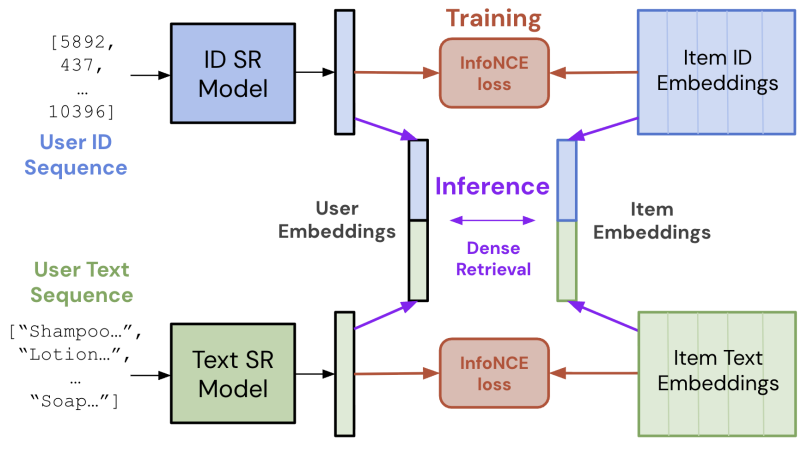 Understanding ID-Text Complementarity in Sequential RecommendationLiam Collins, Bhuvesh Kumar, Clark Mingxuan Ju, Tong Zhao, Donald Loveland, Leonardo Neves, and Neil ShahIn ACM Conference on Recommender Systems, 2026
Understanding ID-Text Complementarity in Sequential RecommendationLiam Collins, Bhuvesh Kumar, Clark Mingxuan Ju, Tong Zhao, Donald Loveland, Leonardo Neves, and Neil ShahIn ACM Conference on Recommender Systems, 2026Dense retrieval-based Sequential Recommendation (SR) systems increasingly leverage text features to represent items, and generally do so in one of two ways: (i) by completely replacing ID embeddings with text embeddings, or (ii) by carefully combining ID and text embeddings through complex fusion mechanisms. While these lines of work have produced strong recommendation performances, they offer conflicting perspectives on ID-text complementarity, or the extent to which ID and text embeddings specialize in modeling different signals: the former suggests a lack of complementarity, and the latter argues it exists but must be harnessed carefully. Moreover, neither workstream conducts an in-depth study of ID-text complementarity. We aim to clarify this picture by developing a rigorous understanding of the complementarity of ID- and text-based SR models in this work. Our study reveals that these models do learn complementary signals, meaning that either should provide performance gain when used properly alongside the other. Motivated by this, we introduce and evaluate a new, simple SR baseline that preserves ID-text complementarity through independent model training, then harnesses it via ensembling. Despite this method’s simplicity, we show it outperforms several competitive SR baselines, implying a third perspective on ID-text complementarity: both features are necessary to achieve state-of-the-art SR performance, but complex fusion strategies are not.
- RecSys
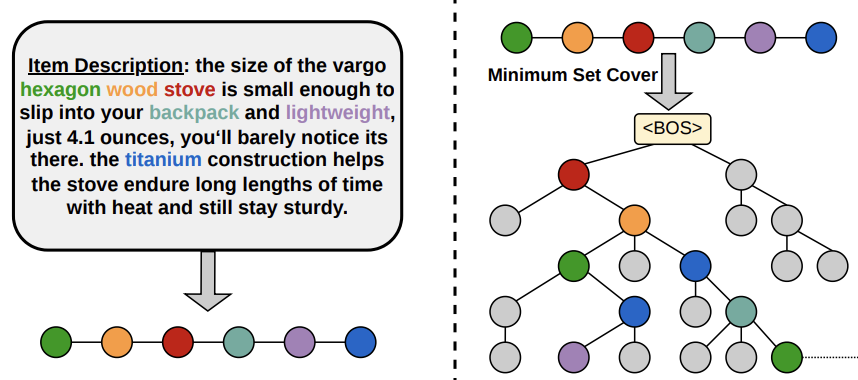 Beyond Fixed Depths and Widths: Optimizing Textual Decoding Tries in LLM-based Generative RecommendationJingzhe Liu, Hanbing Wang, Jiliang Tang, Liam Collins, Tong Zhao, Neil Shah, and Clark Mingxuan JuIn ACM Conference on Recommender Systems, 2026
Beyond Fixed Depths and Widths: Optimizing Textual Decoding Tries in LLM-based Generative RecommendationJingzhe Liu, Hanbing Wang, Jiliang Tang, Liam Collins, Tong Zhao, Neil Shah, and Clark Mingxuan JuIn ACM Conference on Recommender Systems, 2026Generative recommendation (GR) is an increasingly popular paradigm in recommender systems, with a prominent line of work using LLMs as autoregressive backbones to predict the next item’s term IDs (e.g., titles or keywords). The success of autoregressive generation hinges on constrained beam search over a decoding trie to ensure that generated outputs correspond to valid items. However, current research predominantly focuses on generating more comprehensive term IDs to describe items, while largely neglecting the structural design of the decoding trie formed by these terms. This can lead to a trie that is poorly suited to beam search, which degrades performance. To address this, we examine the effectiveness of term IDs from the perspective of decoding trie optimization. Through empirical and theoretical analyses, we identify two desirable properties for a highly performant trie: (1) adaptive and variable ID length, enabling items with varying semantic richness to be represented by IDs of appropriate lengths, and (2) constrained branching factors, especially at shallow levels, which drastically improves the success rate of constrained beam search. Motivated by these properties, we introduce BONSAI: Branching-Optimized Node Structure for Adaptive Identifiers, a novel framework that co-designs textual term IDs and their underlying decoding trie. BONSAI extracts recommendation-informative words from item metadata and employs a minimum set cover formulation to recursively build a trie that satisfies the above properties. Experiments reveal that BONSAI achieves up to a 21.6% relative improvement over state-of-the-art baselines. Further analyses confirm the crucial role of our proposed properties, and demonstrate their generalizability to be applied to enhance the performance of other term ID methods.
- preprint
 Implicit Reasoning for Large Language Model-based Generative RecommendationYinhan He, Liam Collins, Bhuvesh Kumar, Jundong Li, Neil Shah, and Donald LovelandarXiv preprint, 2026
Implicit Reasoning for Large Language Model-based Generative RecommendationYinhan He, Liam Collins, Bhuvesh Kumar, Jundong Li, Neil Shah, and Donald LovelandarXiv preprint, 2026Large Language Models (LLMs) are increasingly adopted as backbones for Generative Recommendation (GR), promising access to pretrained world knowledge. Yet reliably invoking this knowledge for GR remains poorly understood. A key obstacle is that LLM-based GR typically represents items with Semantic IDs (SIDs), disrupting LLMs’ natural-language reasoning interface because these tokens are unseen by the LLM during pretraining. Existing approaches address this with expensive multi-stage pipelines that ground SIDs and elicit explicit rationales, but offer limited insight into when and why each stage is necessary. In this work, we systematically decompose explicit reasoning training pipelines for LLM-based GR, revealing three key limitations: weakened world-knowledge verbalization, misalignment between SID and natural-language token embedding spaces, and sensitivity to rationale quality, all of which hurt explicit reasoning performance. To circumvent these issues, we propose PauseRec, a lightweight implicit reasoning paradigm tailored for GR. PauseRec is exceptionally practical, avoiding costly reasoning trace acquisition and reasoning alignment training, leading to a multitude of benefits: (1) it outperforms standard explicit CoT methods by up to 6.22%, (2) it reduces training cost by up to 65% GPU hours, and (3) it speeds up inference by up to 71.3%. These results position PauseRec as a lightweight alternative to explicit rationale generation, enabling more effective and efficient LLM-based GR.
- preprint
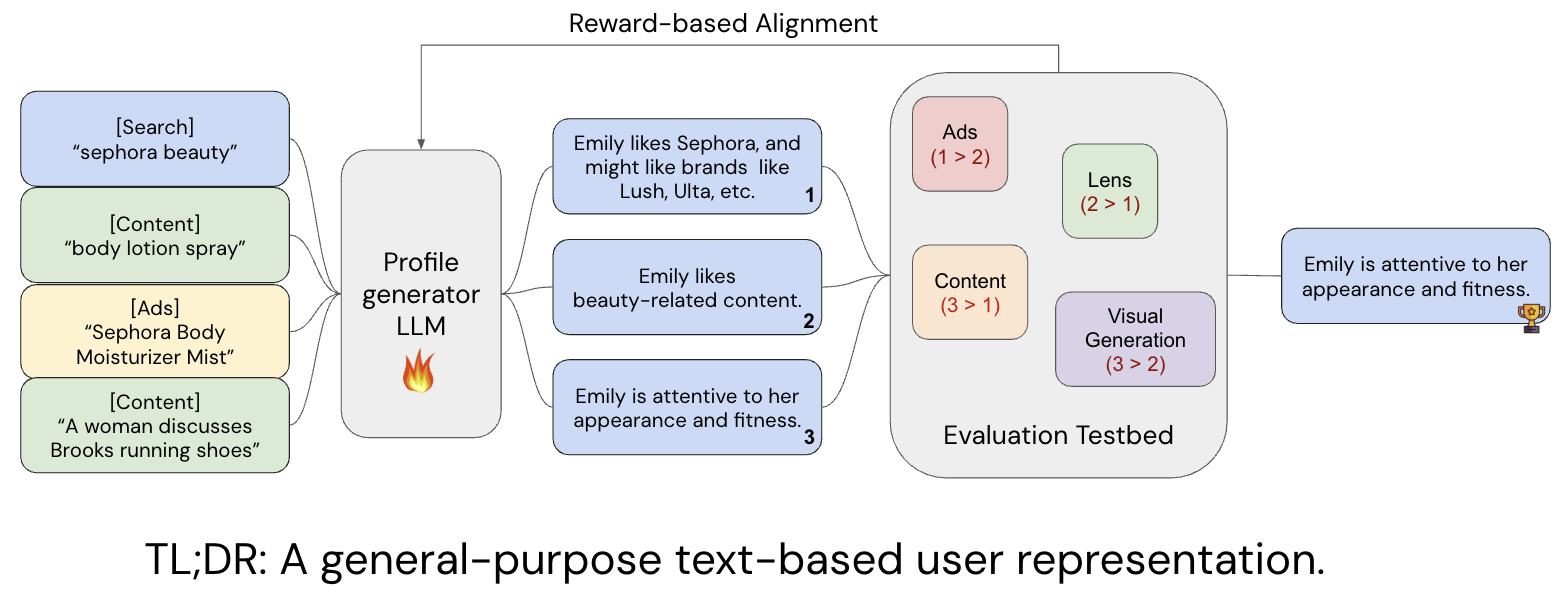 Self-supervised User Profile Generation for PersonalizationClark Mingxuan Ju, Yuwei Qiu, Tong Zhao, and Neil ShaharXiv preprint, 2026
Self-supervised User Profile Generation for PersonalizationClark Mingxuan Ju, Yuwei Qiu, Tong Zhao, and Neil ShaharXiv preprint, 2026Personalizing large language models (LLMs) has become a central challenge as LLMs are deployed across recommendation, search, dialogue, and content generation – settings where the same query should yield different answers given different users. A promising route is to summarize each user’s interaction history into a natural-language memory or profile and prepend it to the prompt to facilitate personalization. Existing methods learn such profile generators with explicit rewards derived from labeled downstream tasks, which are expensive and sparse as they require annotated supervision for every target task. In light of this challenge, we introduce Bidirectional User Modeling via Profiles (BUMP), a self-supervised framework that trains a profile generator without any downstream labels. Specifically, given a user’s interaction history, we use GRPO to train an LLM to emit a free-form textual profile under a bidirectional in-batch ranking objective: a small LLM judge measures (i) how well the generated profile, used as a query, ranks the user’s own held-out interactions above interactions from other users in the batch, and (ii) how well a held-out interaction, used as a query, ranks the user’s own profile above profiles of other users. Both directions are scored with multi-positive NDCG and combined into a dense reward per rollout; other users in the batch supply free negatives, so every training example yields supervision from raw interaction logs alone. Evaluated on the LaMP benchmark, BUMP matches or outperforms closed-source APIs and prior methods relying on labeled rewards, while requiring no task label at training.
- preprint
 MLPs are Efficient Distilled Generative RecommendersZitian Guo, Yupeng Hou, Clark Mingxuan Ju, Neil Shah, and Julian McAuleyarXiv preprint, 2026
MLPs are Efficient Distilled Generative RecommendersZitian Guo, Yupeng Hou, Clark Mingxuan Ju, Neil Shah, and Julian McAuleyarXiv preprint, 2026Generative recommendation models employing Semantic IDs (SIDs) exhibit strong potential, yet their practical deployment is bottlenecked by the high inference latency of beam-expanded autoregressive decoding. In this work, we identify that standard attention-heavy Transformer decoders represent a structural overkill for this task: the hierarchical nature of SIDs makes prediction difficulty drops sharply after the first token, rendering repeated attention computations highly redundant. Driven by this insight, we propose SID-MLP, a lightweight MLP-centric distillation framework that fundamentally simplifies the decoding paradigm for GR. Instead of executing complex, step-by-step attention mechanisms, our approach captures the global user context in a single operation, decoupled from sequential token prediction. We then distill the heavy autoregressive teacher into position-specific MLP heads, eliminating the dense attention overhead while preserving prefix and context dependencies. Extensive experiments demonstrate that SID-MLP matches the accuracy of teacher models while accelerating inference by 8.74x. Crucially, this distillation strategy can serve as a plug-and-play accelerator for different backbones and tokenizer settings. Furthermore, we introduce SID-MLP++, extending our distillation framework to replace the Transformer encoder, unlocking further latency reductions. Ultimately, our work reveals that decoder-side MLPs distillation is an effective acceleration path for structured SID recommendation, while full encoder replacement offers an additional speed–accuracy trade-off.
- preprint
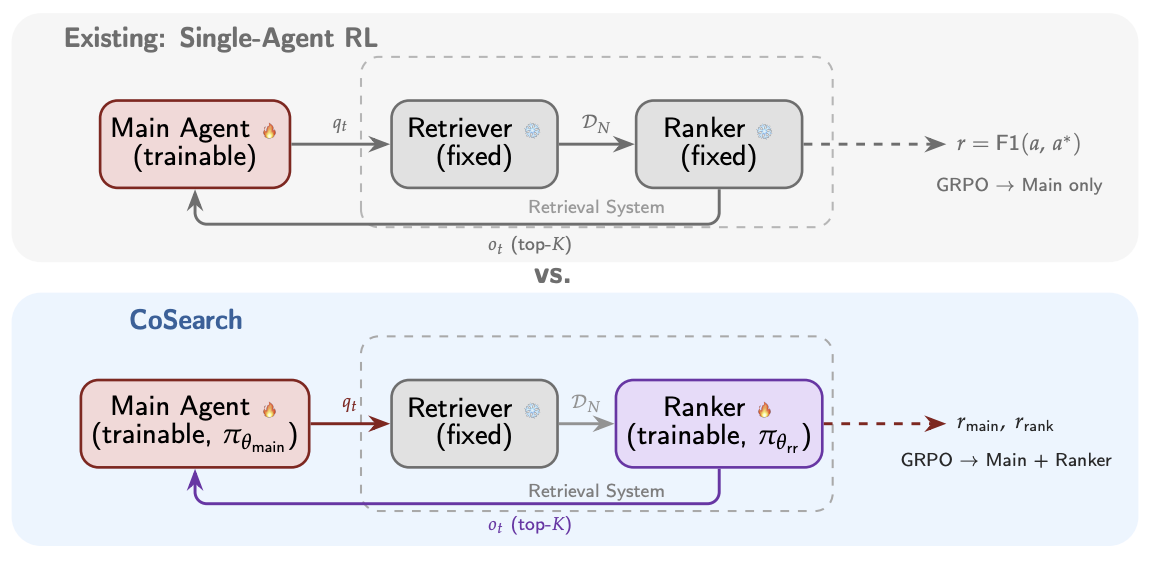 CoSearch: Joint Training of Reasoning and Document Ranking via Reinforcement Learning for Agentic SearchHansi Zeng, Liam Collins, Bhuvesh Kumar, Neil Shah, and Hamed ZamaniarXiv preprint, 2026
CoSearch: Joint Training of Reasoning and Document Ranking via Reinforcement Learning for Agentic SearchHansi Zeng, Liam Collins, Bhuvesh Kumar, Neil Shah, and Hamed ZamaniarXiv preprint, 2026Agentic search – the task of training agents that iteratively reason, issue queries, and synthesize retrieved information to answer complex questions – has achieved remarkable progress through reinforcement learning (RL). However, existing approaches such as Search-R1, treat the retrieval system as a fixed tool, optimizing only the reasoning agent while the retrieval component remains unchanged. A preliminary experiment reveals that the gap between an oracle and a fixed retrieval system reaches up to +26.8% relative F1 improvement across seven QA benchmarks, suggesting that the retrieval system is a key bottleneck in scaling agentic search performance. Motivated by this finding, we propose CoSearch, a framework that jointly trains a multi-step reasoning agent and a generative document ranking model via Group Relative Policy Optimization (GRPO). To enable effective GRPO training for the ranker – whose inputs vary across reasoning trajectories – we introduce a semantic grouping strategy that clusters sub-queries by token-level similarity, forming valid optimization groups without additional rollouts. We further design a composite reward combining ranking quality signals with trajectory-level outcome feedback, providing the ranker with both immediate and long-term learning signals. Experiments on seven single-hop and multi-hop QA benchmarks demonstrate consistent improvements over strong baselines, with ablation studies validating each design choice. Our results show that joint training of the reasoning agent and retrieval system is both feasible and strongly performant, pointing to a key ingredient for future search agents.
- ACL
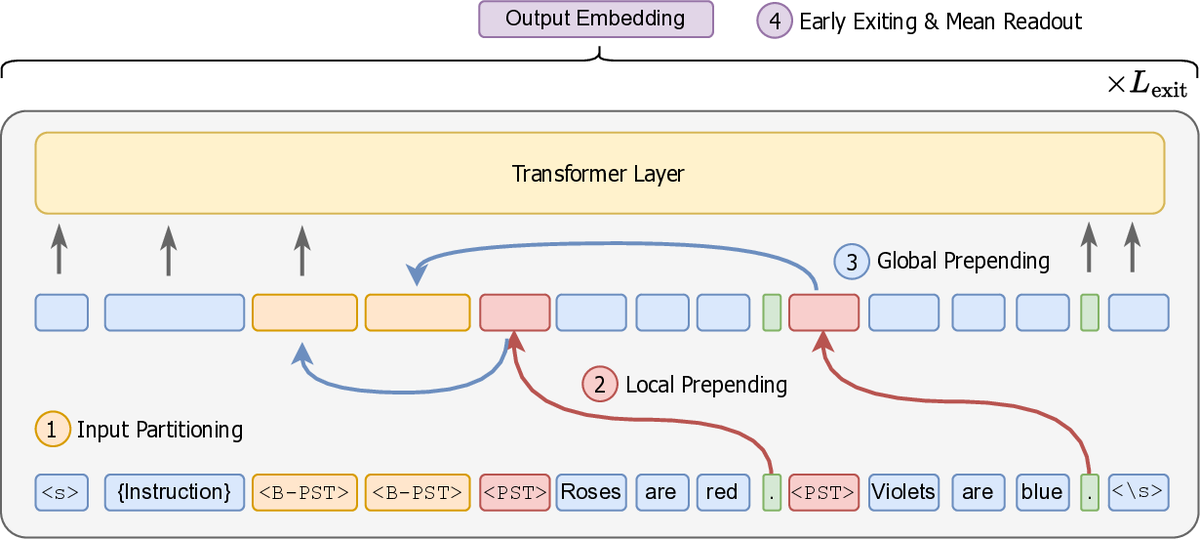 Hierarchical Token Prepending: Enhancing Information Flow in Decoder-based LLM EmbeddingsXueying Ding, Xingyue Huang, Clark Ju, Liam Collins, Yozen Liu, Leman Akoglu, Neil Shah, and Tong ZhaoIn Annual Meeting of the Association for Computational Linguistics, 2026
Hierarchical Token Prepending: Enhancing Information Flow in Decoder-based LLM EmbeddingsXueying Ding, Xingyue Huang, Clark Ju, Liam Collins, Yozen Liu, Leman Akoglu, Neil Shah, and Tong ZhaoIn Annual Meeting of the Association for Computational Linguistics, 2026Large language models produce powerful text embeddings, but their causal attention mechanism restricts the flow of information from later to earlier tokens, degrading representation quality. While recent methods attempt to solve this by prepending a single summary token, they over-compress information, hence harming performance on long documents. We propose Hierarchical Token Prepending (HTP), a method that resolves two critical bottlenecks. To mitigate attention-level compression, HTP partitions the input into blocks and prepends block-level summary tokens to subsequent blocks, creating multiple pathways for backward information flow. To address readout-level over-squashing, we replace last-token pooling with mean-pooling, a choice supported by theoretical analysis. HTP achieves consistent performance gains across 11 retrieval datasets and 30 general embedding benchmarks, especially in long-context settings. As a simple, architecture-agnostic method, HTP enhances both zero-shot and finetuned models, offering a scalable route to superior long-document embeddings.
- ACL
 Threshold Differential Attention for Sink-Free, Ultra-Sparse, and Non-Dispersive Language ModelingXingyue Huang, Xueying Ding, Mingxuan Ju, Yozen Liu, Neil Shah, and Tong ZhaoIn Annual Meeting of the Association for Computational Linguistics, 2026
Threshold Differential Attention for Sink-Free, Ultra-Sparse, and Non-Dispersive Language ModelingXingyue Huang, Xueying Ding, Mingxuan Ju, Yozen Liu, Neil Shah, and Tong ZhaoIn Annual Meeting of the Association for Computational Linguistics, 2026Softmax attention struggles with long contexts due to structural limitations: the strict sum-to-one constraint forces attention sinks on irrelevant tokens, and probability mass disperses as sequence lengths increase. We tackle these problems with Threshold Differential Attention (TDA), a sink-free attention mechanism that achieves ultra-sparsity and improved robustness at longer sequence lengths without the computational overhead of projection methods or the performance degradation caused by noise accumulation of standard rectified attention. TDA applies row-wise extreme-value thresholding with a length-dependent gate, retaining only exceedances. Inspired by the differential transformer, TDA also subtracts an inhibitory view to enhance expressivity. Theoretically, we prove that TDA controls the expected number of spurious survivors per row to O(1) and that consensus spurious matches across independent views vanish as context grows. Empirically, TDA produces >99% exact zeros and eliminates attention sinks while maintaining competitive performance on standard and long-context benchmarks.
- SIGIR
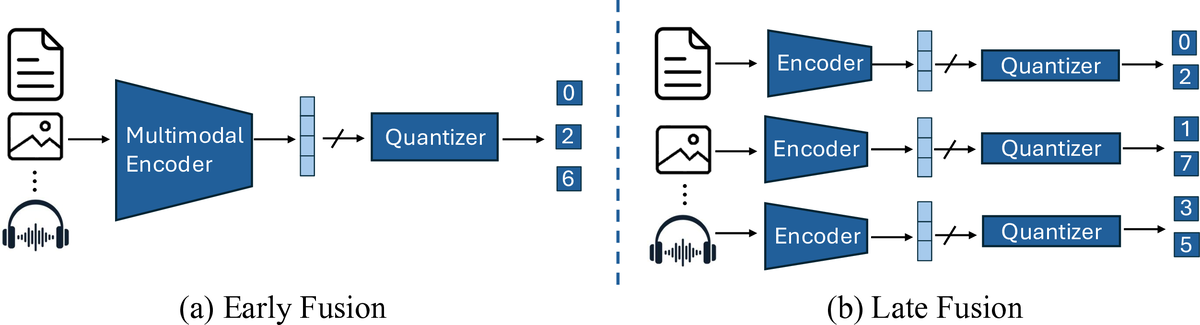 Beyond Unimodal Perspectives: Generative Retrieval with Multimodal SemanticsJing Zhu, Mingxuan Ju, Yozen Liu, Shubham Vij, Danai Koutra, Neil Shah, and Tong ZhaoIn ACM SIGIR Conference on Research and Development in Information Retrieval, 2026
Beyond Unimodal Perspectives: Generative Retrieval with Multimodal SemanticsJing Zhu, Mingxuan Ju, Yozen Liu, Shubham Vij, Danai Koutra, Neil Shah, and Tong ZhaoIn ACM SIGIR Conference on Research and Development in Information Retrieval, 2026Generative recommendation (GR) has become a powerful paradigm in recommendation systems that implicitly links modality and semantics to item representation, in contrast to previous methods that relied on non-semantic item identifiers in autoregressive models. However, previous research has predominantly treated modalities in isolation, typically assuming item content is unimodal (usually text). We argue that this is a significant limitation given the rich, multimodal nature of real-world data and the potential sensitivity of GR models to modality choices and usage. Our work aims to explore the critical problem of Multimodal Generative Recommendation (MGR), highlighting the importance of modality choices in GR nframeworks. We reveal that GR models are particularly sensitive to different modalities and examine the challenges in achieving effective GR when multiple modalities are available. By evaluating design strategies for effectively leveraging multiple modalities, we identify key challenges and introduce MGR-LF++, an enhanced late fusion framework that employs contrastive modality alignment and special tokens to denote different modalities, achieving a performance improvement of over 20% compared to single-modality alternatives.
- SIGIR
 Semantic IDs for Recommender Systems at Snapchat: Use Cases, Technical Challenges, and Design ChoicesClark Mingxuan Ju, Tong Zhao, Leonardo Neves, Liam Collins, Bhuvesh Kumar, Jiwen Ren, Lili Zhang, Wenfeng Zhuo, and 10 more authorsIn ACM SIGIR Conference on Research and Development in Information Retrieval, 2026
Semantic IDs for Recommender Systems at Snapchat: Use Cases, Technical Challenges, and Design ChoicesClark Mingxuan Ju, Tong Zhao, Leonardo Neves, Liam Collins, Bhuvesh Kumar, Jiwen Ren, Lili Zhang, Wenfeng Zhuo, and 10 more authorsIn ACM SIGIR Conference on Research and Development in Information Retrieval, 2026Effective item identifiers (IDs) are an important component for recommender systems (RecSys) in practice, and are commonly adopted in many use cases such as retrieval and ranking. IDs can encode collaborative filtering signals within training data, such that RecSys models can extrapolate during the inference and personalize the prediction based on users’ behavioral histories. Recently, Semantic IDs (SIDs) have become a trending paradigm for RecSys. In comparison to the conventional atomic ID, an SID is an ordered list of codes, derived from tokenizers such as residual quantization, applied to semantic representations commonly extracted from foundation models or collaborative signals. SIDs have drastically smaller cardinality than the atomic counterpart, and induce semantic clustering in the ID space. At Snapchat, we apply SIDs as auxiliary features for ranking models, and also explore SIDs as additional retrieval sources in different ML applications. In this paper, we discuss practical technical challenges we encountered while applying SIDs, experiments we have conducted, and design choices we have iterated to mitigate these challenges. Backed by promising offline results on both internal data and academic benchmarks as well as online A/B studies, SID variants have been launched in multiple production models with positive metrics impact.
- ICML
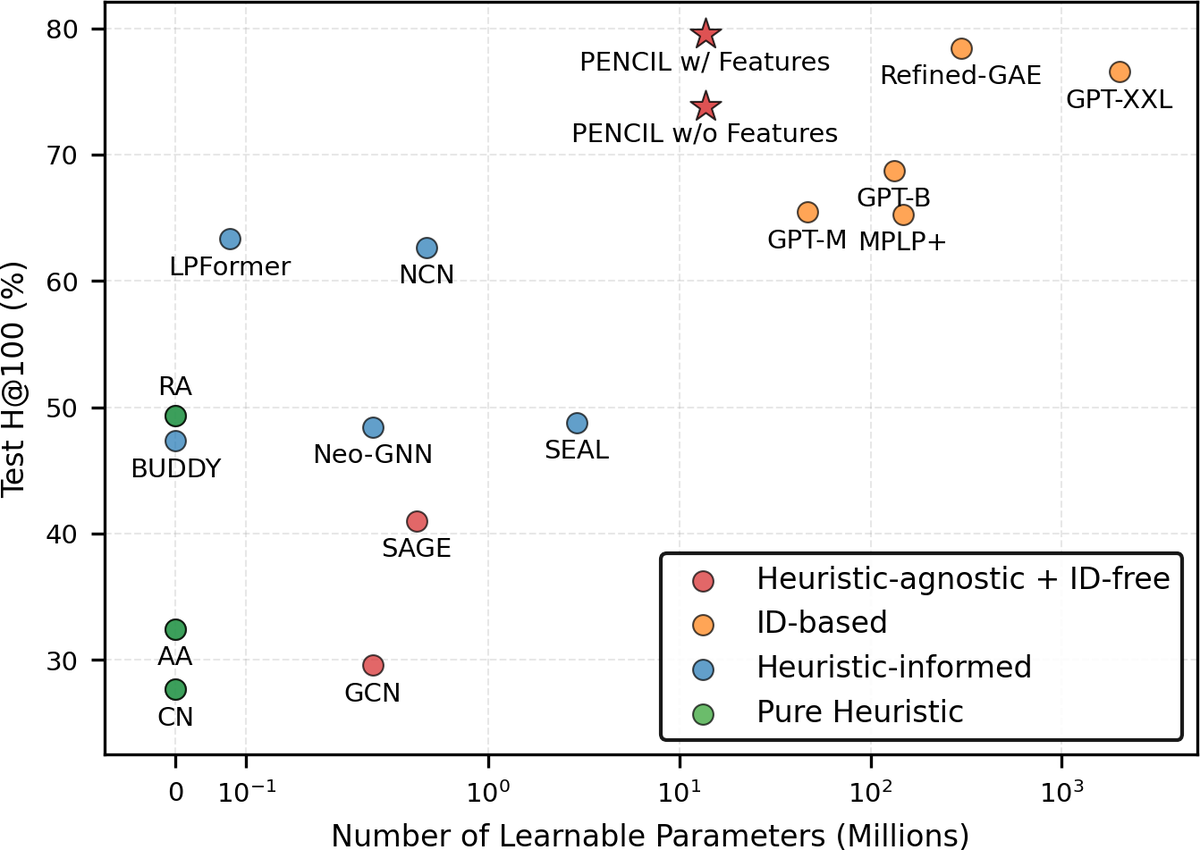 Plain Transformers are Surprisingly Powerful Link PredictorsQuang Truong, Yu Song, Donald Loveland, Clark Ju, Tong Zhao, Neil Shah, and Jiliang TangIn International Conference on Machine Learning, 2026
Plain Transformers are Surprisingly Powerful Link PredictorsQuang Truong, Yu Song, Donald Loveland, Clark Ju, Tong Zhao, Neil Shah, and Jiliang TangIn International Conference on Machine Learning, 2026Link prediction is a core challenge in graph machine learning, demanding models that capture rich and complex topological dependencies. While Graph Neural Networks (GNNs) are the standard solution, state-of-the-art pipelines often rely on explicit structural heuristics or memory-intensive node embeddings – approaches that struggle to generalize or scale to massive graphs. Emerging Graph Transformers (GTs) offer a potential alternative but often incur significant overhead due to complex structural encodings, hindering their applications to large-scale link prediction. We challenge these sophisticated paradigms with PENCIL, an encoder-only plain Transformer that replaces hand-crafted priors with attention over sampled local subgraphs, retaining the scalability and hardware efficiency of standard Transformers. Through experimental and theoretical analysis, we show that PENCIL extracts richer structural signals than GNNs, implicitly generalizing a broad class of heuristics and subgraph-based expressivity. Empirically, PENCIL outperforms heuristic-informed GNNs and is far more parameter-efficient than ID-embedding–based alternatives, while remaining competitive across diverse benchmarks – even without node features. Our results challenge the prevailing reliance on complex engineering techniques, demonstrating that simple design choices are potentially sufficient to achieve the same capabilities.
- preprint
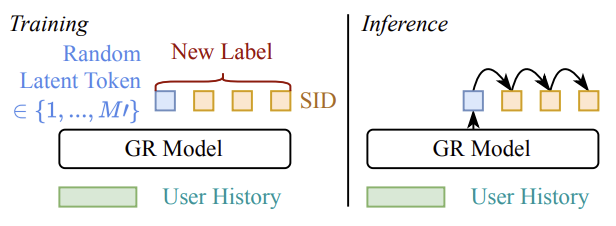 Expressiveness Limits of Autoregressive Semantic ID Generation in Generative RecommendationYupeng Hou, Haven Kim, Clark Ju, Eduardo Escoto, Neil Shah, and Julian McAuleyarXiv preprint, 2026
Expressiveness Limits of Autoregressive Semantic ID Generation in Generative RecommendationYupeng Hou, Haven Kim, Clark Ju, Eduardo Escoto, Neil Shah, and Julian McAuleyarXiv preprint, 2026Generative recommendation (GR) models generate items by autoregressively producing a sequence of discrete tokens that jointly index the target item. However, this autoregressive generation process also induces a structured decoding space whose impact on model expressiveness remains underexplored. Specifically, token-by-token generation can be viewed as traversing a decoding tree induced by semantic ID tokens, where leaf nodes correspond to candidate items. We observe that the item probabilities produced by GR models are strongly correlated with this tree structure: items that are close in the tree tend to receive similar probabilities for any given user, making it difficult to distinguish among them based on user-specific preferences. We further show theoretically that such structural correlations prevent GR models from representing even simple patterns that can be well captured by conventional collaborative filtering models. To mitigate this issue, we propose Latte, a simple modification that injects a latent token before each semantic ID, reshaping the decoding space from a single tree into multiple latent-token-conditioned trees. This design creates multiple paths with varying tree distances between items, relaxing tree-induced probability coupling and yielding an average of 3.45% relative improvement on NDCG@10. Our code is available at https://github.com/hyp1231/Latte.
- preprint
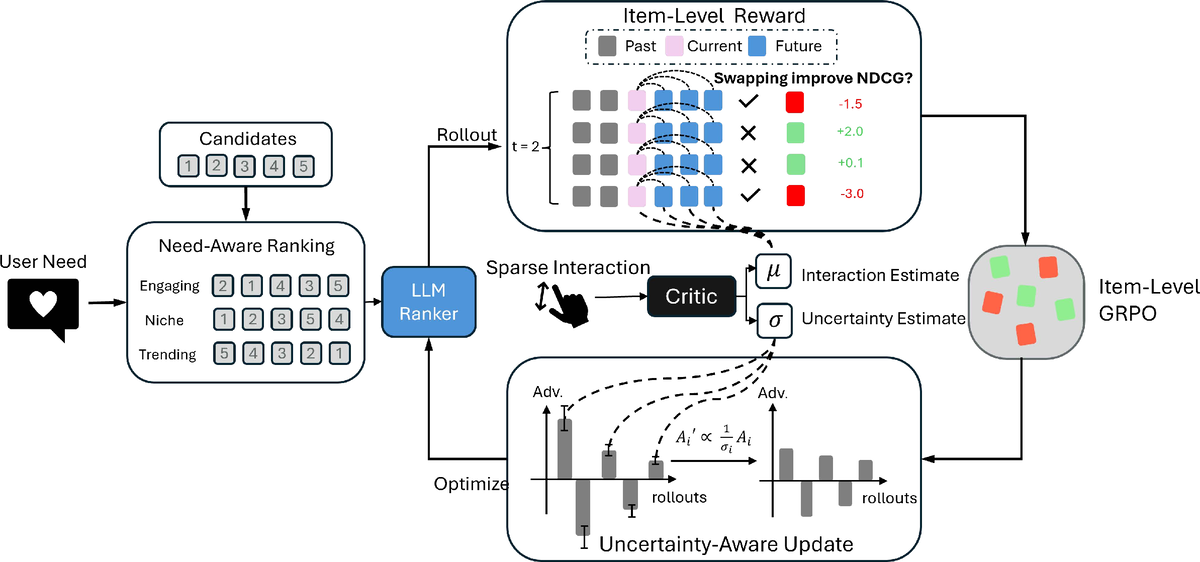 FlexRec: Adapting LLM-based Recommenders for Flexible Needs via Reinforcement LearningYijun Pan, Weikang Qiu, Qiyao Ma, Mingxuan Ju, Tong Zhao, Neil Shah, and Rex YingPreprint, 2026
FlexRec: Adapting LLM-based Recommenders for Flexible Needs via Reinforcement LearningYijun Pan, Weikang Qiu, Qiyao Ma, Mingxuan Ju, Tong Zhao, Neil Shah, and Rex YingPreprint, 2026Modern recommender systems must adapt to dynamic, need-specific objectives for diverse recommendation scenarios, yet most traditional recommenders are optimized for a single static target and struggle to reconfigure behavior on demand. Recent advances in reinforcement-learning-based post-training have unlocked strong instruction-following and reasoning capabilities in LLMs, suggesting a principled route for aligning them to complex recommendation goals. Motivated by this, we study closed-set autoregressive ranking, where an LLM generates a permutation over a fixed candidate set conditioned on user context and an explicit need instruction. However, applying RL to this setting faces two key obstacles: (i) sequence-level rewards yield coarse credit assignment that fails to provide fine-grained training signals, and (ii) interaction feedback is sparse and noisy, which together lead to inefficient and unstable updates. We propose FlexRec, a post-training RL framework that addresses both issues with (1) a causally grounded item-level reward based on counterfactual swaps within the remaining candidate pool, and (2) critic-guided, uncertainty-aware scaling that explicitly models reward uncertainty and down-weights low-confidence rewards to stabilize learning under sparse supervision. Across diverse recommendation scenarios and objectives, FlexRec achieves substantial gains: it improves NDCG@5 by up to \textbf{59%} and Recall@5 by up to \textbf{109.4%} in need-specific ranking, and further achieves up to \textbf{24.1%} Recall@5 improvement under generalization settings, outperforming strong traditional recommenders and LLM-based baselines.
- WSDM
 Sequential Data Augmentation for Generative RecommendationGeon Lee, Bhuvesh Kumar, Clark Ju, Tong Zhao, Kijung Shin, Neil Shah, and Liam CollinsIn ACM International Conference on Web Search and Data Mining, 2026
Sequential Data Augmentation for Generative RecommendationGeon Lee, Bhuvesh Kumar, Clark Ju, Tong Zhao, Kijung Shin, Neil Shah, and Liam CollinsIn ACM International Conference on Web Search and Data Mining, 2026Generative recommendation plays a crucial role in personalized systems, predicting users’ future interactions from their historical behavior sequences. A critical yet underexplored factor in training these models is data augmentation, the process of constructing training data from user interaction histories. By shaping the training distribution, data augmentation directly and often substantially affects model generalization and performance. Nevertheless, in much of the existing work, this process is simplified, applied inconsistently, or treated as a minor design choice, without a systematic and principled understanding of its effects. Motivated by our empirical finding that different augmentation strategies can yield large performance disparities, we conduct an in-depth analysis of how they reshape training distributions and influence alignment with future targets and generalization to unseen inputs. To systematize this design space, we propose GenPAS, a generalized and principled framework that models augmentation as a stochastic sampling process over input-target pairs with three bias-controlled steps: sequence sampling, target sampling, and input sampling. This formulation unifies widely used strategies as special cases and enables flexible control of the resulting training distribution. Our extensive experiments on benchmark and industrial datasets demonstrate that GenPAS yields superior accuracy, data efficiency, and parameter efficiency compared to existing strategies, providing practical guidance for principled training data construction in generative recommendation. Our code is available at https://github.com/snap-research/GenPAS.
- ACL
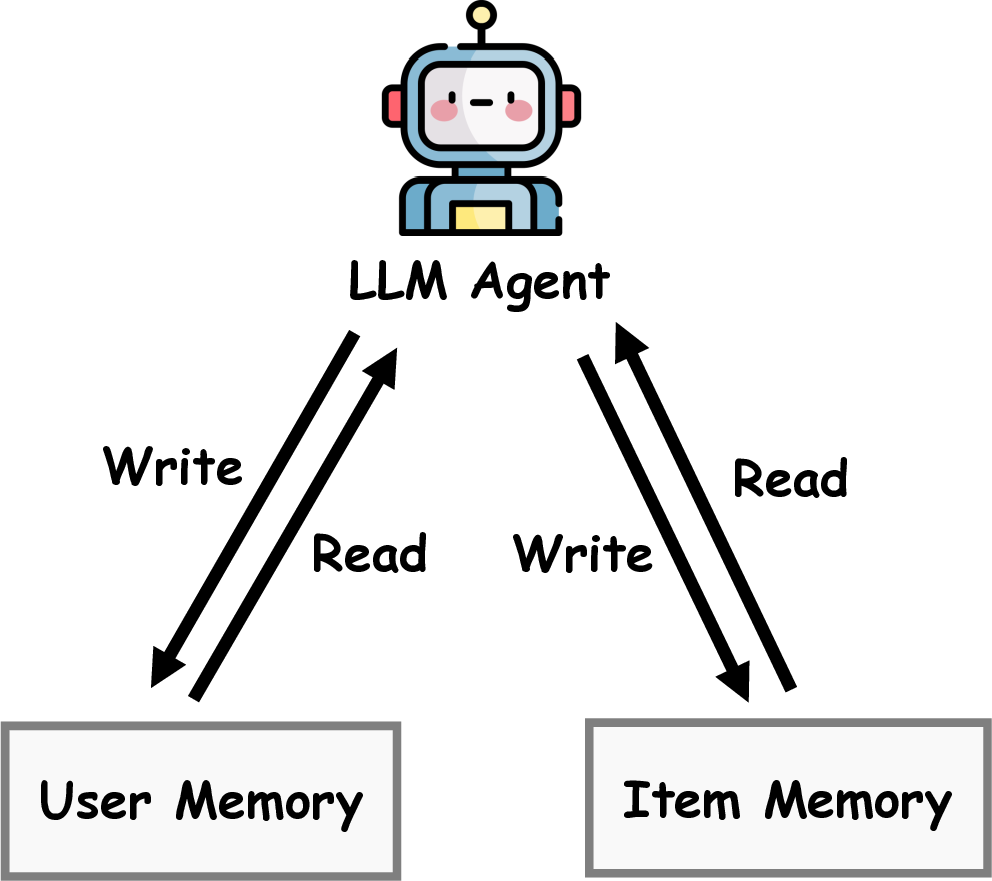 MemRec: Collaborative Memory-Augmented Agentic Recommender SystemWeixin Chen, Yuhan Zhao, Jingyuan Huang, Zihe Ye, Clark Mingxuan Ju, Tong Zhao, Neil Shah, Li Chen, and 1 more authorIn Annual Meeting of the Association for Computational Linguistics, 2026
MemRec: Collaborative Memory-Augmented Agentic Recommender SystemWeixin Chen, Yuhan Zhao, Jingyuan Huang, Zihe Ye, Clark Mingxuan Ju, Tong Zhao, Neil Shah, Li Chen, and 1 more authorIn Annual Meeting of the Association for Computational Linguistics, 2026The evolution of recommender systems has shifted preference storage from rating matrices and dense embeddings to semantic memory in the agentic era. Yet existing agents rely on isolated memory, overlooking crucial collaborative signals. Bridging this gap is hindered by the dual challenges of distilling vast graph contexts without overwhelming reasoning agents with cognitive load, and evolving the collaborative memory efficiently without incurring prohibitive computational costs. To address this, we propose MemRec, a framework that architecturally decouples reasoning from memory management to enable efficient collaborative augmentation. MemRec introduces a dedicated, cost-effective LM_Mem to manage a dynamic collaborative memory graph, serving synthesized, high-signal context to a downstream LLM_Rec. The framework operates via a practical pipeline featuring efficient retrieval and cost-effective asynchronous graph propagation that evolves memory in the background. Extensive experiments on four benchmarks demonstrate that MemRec achieves state-of-the-art performance. Furthermore, architectural analysis confirms its flexibility, establishing a new Pareto frontier that balances reasoning quality, cost, and privacy through support for diverse deployments, including local open-source models. Code:https://github.com/rutgerswiselab/memrec and Homepage: https://memrec.weixinchen.com
- KDD
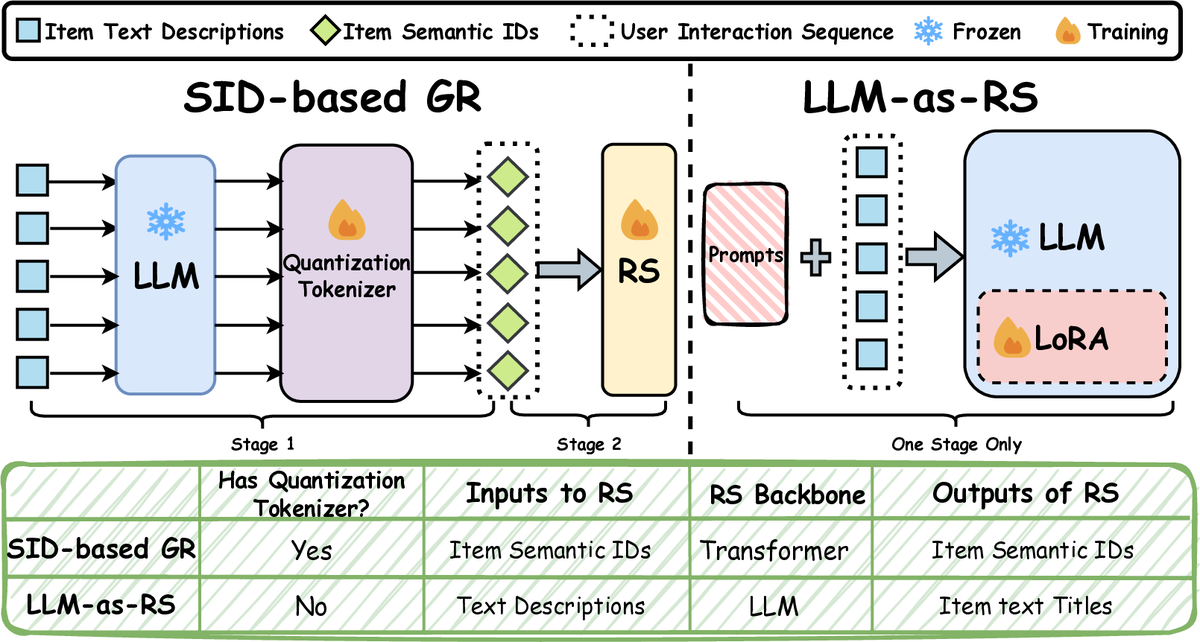 Understanding Generative Recommendation with Semantic IDs from a Model Scaling ViewJingzhe Liu, Liam Collins, Jiliang Tang, Tong Zhao, Neil Shah, and Clark JuIn ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2026
Understanding Generative Recommendation with Semantic IDs from a Model Scaling ViewJingzhe Liu, Liam Collins, Jiliang Tang, Tong Zhao, Neil Shah, and Clark JuIn ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2026Recent advancements in generative models have allowed the emergence of a promising paradigm for recommender systems (RS), known as Generative Recommendation (GR), which tries to unify rich item semantics and collaborative filtering signals. One popular modern approach is to use semantic IDs (SIDs), which are discrete codes quantized from the embeddings of modality encoders (e.g., large language or vision models), to represent items in an autoregressive user interaction sequence modeling setup (henceforth, SID-based GR). While generative models in other domains exhibit well-established scaling laws, our work reveals that SID-based GR shows significant bottlenecks while scaling up the model. In particular, the performance of SID-based GR quickly saturates as we enlarge each component: the modality encoder, the quantization tokenizer, and the RS itself. In this work, we identify the limited capacity of SIDs to encode item semantic information as one of the fundamental bottlenecks. Motivated by this observation, as an initial effort to obtain GR models with better scaling behaviors, we revisit another GR paradigm that directly uses large language models (LLMs) as recommenders (henceforth, LLM-as-RS). Our experiments show that the LLM-as-RS paradigm has superior model scaling properties and achieves up to 20 percent improvement over the best achievable performance of SID-based GR through scaling. We also challenge the prevailing belief that LLMs struggle to capture collaborative filtering information, showing that their ability to model user-item interactions improves as LLMs scale up. Our analyses on both SID-based GR and LLMs across model sizes from 44M to 14B parameters underscore the intrinsic scaling limits of SID-based GR and position LLM-as-RS as a promising path toward foundation models for GR.
2025
- preprint
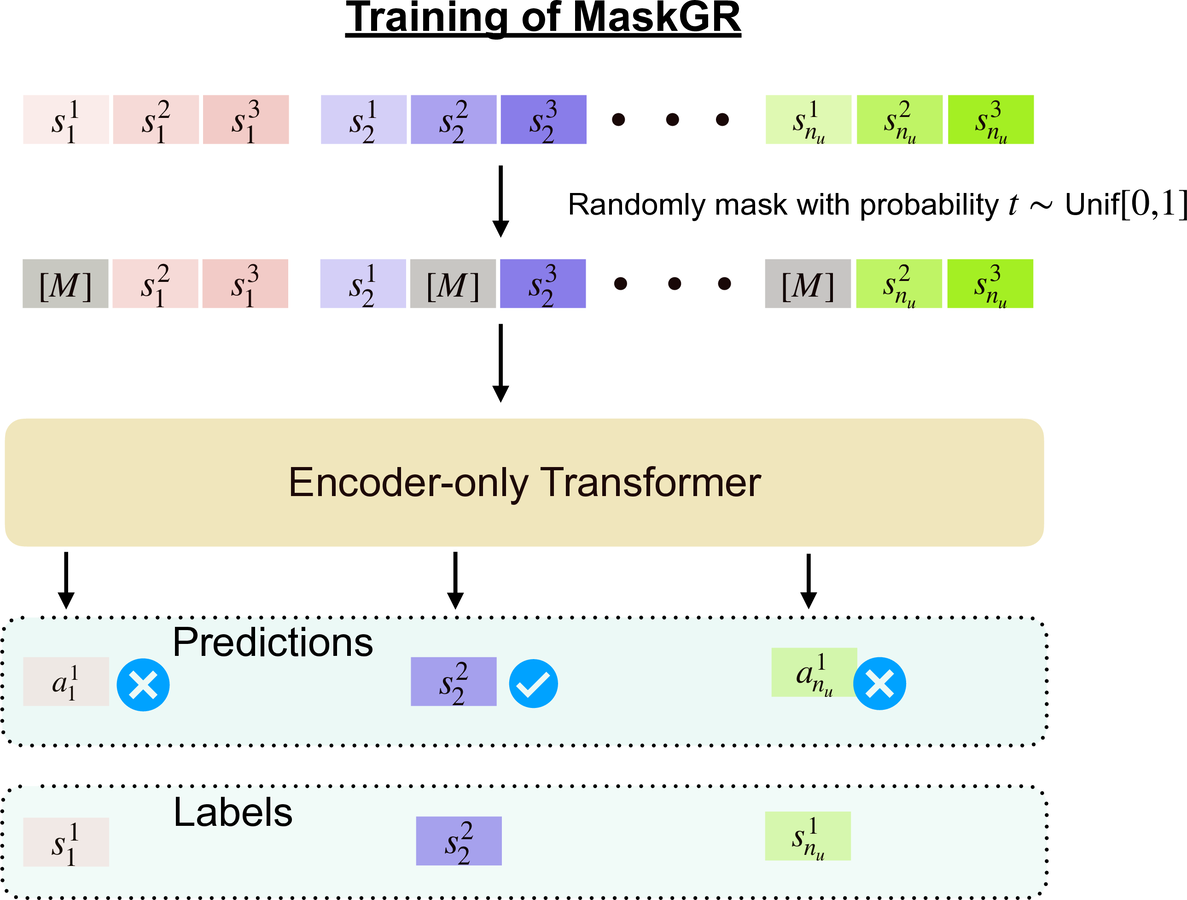 Masked Diffusion for Generative RecommendationKulin Shah, Bhuvesh Kumar, Neil Shah, and Liam CollinsarXiv preprint, 2025
Masked Diffusion for Generative RecommendationKulin Shah, Bhuvesh Kumar, Neil Shah, and Liam CollinsarXiv preprint, 2025Generative recommendation (GR) with semantic IDs (SIDs) has emerged as a promising alternative to traditional recommendation approaches due to its performance gains, capitalization on semantic information provided through language model embeddings, and inference and storage efficiency. Existing GR with SIDs works frame the probability of a sequence of SIDs corresponding to a user’s interaction history using autoregressive modeling. While this has led to impressive next item prediction performances in certain settings, these autoregressive GR with SIDs models suffer from expensive inference due to sequential token-wise decoding, potentially inefficient use of training data and bias towards learning short-context relationships among tokens. Inspired by recent breakthroughs in NLP, we propose to instead model and learn the probability of a user’s sequence of SIDs using masked diffusion. Masked diffusion employs discrete masking noise to facilitate learning the sequence distribution, and models the probability of masked tokens as conditionally independent given the unmasked tokens, allowing for parallel decoding of the masked tokens. We demonstrate through thorough experiments that our proposed method consistently outperforms autoregressive modeling. This performance gap is especially pronounced in data-constrained settings and in terms of coarse-grained recall, consistent with our intuitions. Moreover, our approach allows the flexibility of predicting multiple SIDs in parallel during inference while maintaining superior performance to autoregressive modeling.
- preprint
 Exploiting ID-Text Complementarity via Ensembling for Sequential RecommendationLiam Collins, Bhuvesh Kumar, Clark Ju, Tong Zhao, Donald Loveland, Leonardo Neves, and Neil ShaharXiv preprint, 2025
Exploiting ID-Text Complementarity via Ensembling for Sequential RecommendationLiam Collins, Bhuvesh Kumar, Clark Ju, Tong Zhao, Donald Loveland, Leonardo Neves, and Neil ShaharXiv preprint, 2025Modern Sequential Recommendation (SR) models commonly utilize modality features to represent items, motivated in large part by recent advancements in language and vision modeling. To do so, several works completely replace ID embeddings with modality embeddings, claiming that modality embeddings render ID embeddings unnecessary because they can match or even exceed ID embedding performance. On the other hand, many works jointly utilize ID and modality features, but posit that complex fusion strategies, such as multi-stage training and/or intricate alignment architectures, are necessary for this joint utilization. However, underlying both these lines of work is a lack of understanding of the complementarity of ID and modality features. In this work, we address this gap by studying the complementarity of ID- and text-based SR models. We show that these models do learn complementary signals, meaning that either should provide performance gain when used properly alongside the other. Motivated by this, we propose a new SR method that preserves ID-text complementarity through independent model training, then harnesses it through a simple ensembling strategy. Despite this method’s simplicity, we show it outperforms several competitive SR baselines, implying that both ID and text features are necessary to achieve state-of-the-art SR performance but complex fusion architectures are not.
- CIKM
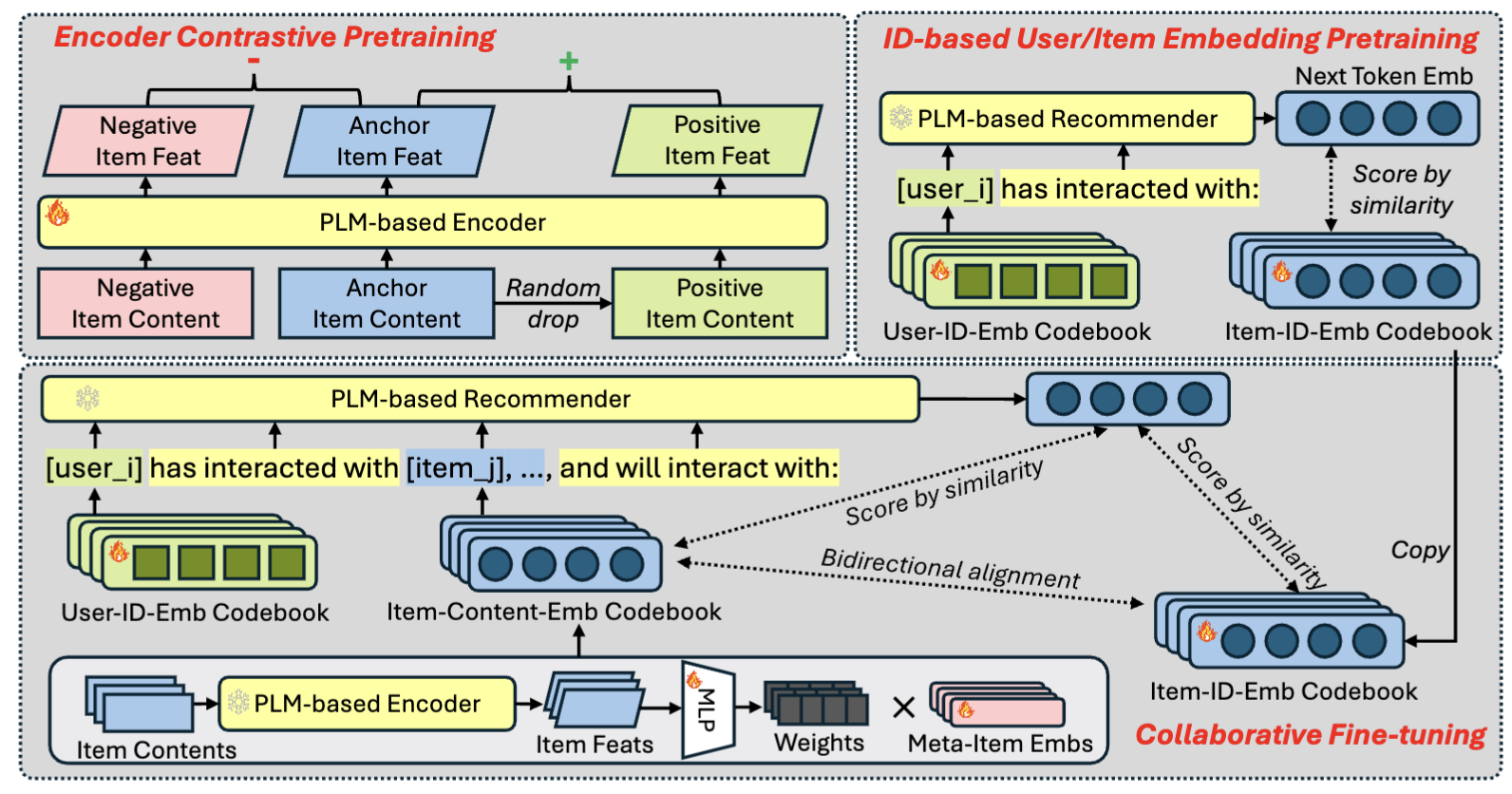 Pretrained Language Model based Cold-Start Recommendation with Meta-Item EmbeddingsZaiyi Zheng, Yaochen Zhu, Haochen Liu, Clark Ju, Tong Zhao, Neil Shah, and Jundong LiIn ACM International Conference on Information and Knowledge Management, 2025
Pretrained Language Model based Cold-Start Recommendation with Meta-Item EmbeddingsZaiyi Zheng, Yaochen Zhu, Haochen Liu, Clark Ju, Tong Zhao, Neil Shah, and Jundong LiIn ACM International Conference on Information and Knowledge Management, 2025Recently, pretrained large language models (LLMs) have been widely adopted in recommendation systems to leverage their textual understanding and reasoning abilities to model user behaviors and suggest future items. A key challenge in this setting is that items on most platforms are not included in the LLM’s training data. Therefore, existing methods often fine-tune LLMs by introducing auxiliary item tokens to capture item semantics. However, in real-world applications such as e-commerce and short video platforms, the item space evolves rapidly, which gives rise to a cold-start setting, where many newly introduced items receive little or even no user engagement. This poses challenges in both learning accurate item token embeddings and generalizing efficiently to accommodate the continual influx of new items. In this work, we propose a novel meta-item token learning strategy to address both these challenges simultaneously. Specifically, we introduce MI4Rec, an LLM-based approach for recommendation that uses just a few learnable meta-item tokens and an LLM encoder to dynamically aggregate meta-items based on item content. We show that this paradigm allows highly efficient and accurate learning in such challenging settings. Extensive experiments on Yelp and Amazon reviews datasets demonstrate the effectiveness of MI4Rec in both warm-start and cold-start recommendations. Notably, MI4Rec achieves an average performance improvement of 20.4% in Recall and NDCG compared to the best-performing baselines. The implementation of MI4Rec is available at https://github.com/zhengzaiyi/MI4Rec.
- CIKM
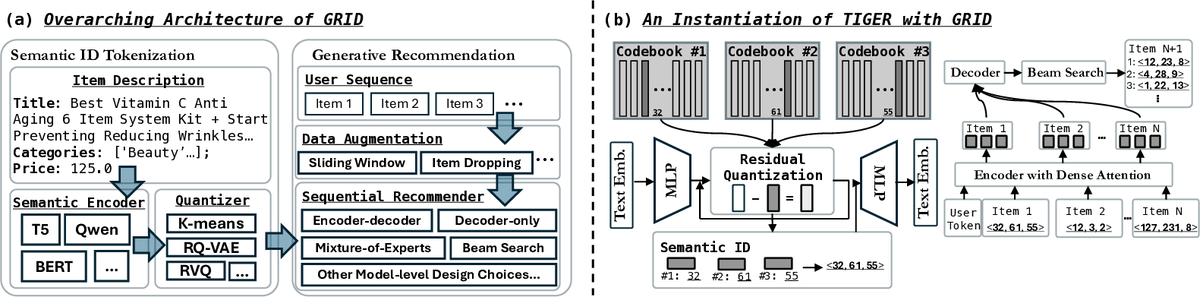 Generative Recommendation with Semantic IDs: A Practitioner’s HandbookClark Ju, Liam Collins, Leonardo Neves, Bhuvesh Kumar, Louis Wang, Tong Zhao, and Neil ShahIn ACM International Conference on Information and Knowledge Management, 2025
Generative Recommendation with Semantic IDs: A Practitioner’s HandbookClark Ju, Liam Collins, Leonardo Neves, Bhuvesh Kumar, Louis Wang, Tong Zhao, and Neil ShahIn ACM International Conference on Information and Knowledge Management, 2025Generative recommendation (GR) has gained increasing attention for its promising performance compared to traditional models. A key factor contributing to the success of GR is the semantic ID (SID), which converts continuous semantic representations (e.g., from large language models) into discrete ID sequences. This enables GR models with SIDs to both incorporate semantic information and learn collaborative filtering signals, while retaining the benefits of discrete decoding. However, varied modeling techniques, hyper-parameters, and experimental setups in existing literature make direct comparisons between GR proposals challenging. Furthermore, the absence of an open-source, unified framework hinders systematic benchmarking and extension, slowing model iteration. To address this challenge, our work introduces and open-sources a framework for Generative Recommendation with semantic ID, namely GRID, specifically designed for modularity to facilitate easy component swapping and accelerate idea iteration. Using GRID, we systematically experiment with and ablate different components of GR models with SIDs on public benchmarks. Our comprehensive experiments with GRID reveal that many overlooked architectural components in GR models with SIDs substantially impact performance. This offers both novel insights and validates the utility of an open-source platform for robust benchmarking and GR research advancement. GRID is open-sourced at https://github.com/snap-research/GRID.
- NeurIPS
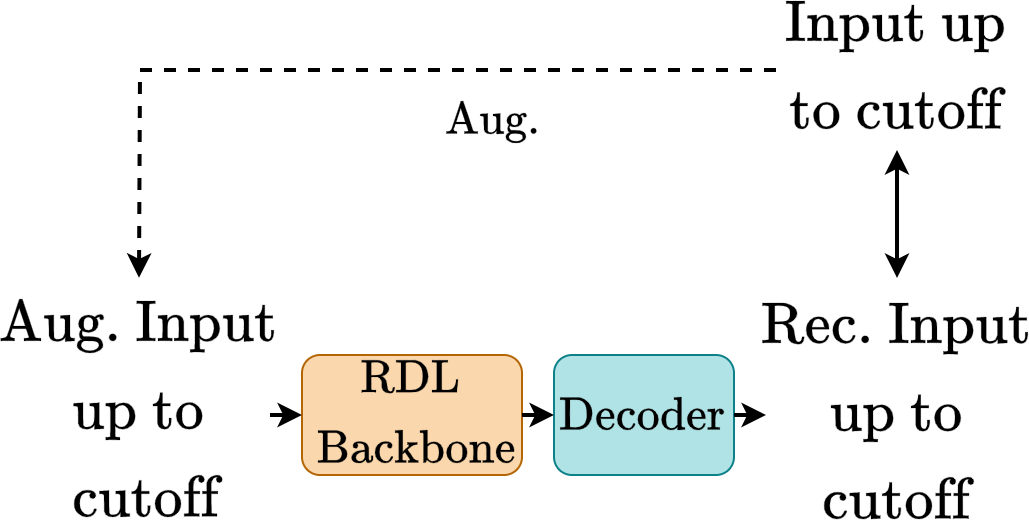 A Pre-Training Framework for Relational Data with Information Theoretic PrinciplesQuang Truong, Zhikai Chen, Clark Ju, Tong Zhao, Neil Shah, and Jiliang TangIn Conference on Neural Information Processing Systems, 2025
A Pre-Training Framework for Relational Data with Information Theoretic PrinciplesQuang Truong, Zhikai Chen, Clark Ju, Tong Zhao, Neil Shah, and Jiliang TangIn Conference on Neural Information Processing Systems, 2025Relational databases underpin critical infrastructure across a wide range of domains, yet the design of generalizable pre-training strategies for learning from relational databases remains an open challenge due to task heterogeneity. Specifically, there exist many possible downstream tasks, as tasks are defined based on relational schema graphs, temporal dependencies, and SQL-defined label logics. An effective pre-training framework is desired to take these factors into account in order to obtain task-aware representations. By incorporating knowledge of the underlying distribution that drives label generation, downstream tasks can benefit from relevant side-channel information. To bridge this gap, we introduce Task Vector Estimation (TVE), a novel pre-training framework that constructs predictive supervisory signals via set-based aggregation over schema traversal graphs, explicitly modeling next-window relational dynamics. We formalize our approach through an information-theoretic lens, demonstrating that task-informed representations retain more relevant signals than those obtained without task priors. Extensive experiments on the RelBench benchmark show that TVE consistently outperforms traditional pre-training baselines. Our findings advocate for pre-training objectives that encode task heterogeneity and temporal structure as design principles for predictive modeling on relational databases. Our code is publicly available at https://github.com/quang-truong/task-vector-estimation.
- LoG
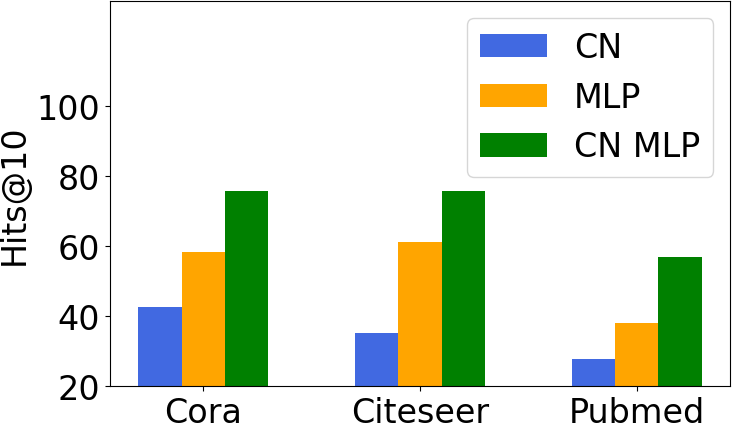 Weak Models Can be Good Teachers: A Case Study on Link Prediction with MLPsZongyue Qin, Shichang Zhang, Clark Ju, Tong Zhao, Neil Shah, and Yizhou SunIn Learning on Graphs, 2025
Weak Models Can be Good Teachers: A Case Study on Link Prediction with MLPsZongyue Qin, Shichang Zhang, Clark Ju, Tong Zhao, Neil Shah, and Yizhou SunIn Learning on Graphs, 2025Link prediction is a crucial graph-learning task with applications including citation prediction and product recommendation. Distilling Graph Neural Networks (GNNs) teachers into Multi-Layer Perceptrons (MLPs) students has emerged as an effective approach to achieve strong performance and reducing computational cost by removing graph dependency. However, existing distillation methods only use standard GNNs and overlook alternative teachers such as specialized model for link prediction (GNN4LP) and heuristic methods (e.g., common neighbors). This paper first explores the impact of different teachers in GNN-to-MLP distillation. Surprisingly, we find that stronger teachers do not always produce stronger students: MLPs distilled from GNN4LP can underperform those distilled from simpler GNNs, while weaker heuristic methods can teach MLPs to near-GNN performance with drastically reduced training costs. Building on these insights, we propose Ensemble Heuristic-Distilled MLPs (EHDM), which eliminates graph dependencies while effectively integrating complementary signals via a gating mechanism. Experiments on ten datasets show an average 7.93% improvement over previous GNN-to-MLP approaches with 1.95-3.32 times less training time, indicating EHDM is an efficient and effective link prediction method. Our code is available at https://github.com/ZongyueQin/EHDM
- TMLR
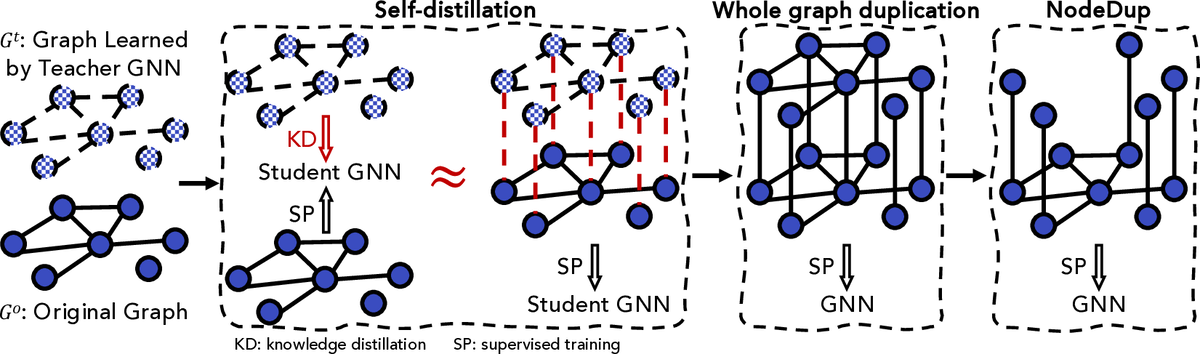 Node Duplication Improves Cold-start Link PredictionZhichun Guo, Tong Zhao, Yozen Liu, Kaiwen Dong, William Shiao, Neil Shah, and Nitesh V. ChawlaIn Transactions on Machine Learning Research, 2025
Node Duplication Improves Cold-start Link PredictionZhichun Guo, Tong Zhao, Yozen Liu, Kaiwen Dong, William Shiao, Neil Shah, and Nitesh V. ChawlaIn Transactions on Machine Learning Research, 2025Graph Neural Networks (GNNs) are prominent in graph machine learning and have shown state-of-the-art performance in Link Prediction (LP) tasks. Nonetheless, recent studies show that GNNs struggle to produce good results on low-degree nodes despite their overall strong performance. In practical applications of LP, like recommendation systems, improving performance on low-degree nodes is critical, as it amounts to tackling the cold-start problem of improving the experiences of users with few observed interactions. In this paper, we investigate improving GNNs’ LP performance on low-degree nodes while preserving their performance on high-degree nodes and propose a simple yet surprisingly effective augmentation technique called NodeDup. Specifically, NodeDup duplicates low-degree nodes and creates links between nodes and their own duplicates before following the standard supervised LP training scheme. By leveraging a ”multi-view” perspective for low-degree nodes, NodeDup shows significant LP performance improvements on low-degree nodes without compromising any performance on high-degree nodes. Additionally, as a plug-and-play augmentation module, NodeDup can be easily applied to existing GNNs with very light computational cost. Extensive experiments show that NodeDup achieves 38.49%, 13.34%, and 6.76% improvements on isolated, low-degree, and warm nodes, respectively, on average across all datasets compared to GNNs and state-of-the-art cold-start methods.
- DMLR
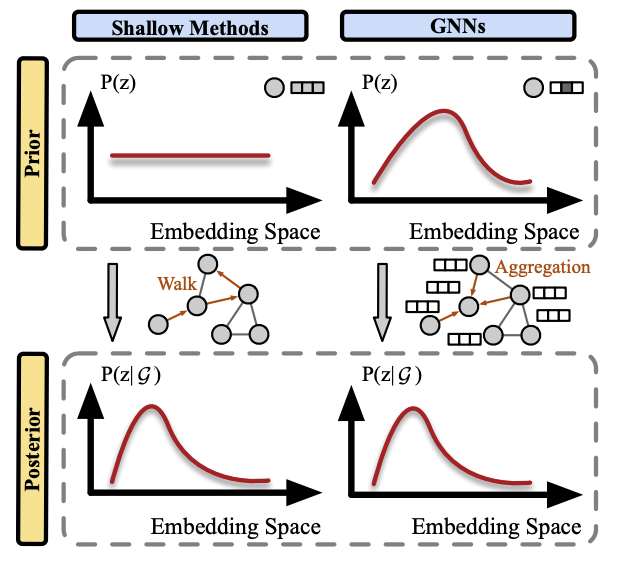 Do Graph Neural Networks Improve Node Representation Learning for All?Yushun Dong, William Shiao, Yozen Liu, Jundong Li, Neil Shah, and Tong ZhaoIn Data-Centric Machine Learning Research, 2025
Do Graph Neural Networks Improve Node Representation Learning for All?Yushun Dong, William Shiao, Yozen Liu, Jundong Li, Neil Shah, and Tong ZhaoIn Data-Centric Machine Learning Research, 2025Graph Neural Networks (GNNs) have garnered increasing attention in recent years, given their significant proficiency in various graph learning tasks. Consequently, there has been a notable transition away from the conventional and prevalent shallow graph embedding methods which pre-dated GNNs. However, in tandem with this transition which is pre-supposed in the literature, an imperative question arises: do GNNs always outperform shallow embedding methods in node representation learning? This question remains inadequately explored, as the field of graph machine learning still lacks a systematic understanding of their relative strengths and limitations. To address this gap, we propose a principled framework that unifies the ideologies of representative shallow graph embedding methods and GNNs. With comparative analysis, we show that GNNs actually bear drawbacks that are typically not shared by shallow embedding methods. These drawbacks are often masked by data characteristics in commonly used benchmarks and thus not well-discussed in the literature, leading to potential suboptimal performance when GNNs are indiscriminately adopted in applications. We further show that our analysis can be generalized to GNNs under various learning paradigms, which provides further insights to emphasize the research significance of shallow embedding methods. Finally, with these insights, we conclude with a guide to meet various needs of researchers and practitioners.
- KDD
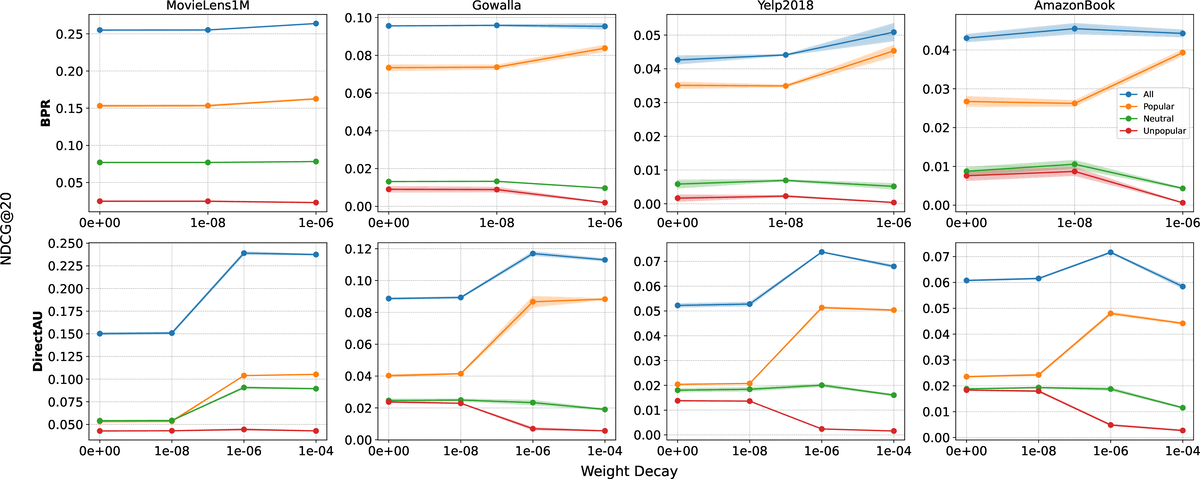 On the Role of Weight Decay in Collaborative Filtering: A Popularity PerspectiveDonald Loveland, Mingxuan Ju, Tong Zhao, Neil Shah, and Danai KoutraIn ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2025
On the Role of Weight Decay in Collaborative Filtering: A Popularity PerspectiveDonald Loveland, Mingxuan Ju, Tong Zhao, Neil Shah, and Danai KoutraIn ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2025Collaborative filtering (CF) enables large-scale recommendation systems by encoding information from historical user-item interactions into dense ID-embedding tables. However, as embedding tables grow, closed-form solutions become impractical, often necessitating the use of mini-batch gradient descent for training. Despite extensive work on designing loss functions to train CF models, we argue that one core component of these pipelines is heavily overlooked: weight decay. Attaining high-performing models typically requires careful tuning of weight decay, regardless of loss, yet its necessity is not well understood. In this work, we question why weight decay is crucial in CF pipelines and how it impacts training. Through theoretical and empirical analysis, we surprisingly uncover that weight decay’s primary function is to encode popularity information into the magnitudes of the embedding vectors. Moreover, we find that tuning weight decay acts as a coarse, non-linear knob to influence preference towards popular or unpopular items. Based on these findings, we propose PRISM (Popularity-awaRe Initialization Strategy for embedding Magnitudes), a straightforward yet effective solution to simplify the training of high-performing CF models. PRISM pre-encodes the popularity information typically learned through weight decay, eliminating its necessity. Our experiments show that PRISM improves performance by up to 4.77% and reduces training times by 38.48%, compared to state-of-the-art training strategies. Additionally, we parameterize PRISM to modulate the initialization strength, offering a cost-effective and meaningful strategy to mitigate popularity bias.
- KDD
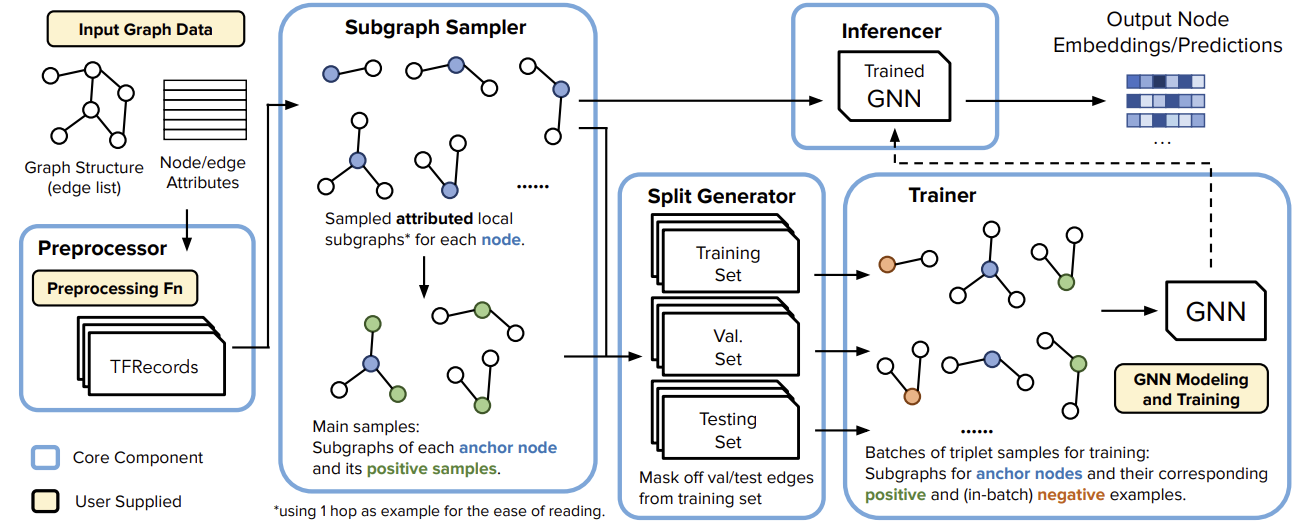 GiGL: Large-Scale Graph Neural Networks at SnapchatTong Zhao, Yozen Liu, Matthew Kolodner, Kyle Montemayor, Elham Ghazizadeh, Ankit Batra, Zihao Fan, Xiaobin Gao, and 7 more authorsIn ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2025
GiGL: Large-Scale Graph Neural Networks at SnapchatTong Zhao, Yozen Liu, Matthew Kolodner, Kyle Montemayor, Elham Ghazizadeh, Ankit Batra, Zihao Fan, Xiaobin Gao, and 7 more authorsIn ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2025Recent advances in graph machine learning (ML) with the introduction of Graph Neural Networks (GNNs) have led to a widespread interest in applying these approaches to business applications at scale. GNNs enable differentiable end-to-end (E2E) learning of model parameters given graph structure which enables optimization towards popular node, edge (link) and graph-level tasks. While the research innovation in new GNN layers and training strategies has been rapid, industrial adoption and utility of GNNs has lagged considerably due to the unique scale challenges that large-scale graph ML problems create. In this work, we share our approach to training, inference, and utilization of GNNs at Snapchat. To this end, we present GiGL (Gigantic Graph Learning), an open-source library to enable large-scale distributed graph ML to the benefit of researchers, ML engineers, and practitioners. We use GiGL internally at Snapchat to manage the heavy lifting of GNN workflows, including graph data preprocessing from relational DBs, subgraph sampling, distributed training, inference, and orchestration. GiGL is designed to interface cleanly with open-source GNN modeling libraries prominent in academia like PyTorch Geometric (PyG), while handling scaling and productionization challenges that make it easier for internal practitioners to focus on modeling. GiGL is used in multiple production settings, and has powered over 35 launches across multiple business domains in the last 2 years in the contexts of friend recommendation, content recommendation and advertising. This work details high-level design and tools the library provides, scaling properties, case studies in diverse business settings with industry-scale graphs, and several key lessons learned in employing graph ML at scale on large social data. GiGL is open-sourced at https://github.com/Snapchat/GiGL.
- KDD
 Training Industry-Scale Graph Neural Networks with GiGLYozen Liu, Tong Zhao, Matthew Kolodner, Kyle Montemayor, Shubham Vij, and Neil ShahIn ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2025
Training Industry-Scale Graph Neural Networks with GiGLYozen Liu, Tong Zhao, Matthew Kolodner, Kyle Montemayor, Shubham Vij, and Neil ShahIn ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2025Recent advances in graph machine learning (GML) and Graph Neu- ral Networks (GNNs) have sparked significant practical interest given the ability to model complex relationships between entities. Despite rapid progress in GNN designs, scalability remains a major challenge. Industry applications require solutions that can handle graphs with billions of nodes and edges efficiently. GiGL (Gigantic Graph Learning) is an open-source library from Snapchat, designed for large-scale distributed training and inference with GNNs. It seamlessly integrates with popular open-source GNN libraries like PyTorch Geometric (PyG). GiGL provides simplified configurable interfaces with minimal modeling code requirements, providing in- dustrial practitioners a straightforward way to apply GNNs to large- scale applications and enabling academics to conduct large-scale experiments. At the same time, it enables complex modeling capabil- ities desirable for modeling iteration. In this hands-on tutorial, we will demonstrate how GiGL addresses the scalability challenge in GNNs and provide a step-by-step guide for attendees to complete end-to-end training and inference with GiGL on industry-scale graphs. By the end of our tutorial, participants will have hands-on experience in training GNNs on graphs with billions of nodes and edges - capabilities not easily achievable with open-source graph learning libraries like PyG alone. We anticipate strong interest and participation from both industrial practitioners working on GNN applications and academics conducting large-scale experiments.
- KDD
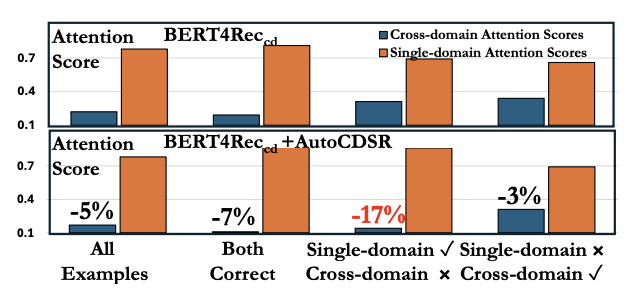 Revisiting Self-Attention for Cross-Domain Sequential RecommendationMingxuan Ju, Leonardo Neves, Bhuvesh Kumar, Liam Collins, Tong Zhao, Yuwei Qiu, Qing Dou, Sohail Nizam, and 2 more authorsIn ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2025
Revisiting Self-Attention for Cross-Domain Sequential RecommendationMingxuan Ju, Leonardo Neves, Bhuvesh Kumar, Liam Collins, Tong Zhao, Yuwei Qiu, Qing Dou, Sohail Nizam, and 2 more authorsIn ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2025Sequential recommendation is a popular paradigm in modern recommender systems. In particular, one challenging problem in this space is cross-domain sequential recommendation (CDSR), which aims to predict future behaviors given user interactions across multiple domains. Existing CDSR frameworks are mostly built on the self-attention transformer and seek to improve by explicitly injecting additional domain-specific components (e.g. domain-aware module blocks). While these additional components help, we argue they overlook the core self-attention module already present in the transformer, a naturally powerful tool to learn correlations among behaviors. In this work, we aim to improve the CDSR performance for simple models from a novel perspective of enhancing the self-attention. Specifically, we introduce a Pareto-optimal self-attention and formulate the cross-domain learning as a multi-objective problem, where we optimize the recommendation task while dynamically minimizing the cross-domain attention scores. Our approach automates knowledge transfer in CDSR (dubbed as AutoCDSR) – it not only mitigates negative transfer but also encourages complementary knowledge exchange among auxiliary domains. Based on the idea, we further introduce AutoCDSR+, a more performant variant with slight additional cost. Our proposal is easy to implement and works as a plug-and-play module that can be incorporated into existing transformer-based recommenders. Besides flexibility, it is practical to deploy because it brings little extra computational overheads without heavy hyper-parameter tuning. AutoCDSR on average improves Recall@10 for SASRec and Bert4Rec by 9.8% and 16.0% and NDCG@10 by 12.0% and 16.7%, respectively. Code is available at https://github.com/snap-research/AutoCDSR.
- preprint
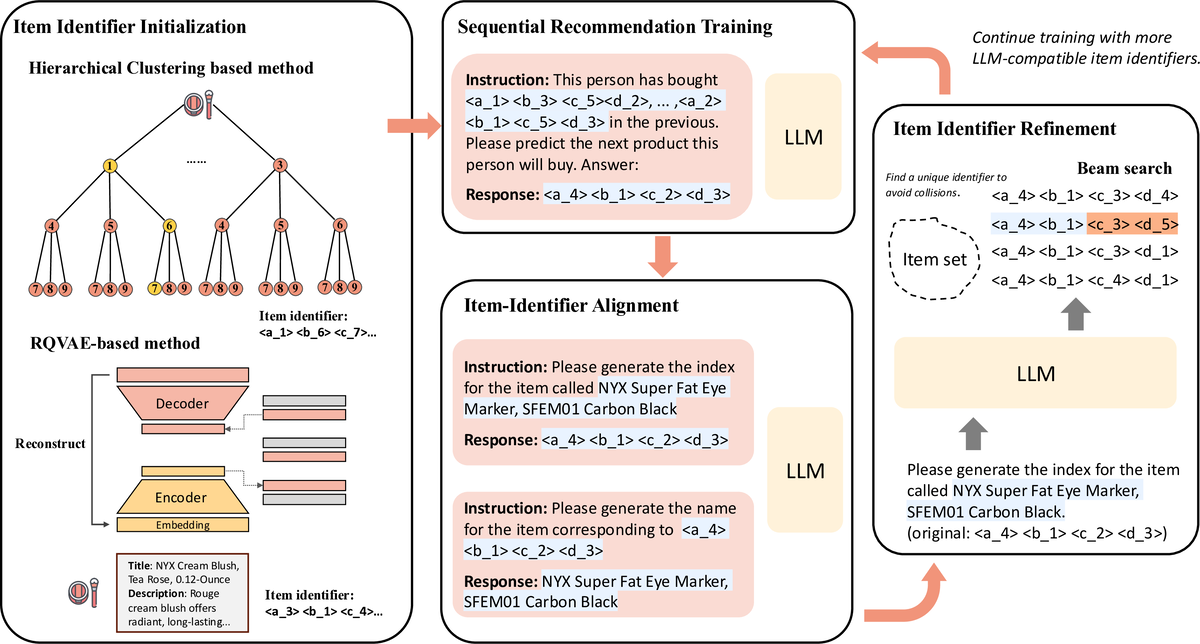 Enhancing Item Tokenization for Generative Recommendation through Self-ImprovementRunjin Chen, Mingxuan Ju, Ngoc Bui, Dimosthenis Antypas, Stanley Cai, Xiaopeng Wu, Leonardo Neves, Zhangyang Wang, and 2 more authorsarXiv preprint, 2025
Enhancing Item Tokenization for Generative Recommendation through Self-ImprovementRunjin Chen, Mingxuan Ju, Ngoc Bui, Dimosthenis Antypas, Stanley Cai, Xiaopeng Wu, Leonardo Neves, Zhangyang Wang, and 2 more authorsarXiv preprint, 2025Generative recommendation systems, driven by large language models (LLMs), present an innovative approach to predicting user preferences by modeling items as token sequences and generating recommendations in a generative manner. A critical challenge in this approach is the effective tokenization of items, ensuring that they are represented in a form compatible with LLMs. Current item tokenization methods include using text descriptions, numerical strings, or sequences of discrete tokens. While text-based representations integrate seamlessly with LLM tokenization, they are often too lengthy, leading to inefficiencies and complicating accurate generation. Numerical strings, while concise, lack semantic depth and fail to capture meaningful item relationships. Tokenizing items as sequences of newly defined tokens has gained traction, but it often requires external models or algorithms for token assignment. These external processes may not align with the LLM’s internal pretrained tokenization schema, leading to inconsistencies and reduced model performance. To address these limitations, we propose a self-improving item tokenization method that allows the LLM to refine its own item tokenizations during training process. Our approach starts with item tokenizations generated by any external model and periodically adjusts these tokenizations based on the LLM’s learned patterns. Such alignment process ensures consistency between the tokenization and the LLM’s internal understanding of the items, leading to more accurate recommendations. Furthermore, our method is simple to implement and can be integrated as a plug-and-play enhancement into existing generative recommendation systems. Experimental results on multiple datasets and using various initial tokenization strategies demonstrate the effectiveness of our method, with an average improvement of 8% in recommendation performance.
- SIRIP
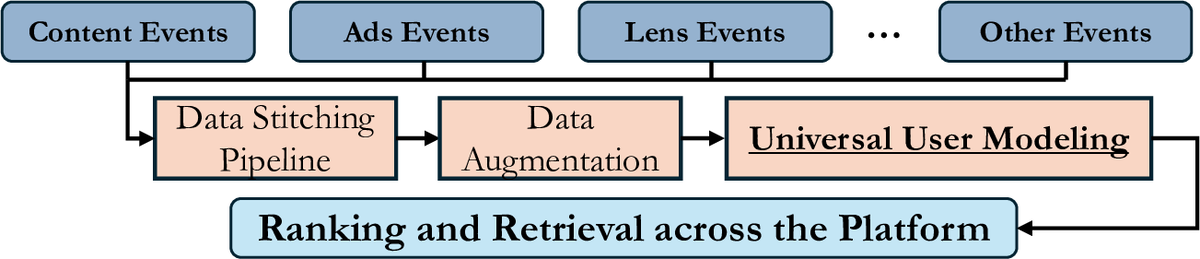 Learning Universal User Representations Leveraging Cross-domain User Intent at SnapchatMingxuan Ju, Leonardo Neves, Bhuvesh Kumar, Liam Collins, Tong Zhao, Yuwei Qiu, Ching Dou, Yang Zhou, and 6 more authorsIn ACM SIGIR Conference on Research and Development in Information Retrieval, 2025
Learning Universal User Representations Leveraging Cross-domain User Intent at SnapchatMingxuan Ju, Leonardo Neves, Bhuvesh Kumar, Liam Collins, Tong Zhao, Yuwei Qiu, Ching Dou, Yang Zhou, and 6 more authorsIn ACM SIGIR Conference on Research and Development in Information Retrieval, 2025The development of powerful user representations is a key factor in the success of recommender systems (RecSys). Online platforms employ a range of RecSys techniques to personalize user experience across diverse in-app surfaces. User representations are often learned individually through user’s historical interactions within each surface and user representations across different surfaces can be shared post-hoc as auxiliary features or additional retrieval sources. While effective, such schemes cannot directly encode collaborative filtering signals across different surfaces, hindering its capacity to discover complex relationships between user behaviors and preferences across the whole platform. To bridge this gap at Snapchat, we seek to conduct universal user modeling (UUM) across different in-app surfaces, learning general-purpose user representations which encode behaviors across surfaces. Instead of replacing domain-specific representations, UUM representations capture cross-domain trends, enriching existing representations with complementary information. This work discusses our efforts in developing initial UUM versions, practical challenges, technical choices and modeling and research directions with promising offline performance. Following successful A/B testing, UUM representations have been launched in production, powering multiple use cases and demonstrating their value. UUM embedding has been incorporated into (i) Long-form Video embedding-based retrieval, leading to 2.78% increase in Long-form Video Open Rate, (ii) Long-form Video L2 ranking, with 19.2% increase in Long-form Video View Time sum, (iii) Lens L2 ranking, leading to 1.76% increase in Lens play time, and (iv) Notification L2 ranking, with 0.87% increase in Notification Open Rate.
- ICML
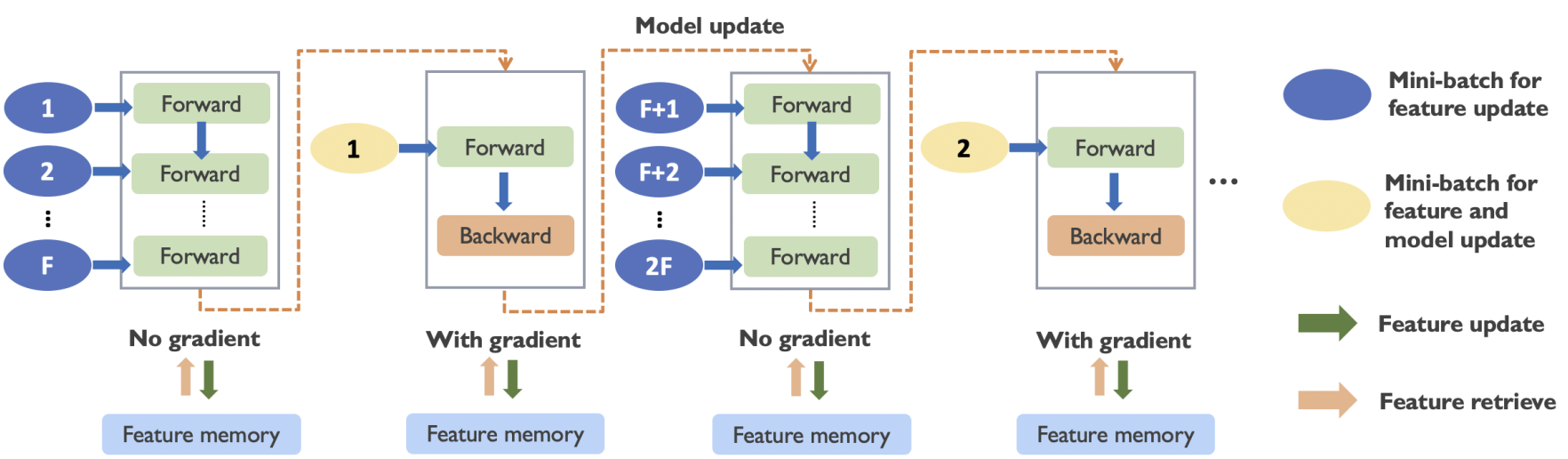 Haste Makes Waste: A Simple Approach for Scaling Graph Neural NetworksRui Xue, Tong Zhao, Neil Shah, and Xiaorui LiuIn International Conference on Machine Learning, 2025
Haste Makes Waste: A Simple Approach for Scaling Graph Neural NetworksRui Xue, Tong Zhao, Neil Shah, and Xiaorui LiuIn International Conference on Machine Learning, 2025Graph neural networks (GNNs) have demonstrated remarkable success in graph representation learning, and various sampling approaches have been proposed to scale GNNs to applications with large-scale graphs. A class of promising GNN training algorithms take advantage of historical embeddings to reduce the computation and memory cost while maintaining the model expressiveness of GNNs. However, they incur significant computation bias due to the stale feature history. In this paper, we provide a comprehensive analysis of their staleness and inferior performance on large-scale problems. Motivated by our discoveries, we propose a simple yet highly effective training algorithm (REST) to effectively reduce feature staleness, which leads to significantly improved performance and convergence across varying batch sizes. The proposed algorithm seamlessly integrates with existing solutions, boasting easy implementation, while comprehensive experiments underscore its superior performance and efficiency on large-scale benchmarks. Specifically, our improvements to state-of-the-art historical embedding methods result in a 2.7% and 3.6% performance enhancement on the ogbn-papers100M and ogbn-products dataset respectively, accompanied by notably accelerated convergence.
- ICML
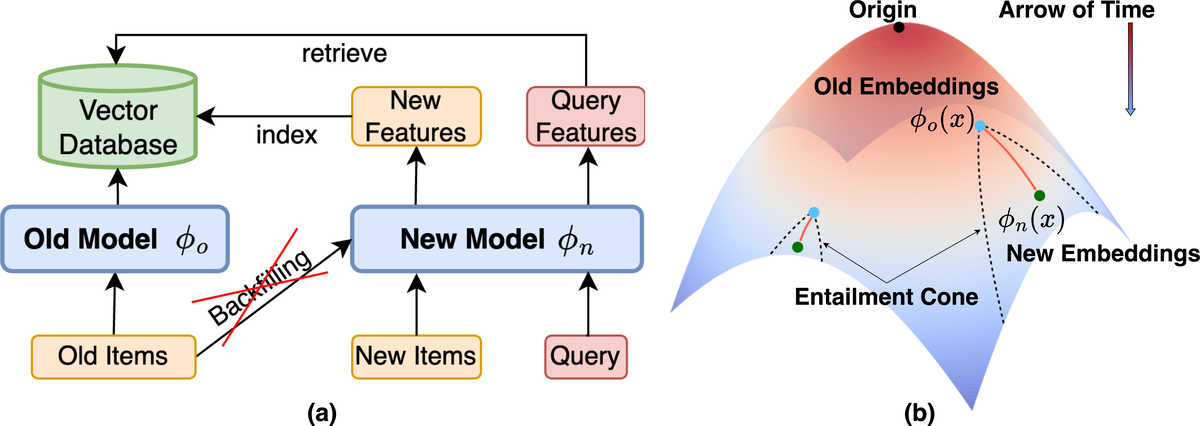 Hyperbolic Geometry for Backward-Compatible Representation LearningNgoc Bui, Menglin Yang, Runjin Chen, Leonardo Neves, Clark Ju, Rex Ying, Neil Shah, and Tong ZhaoIn International Conference on Machine Learning, 2025
Hyperbolic Geometry for Backward-Compatible Representation LearningNgoc Bui, Menglin Yang, Runjin Chen, Leonardo Neves, Clark Ju, Rex Ying, Neil Shah, and Tong ZhaoIn International Conference on Machine Learning, 2025Backward compatible representation learning enables updated models to integrate seamlessly with existing ones, avoiding to reprocess stored data. Despite recent advances, existing compatibility approaches in Euclidean space neglect the uncertainty in the old embedding model and force the new model to reconstruct outdated representations regardless of their quality, thereby hindering the learning process of the new model. In this paper, we propose to switch perspectives to hyperbolic geometry, where we treat time as a natural axis for capturing a model’s confidence and evolution. By lifting embeddings into hyperbolic space and constraining updated embeddings to lie within the entailment cone of the old ones, we maintain generational consistency across models while accounting for uncertainties in the representations. To further enhance compatibility, we introduce a robust contrastive alignment loss that dynamically adjusts alignment weights based on the uncertainty of the old embeddings. Experiments validate the superiority of the proposed method in achieving compatibility, paving the way for more resilient and adaptable machine learning systems.
- TheWebConf
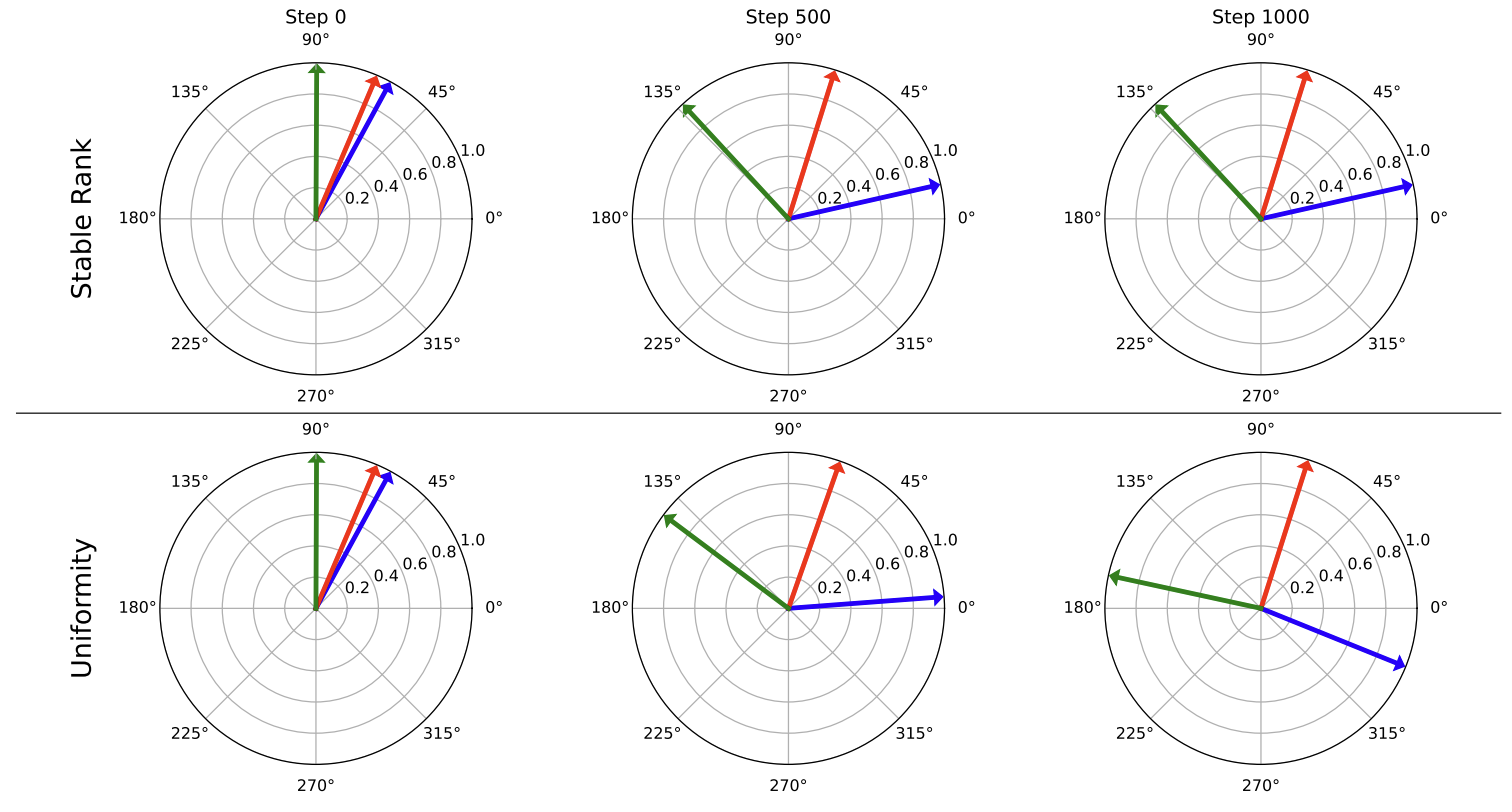 Understanding and Scaling Collaborative Filtering Optimization from the Perspective of Matrix RankDonald Loveland, Xinyi Wu, Tong Zhao, Danai Koutra, Neil Shah, and Mingxuan JuIn The Web Conference, 2025
Understanding and Scaling Collaborative Filtering Optimization from the Perspective of Matrix RankDonald Loveland, Xinyi Wu, Tong Zhao, Danai Koutra, Neil Shah, and Mingxuan JuIn The Web Conference, 2025Collaborative Filtering (CF) methods dominate real-world recommender systems given their ability to learn high-quality, sparse ID-embedding tables that effectively capture user preferences. These tables scale linearly with the number of users and items, and are trained to ensure high similarity between embeddings of interacted user-item pairs, while maintaining low similarity for non-interacted pairs. Despite their high performance, encouraging dispersion for non-interacted pairs necessitates expensive regularization (e.g., negative sampling), hurting runtime and scalability. Existing research tends to address these challenges by simplifying the learning process, either by reducing model complexity or sampling data, trading performance for runtime. In this work, we move beyond model-level modifications and study the properties of the embedding tables under different learning strategies. Through theoretical analysis, we find that the singular values of the embedding tables are intrinsically linked to different CF loss functions. These findings are empirically validated on real-world datasets, demonstrating the practical benefits of higher stable rank, a continuous version of matrix rank which encodes the distribution of singular values. Based on these insights, we propose an efficient warm-start strategy that regularizes the stable rank of the user and item embeddings. We show that stable rank regularization during early training phases can promote higher-quality embeddings, resulting in training speed improvements of up to 66%. Additionally, stable rank regularization can act as a proxy for negative sampling, allowing for performance gains of up to 21% over loss functions with small negative sampling ratios. Overall, our analysis unifies current CF methods under a new perspective, their optimization of stable rank, motivating a flexible regularization method.
- TheWebConf
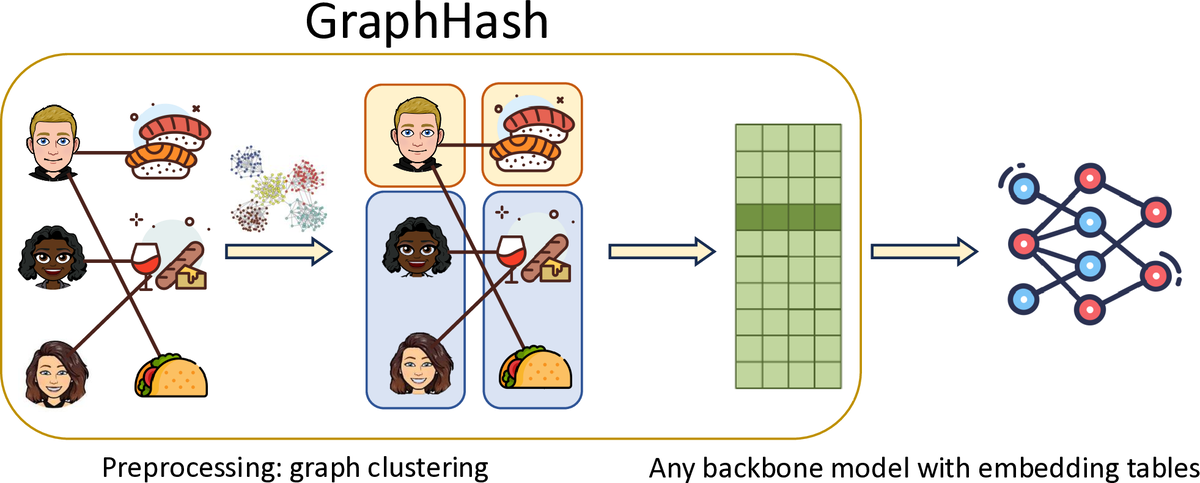 GraphHash: Graph Clustering Enables Parameter Efficiency in Recommender SystemsXinyi Wu, Donald Loveland, Runjin Chen, Yozen Liu, Xin Chen, Leonardo Neves, Ali Jadbabaie, Mingxuan Ju, and 2 more authorsIn The Web Conference, 2025
GraphHash: Graph Clustering Enables Parameter Efficiency in Recommender SystemsXinyi Wu, Donald Loveland, Runjin Chen, Yozen Liu, Xin Chen, Leonardo Neves, Ali Jadbabaie, Mingxuan Ju, and 2 more authorsIn The Web Conference, 2025Deep recommender systems rely heavily on large embedding tables to handle high-cardinality categorical features such as user/item identifiers, and face significant memory constraints at scale. To tackle this challenge, hashing techniques are often employed to map multiple entities to the same embedding and thus reduce the size of the embedding tables. Concurrently, graph-based collaborative signals have emerged as powerful tools in recommender systems, yet their potential for optimizing embedding table reduction remains unexplored. This paper introduces GraphHash, the first graph-based approach that leverages modularity-based bipartite graph clustering on user-item interaction graphs to reduce embedding table sizes. We demonstrate that the modularity objective has a theoretical connection to message-passing, which provides a foundation for our method. By employing fast clustering algorithms, GraphHash serves as a computationally efficient proxy for message-passing during preprocessing and a plug-and-play graph-based alternative to traditional ID hashing. Extensive experiments show that GraphHash substantially outperforms diverse hashing baselines on both retrieval and click-through-rate prediction tasks. In particular, GraphHash achieves on average a 101.52% improvement in recall when reducing the embedding table size by more than 75%, highlighting the value of graph-based collaborative information for model reduction. Our code is available at https://github.com/snap-research/GraphHash.
- CVPR
 Mosaic of Modalities: A Comprehensive Benchmark for Multimodal Graph LearningJing Zhu, Yuhang Zhou, Shengyi Qian, Zhongmou He, Tong Zhao, Neil Shah, and Danai KoutraIn Conference on Computer Vision and Pattern Recognition, 2025
Mosaic of Modalities: A Comprehensive Benchmark for Multimodal Graph LearningJing Zhu, Yuhang Zhou, Shengyi Qian, Zhongmou He, Tong Zhao, Neil Shah, and Danai KoutraIn Conference on Computer Vision and Pattern Recognition, 2025Graph machine learning has made significant strides in recent years, yet the integration of visual information with graph structure and its potential for improving performance in downstream tasks remains an underexplored area. To address this critical gap, we introduce the Multimodal Graph Benchmark (MM-GRAPH), a pioneering benchmark that incorporates both visual and textual information into graph learning tasks. MM-GRAPH extends beyond existing text-attributed graph benchmarks, offering a more comprehensive evaluation framework for multimodal graph learning Our benchmark comprises seven diverse datasets of varying scales (ranging from thousands to millions of edges), designed to assess algorithms across different tasks in real-world scenarios. These datasets feature rich multimodal node attributes, including visual data, which enables a more holistic evaluation of various graph learning frameworks in complex, multimodal environments. To support advancements in this emerging field, we provide an extensive empirical study on various graph learning frameworks when presented with features from multiple modalities, particularly emphasizing the impact of visual information. This study offers valuable insights into the challenges and opportunities of integrating visual data into graph learning.
- preprint
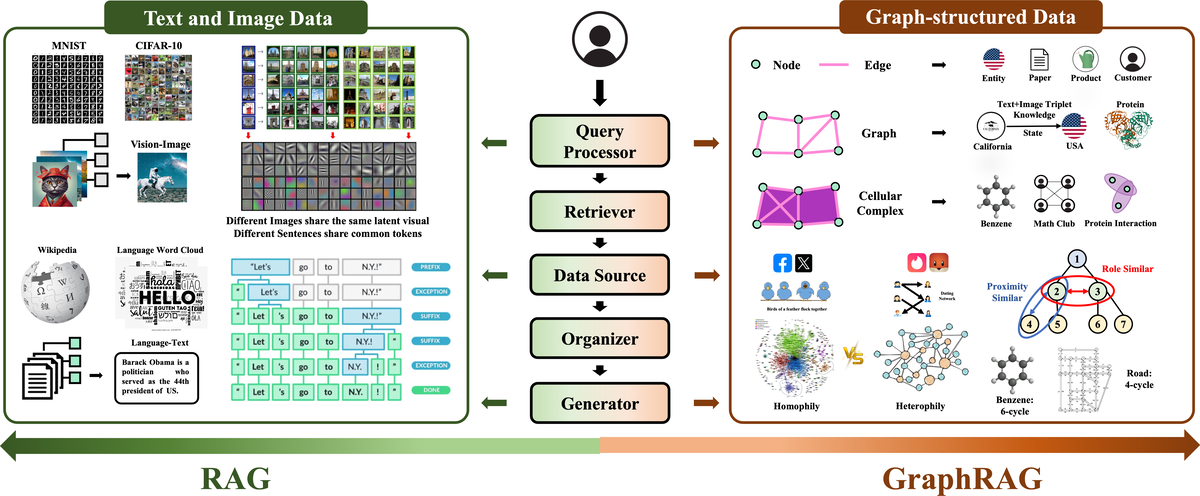 Retrieval-Augmented Generation with Graphs (GraphRAG)Haoyu Han, Yu Wang, Harry Shomer, Kai Guo, Jiayuan Ding, Yongjia Lei, Mahantesh Halappanavar, Ryan A. Rossi, and 10 more authorsarXiv preprint, 2025
Retrieval-Augmented Generation with Graphs (GraphRAG)Haoyu Han, Yu Wang, Harry Shomer, Kai Guo, Jiayuan Ding, Yongjia Lei, Mahantesh Halappanavar, Ryan A. Rossi, and 10 more authorsarXiv preprint, 2025Retrieval-augmented generation (RAG) is a powerful technique that enhances downstream task execution by retrieving additional information, such as knowledge, skills, and tools from external sources. Graph, by its intrinsic "nodes connected by edges" nature, encodes massive heterogeneous and relational information, making it a golden resource for RAG in tremendous real-world applications. As a result, we have recently witnessed increasing attention on equipping RAG with Graph, i.e., GraphRAG. However, unlike conventional RAG, where the retriever, generator, and external data sources can be uniformly designed in the neural-embedding space, the uniqueness of graph-structured data, such as diverse-formatted and domain-specific relational knowledge, poses unique and significant challenges when designing GraphRAG for different domains. Given the broad applicability, the associated design challenges, and the recent surge in GraphRAG, a systematic and up-to-date survey of its key concepts and techniques is urgently desired. Following this motivation, we present a comprehensive and up-to-date survey on GraphRAG. Our survey first proposes a holistic GraphRAG framework by defining its key components, including query processor, retriever, organizer, generator, and data source. Furthermore, recognizing that graphs in different domains exhibit distinct relational patterns and require dedicated designs, we review GraphRAG techniques uniquely tailored to each domain. Finally, we discuss research challenges and brainstorm directions to inspire cross-disciplinary opportunities. Our survey repository is publicly maintained at https://github.com/Graph-RAG/GraphRAG/.
- TheWebConf
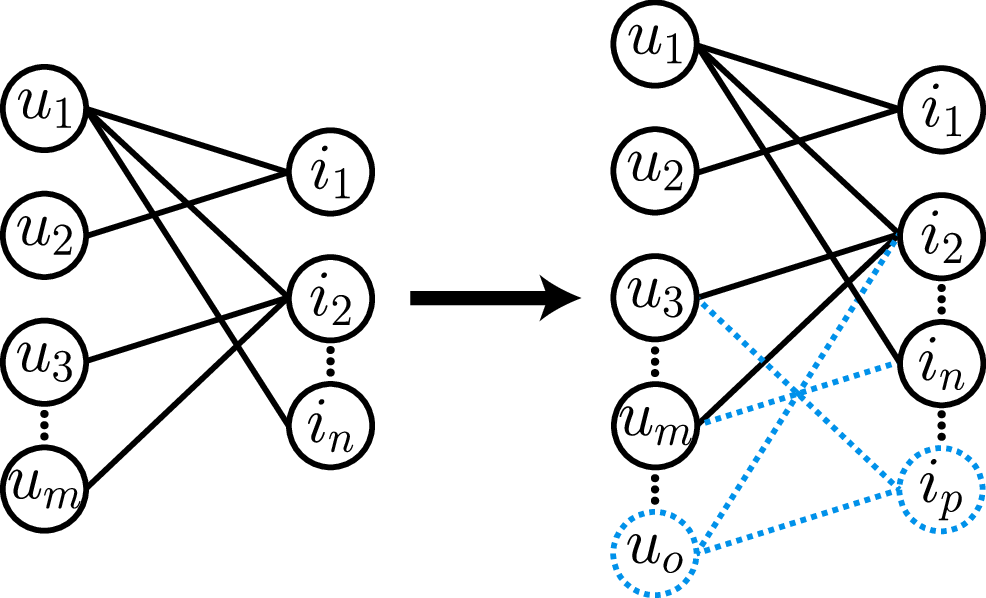 Improving Out-of-Vocabulary Handling in Recommendation SystemsWilliam Shiao, Mingxuan Ju, Zhichun Guo, Xin Chen, Evangelos Papalexakis, Tong Zhao, Neil Shah, and Yozen LiuIn Resource Efficient Learning Workshop at The Web Conference, 2025
Improving Out-of-Vocabulary Handling in Recommendation SystemsWilliam Shiao, Mingxuan Ju, Zhichun Guo, Xin Chen, Evangelos Papalexakis, Tong Zhao, Neil Shah, and Yozen LiuIn Resource Efficient Learning Workshop at The Web Conference, 2025Recommendation systems (RS) are an increasingly relevant area for both academic and industry researchers, given their widespread impact on the daily online experiences of billions of users. One common issue in real RS is the cold-start problem, where users and items may not contain enough information to produce high-quality recommendations. This work focuses on a complementary problem: recommending new users and items unseen (out-of-vocabulary, or OOV) at training time. This setting is known as the inductive setting and is especially problematic for factorization-based models, which rely on encoding only those users/items seen at training time with fixed parameter vectors. Many existing solutions applied in practice are often naive, such as assigning OOV users/items to random buckets. In this work, we tackle this problem and propose approaches that better leverage available user/item features to improve OOV handling at the embedding table level. We discuss general-purpose plug-and-play approaches that are easily applicable to most RS models and improve inductive performance without negatively impacting transductive model performance. We extensively evaluate 9 OOV embedding methods on 5 models across 4 datasets (spanning different domains). One of these datasets is a proprietary production dataset from a prominent RS employed by a large social platform serving hundreds of millions of daily active users. In our experiments, we find that several proposed methods that exploit feature similarity using LSH consistently outperform alternatives on most model-dataset combinations, with the best method showing a mean improvement of 3.74% over the industry standard baseline in inductive performance. We release our code and hope our work helps practitioners make more informed decisions when handling OOV for their RS and further inspires academic research into improving OOV support in RS.
2024
- LoG
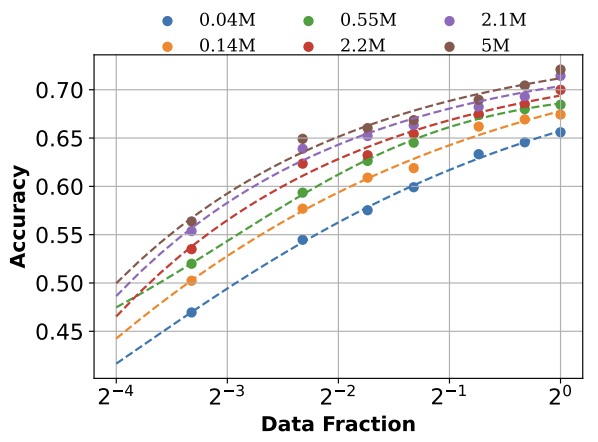 Towards Neural Scaling Laws on GraphsJingzhe Liu, Haitao Mao, Zhikai Chen, Tong Zhao, Neil Shah, and Jiliang TangIn Learning on Graphs Conference, 2024
Towards Neural Scaling Laws on GraphsJingzhe Liu, Haitao Mao, Zhikai Chen, Tong Zhao, Neil Shah, and Jiliang TangIn Learning on Graphs Conference, 2024Deep graph models (e.g., graph neural networks and graph transformers) have become important techniques for leveraging knowledge across various types of graphs. Yet, the neural scaling laws on graphs, i.e., how the performance of deep graph models changes with model and dataset sizes, have not been systematically investigated, casting doubts on the feasibility of achieving large graph models. To fill this gap, we benchmark many graph datasets from different tasks and make an attempt to establish the neural scaling laws on graphs from both model and data perspectives. The model size we investigated is up to 100 million parameters, and the dataset size investigated is up to 50 million samples. We first verify the validity of such laws on graphs, establishing proper formulations to describe the scaling behaviors. For model scaling, we identify that despite the parameter numbers, the model depth also plays an important role in affecting the model scaling behaviors, which differs from observations in other domains such as CV and NLP. For data scaling, we suggest that the number of graphs can not effectively measure the graph data volume in scaling law since the sizes of different graphs are highly irregular. Instead, we reform the data scaling law with the number of nodes or edges as the metric to address the irregular graph sizes. We further demonstrate that the reformed law offers a unified view of the data scaling behaviors for various fundamental graph tasks including node classification, link prediction, and graph classification. This work provides valuable insights into neural scaling laws on graphs, which can serve as an important tool for collecting new graph data and developing large graph models.
- NeurIPS
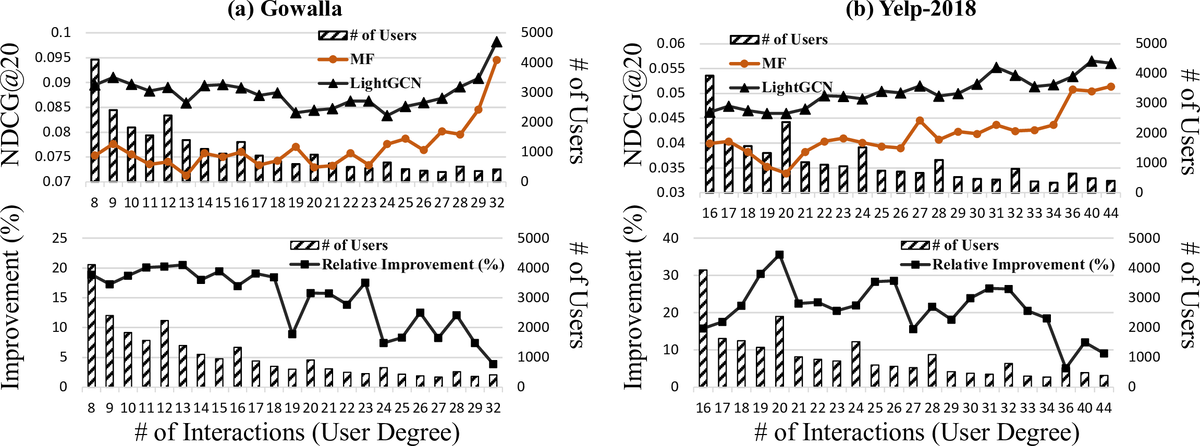 Test-time Aggregation for Collaborative FilteringMingxuan Ju, William Shiao, Zhichun Guo, Yanfang Ye, Yozen Liu, Neil Shah, and Tong ZhaoIn Conference on Neural Information Processing Systems, 2024
Test-time Aggregation for Collaborative FilteringMingxuan Ju, William Shiao, Zhichun Guo, Yanfang Ye, Yozen Liu, Neil Shah, and Tong ZhaoIn Conference on Neural Information Processing Systems, 2024Collaborative filtering (CF) has exhibited prominent results for recommender systems and been broadly utilized for real-world applications. A branch of research enhances CF methods by message passing used in graph neural networks, due to its strong capabilities of extracting knowledge from graph-structured data, like user-item bipartite graphs that naturally exist in CF. They assume that message passing helps CF methods in a manner akin to its benefits for graph-based learning tasks in general. However, even though message passing empirically improves CF, whether or not this assumption is correct still needs verification. To address this gap, we formally investigate why message passing helps CF from multiple perspectives and show that many assumptions made by previous works are not entirely accurate. With our curated ablation studies and theoretical analyses, we discover that (1) message passing improves the CF performance primarily by additional representations passed from neighbors during the forward pass instead of additional gradient updates to neighbor representations during the model back-propagation and (ii) message passing usually helps low-degree nodes more than high-degree nodes. Utilizing these novel findings, we present Test-time Aggregation for CF, namely TAG-CF, a test-time augmentation framework that only conducts message passing once at inference time. The key novelty of TAG-CF is that it effectively utilizes graph knowledge while circumventing most of notorious computational overheads of message passing. Besides, TAG-CF is extremely versatile can be used as a plug-and-play module to enhance representations trained by different CF supervision signals. Evaluated on six datasets, TAG-CF consistently improves the recommendation performance of CF methods without graph by up to 39.2% on cold users and 31.7% on all users, with little to no extra computational overheads.
- RecSys
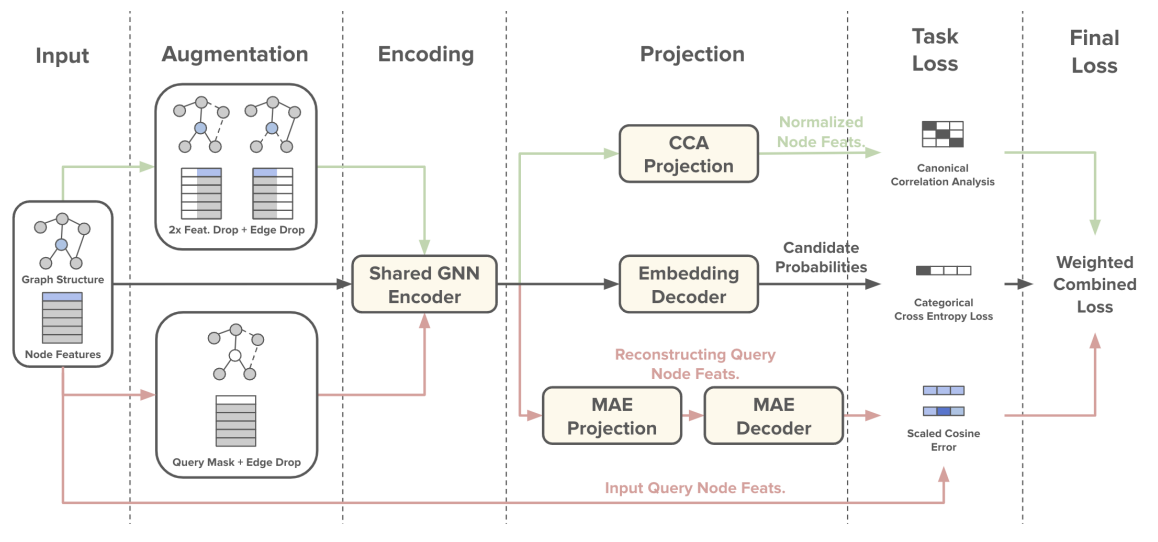 Robust Training Objectives Improve Embedding-based Retrieval in Industrial Recommendation SystemsMatthew Kolodner, Mingxuan Ju, Zihao Fan, Tong Zhao, Elham Ghazizadeh, Yan Wu, Neil Shah, and Yozen LiuIn RobustRecSys Workshop @ ACM Conference on Recommender Systems, 2024
Robust Training Objectives Improve Embedding-based Retrieval in Industrial Recommendation SystemsMatthew Kolodner, Mingxuan Ju, Zihao Fan, Tong Zhao, Elham Ghazizadeh, Yan Wu, Neil Shah, and Yozen LiuIn RobustRecSys Workshop @ ACM Conference on Recommender Systems, 2024Graph Foundation Models (GFMs) are emerging as a significant research topic in the graph domain, aiming to develop graph models trained on extensive and diverse data to enhance their applicability across various tasks and domains. Developing GFMs presents unique challenges over traditional Graph Neural Networks (GNNs), which are typically trained from scratch for specific tasks on particular datasets. The primary challenge in constructing GFMs lies in effectively leveraging vast and diverse graph data to achieve positive transfer. Drawing inspiration from existing foundation models in the CV and NLP domains, we propose a novel perspective for the GFM development by advocating for a “graph vocabulary”, in which the basic transferable units underlying graphs encode the invariance on graphs. We ground the graph vocabulary construction from essential aspects including network analysis, expressiveness, and stability. Such a vocabulary perspective can potentially advance the future GFM design in line with the neural scaling laws. All relevant resources with GFM design can be found here.
- ICML
 Graph Foundation ModelsHaitao Mao, Zhikai Chen, Wenzhuo Tang, Jianan Zhao, Yao Ma, Tong Zhao, Neil Shah, Mikhail Galkin, and 1 more authorIn International Conference on Machine Learning, 2024
Graph Foundation ModelsHaitao Mao, Zhikai Chen, Wenzhuo Tang, Jianan Zhao, Yao Ma, Tong Zhao, Neil Shah, Mikhail Galkin, and 1 more authorIn International Conference on Machine Learning, 2024Graph Foundation Models (GFMs) are emerging as a significant research topic in the graph domain, aiming to develop graph models trained on extensive and diverse data to enhance their applicability across various tasks and domains. Developing GFMs presents unique challenges over traditional Graph Neural Networks (GNNs), which are typically trained from scratch for specific tasks on particular datasets. The primary challenge in constructing GFMs lies in effectively leveraging vast and diverse graph data to achieve positive transfer. Drawing inspiration from existing foundation models in the CV and NLP domains, we propose a novel perspective for the GFM development by advocating for a “graph vocabulary”, in which the basic transferable units underlying graphs encode the invariance on graphs. We ground the graph vocabulary construction from essential aspects including network analysis, expressiveness, and stability. Such a vocabulary perspective can potentially advance the future GFM design in line with the neural scaling laws. All relevant resources with GFM design can be found here.
- ICML
 LLaGA: Large Language and Graph AssistantRunjin Chen, Tong Zhao, Ajay Kumar Jaiswal, Neil Shah, and Zhangyang WangIn International Conference on Machine Learning, 2024
LLaGA: Large Language and Graph AssistantRunjin Chen, Tong Zhao, Ajay Kumar Jaiswal, Neil Shah, and Zhangyang WangIn International Conference on Machine Learning, 2024Graph Neural Networks (GNNs) have empowered the advance in graph-structured data analysis. Recently, the rise of Large Language Models (LLMs) like GPT-4 has heralded a new era in deep learning. However, their application to graph data poses distinct challenges due to the inherent difficulty of translating graph structures to language. To this end, we introduce the Large Language and Graph Assistant (LLaGA), an innovative model that effectively integrates LLM capabilities to handle the complexities of graph-structured data. LLaGA retains the general-purpose nature of LLMs while adapting graph data into a format compatible with LLM input. LLaGA achieves this by reorganizing graph nodes to structure-aware sequences and then mapping these into the token embedding space through a versatile projector. LLaGA excels in versatility, generalizability and interpretability, allowing it to perform consistently well across different datasets and tasks, extend its ability to unseen datasets or tasks, and provide explanations for graphs. Our extensive experiments across popular graph benchmarks show that LLaGA delivers outstanding performance across four datasets and three tasks using one single model, surpassing state-of-the-art graph models in both supervised and zero-shot scenarios. Our code is available at \url{https://github.com/VITA-Group/LLaGA}.
- ACL
 Explainability and Hate Speech: Structured Explanations Make Social Media Moderators FasterAgostina Calabrese, Leonardo Neves, Neil Shah, Maarten Bos, Björn Ross, Mirella Lapata, and Francesco BarbieriIn Annual Meeting of the Association for Computational Linguistics, 2024
Explainability and Hate Speech: Structured Explanations Make Social Media Moderators FasterAgostina Calabrese, Leonardo Neves, Neil Shah, Maarten Bos, Björn Ross, Mirella Lapata, and Francesco BarbieriIn Annual Meeting of the Association for Computational Linguistics, 2024Content moderators play a key role in keeping the conversation on social media healthy. While the high volume of content they need to judge represents a bottleneck to the moderation pipeline, no studies have explored how models could support them to make faster decisions. There is, by now, a vast body of research into detecting hate speech, sometimes explicitly motivated by a desire to help improve content moderation, but published research using real content moderators is scarce. In this work we investigate the effect of explanations on the speed of real-world moderators. Our experiments show that while generic explanations do not affect their speed and are often ignored, structured explanations lower moderators’ decision making time by 7.4%.
- ICLR
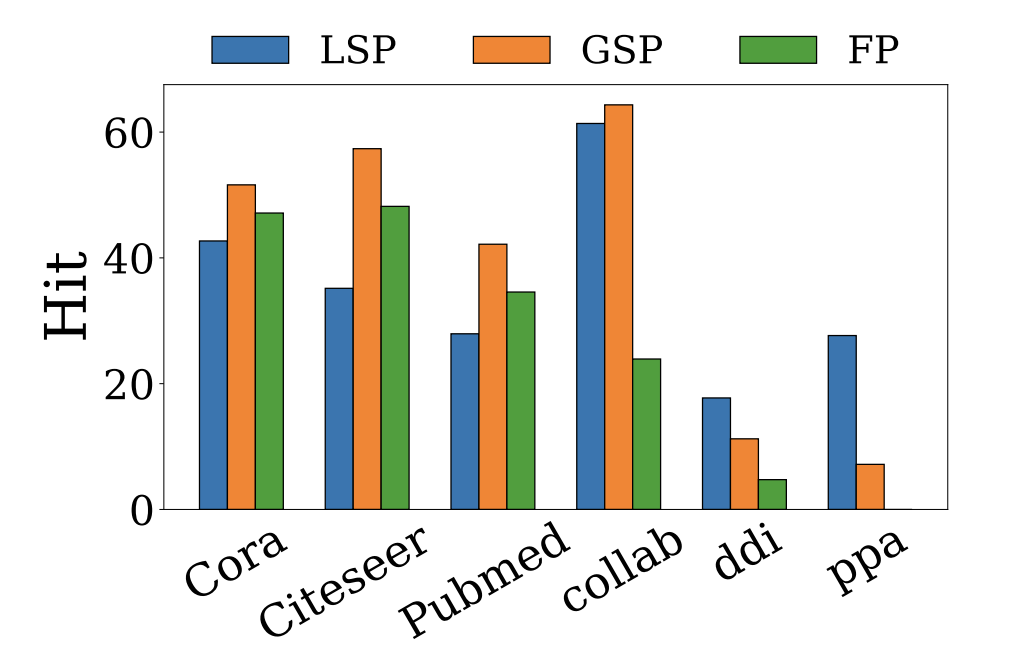 Revisiting Link Prediction: A Data PerspectiveHaitao Mao, Juanhui Li, Harry Shomer, Bingheng Li, Wenqi Fan, Yao Ma, Tong Zhao, Neil Shah, and 1 more authorIn International Conference on Learning Representations, 2024
Revisiting Link Prediction: A Data PerspectiveHaitao Mao, Juanhui Li, Harry Shomer, Bingheng Li, Wenqi Fan, Yao Ma, Tong Zhao, Neil Shah, and 1 more authorIn International Conference on Learning Representations, 2024Link prediction, a fundamental task on graphs, has proven indispensable in various applications, e.g., friend recommendation, protein analysis, and drug interaction prediction. However, since datasets span a multitude of domains, they could have distinct underlying mechanisms of link formation. Evidence in existing literature underscores the absence of a universally best algorithm suitable for all datasets. In this paper, we endeavor to explore principles of link prediction across diverse datasets from a data-centric perspective. We recognize three fundamental factors critical to link prediction: local structural proximity, global structural proximity, and feature proximity. We then unearth relationships among those factors where (i) global structural proximity only shows effectiveness when local structural proximity is deficient. (ii) The incompatibility can be found between feature and structural proximity. Such incompatibility leads to GNNs for Link Prediction (GNN4LP) consistently underperforming on edges where the feature proximity factor dominates. Inspired by these new insights from a data perspective, we offer practical instruction for GNN4LP model design and guidelines for selecting appropriate benchmark datasets for more comprehensive evaluations.
- ICLR
 A Topological Perspective on Demystifying GNN-based Link Prediction PerformanceYu Wang, Tong Zhao, Yuying Zhao, Yunchao Liu, Xueqi Cheng, Neil Shah, and Tyler DerrIn International Conference on Learning Representations, 2024
A Topological Perspective on Demystifying GNN-based Link Prediction PerformanceYu Wang, Tong Zhao, Yuying Zhao, Yunchao Liu, Xueqi Cheng, Neil Shah, and Tyler DerrIn International Conference on Learning Representations, 2024Graph Neural Networks (GNNs) have shown great promise in learning node embeddings for link prediction (LP). While numerous studies aim to improve the overall LP performance of GNNs, none have explored its varying performance across different nodes and its underlying reasons. To this end, we aim to demystify which nodes will perform better from the perspective of their local topology. Despite the widespread belief that low-degree nodes exhibit poorer LP performance, our empirical findings provide nuances to this viewpoint and prompt us to propose a better metric, Topological Concentration (TC), based on the intersection of the local subgraph of each node with the ones of its neighbors. We empirically demonstrate that TC has a higher correlation with LP performance than other node-level topological metrics like degree and subgraph density, offering a better way to identify low-performing nodes than using cold-start. With TC, we discover a novel topological distribution shift issue in which newly joined neighbors of a node tend to become less interactive with that node’s existing neighbors, compromising the generalizability of node embeddings for LP at testing time. To make the computation of TC scalable, We further propose Approximated Topological Concentration (ATC) and theoretically/empirically justify its efficacy in approximating TC and reducing the computation complexity. Given the positive correlation between node TC and its LP performance, we explore the potential of boosting LP performance via enhancing TC by re-weighting edges in the message-passing and discuss its effectiveness with limitations. Our code is publicly available at https://github.com/YuWVandy/Topo_LP_GNN.
- ICLR
 Learning from Graphs Beyond Message Passing Neural NetworksTong Zhao, Neil Shah, and Elham GhazizadehIn International Conference on Learning Representations, 2024
Learning from Graphs Beyond Message Passing Neural NetworksTong Zhao, Neil Shah, and Elham GhazizadehIn International Conference on Learning Representations, 2024Graph, as a potent data structure, models complex relational data that are ubiquitous in real-world applications like social networks and recommendation systems. In the past few years, message passing-based Graph Neural Networks (GNNs) have emerged as standard tools for direct learning from graph data. However, such direct integration during training also introduces challenges, including scalability issues with large-scale graphs and oversmoothing problems with increased model parameter sizes via additional layers. This study offers a bird’s-eye view of high-level paradigms for learning from graph data, categorizing techniques into three distinct classes: (1) using graph structure during preprocessing, (2) using graph structure during training, and (3) using graph structure at test-time inference. Through this overview, we aim to illuminate diverse approaches and advantages inherent in learning from graph data across these fundamental paradigms.
- SIRIP
 Improving Embedding-Based Retrieval in Friend Recommendation with ANN Query ExpansionPau Kung, Zihao Fan, Tong Zhao, Yozen Liu, Zhixin Lai, Jiahui Shi, Yan Wu, Jun Yu, and 2 more authorsIn ACM SIGIR Conference on Research and Development in Information Retrieval, 2024
Improving Embedding-Based Retrieval in Friend Recommendation with ANN Query ExpansionPau Kung, Zihao Fan, Tong Zhao, Yozen Liu, Zhixin Lai, Jiahui Shi, Yan Wu, Jun Yu, and 2 more authorsIn ACM SIGIR Conference on Research and Development in Information Retrieval, 2024Embedding-based retrieval in graph-based recommendation has shown great improvements over traditional graph walk retrieval methods, and has been adopted in large-scale industry applications such as friend recommendations [16]. However, it is not without its challenges: retraining graph embeddings frequently due to changing data is slow and costly, and producing high recall of approximate nearest neighbor search (ANN) on such embeddings is challenging due to the power law distribution of the indexed users. In this work, we address theses issues by introducing a simple query expansion method in ANN, called FriendSeedSelection, where for each node query, we construct a set of 1-hop embeddings and run ANN search. We highlight our approach does not require any model-level tuning, and is inferred from the data at test-time. This design choice effectively enables our recommendation system to adapt to the changing graph distribution without frequent heavy model retraining. We also discuss how we design our system to efficiently construct such queries online to support 10k+ QPS. For friend recommendation, our method shows improvements of recall, and 11% relative friend reciprocated communication metric gains, now serving over 800 million monthly active users at Snapchat.
- DCAI
 GraphPatcher: Mitigating Degree Bias for Graph Neural Networks via Test-Time AugmentationMingxuan Ju, Tong Zhao, Wenhao Yu, Neil Shah, and Yanfang YeIn Data-Centric AI Workshop, 2024
GraphPatcher: Mitigating Degree Bias for Graph Neural Networks via Test-Time AugmentationMingxuan Ju, Tong Zhao, Wenhao Yu, Neil Shah, and Yanfang YeIn Data-Centric AI Workshop, 2024Recent studies have shown that graph neural networks (GNNs) exhibit strong biases towards the node degree: they usually perform satisfactorily on high-degree nodes with rich neighbor information but struggle with low-degree nodes. Existing works tackle this problem by deriving either designated GNN architectures or training strategies specifically for low-degree nodes. Though effective, these approaches unintentionally create an artificial out-of-distribution scenario, where models mainly or even only observe low-degree nodes during the training, leading to a downgraded performance for high-degree nodes that GNNs originally perform well at. In light of this, we propose a test-time augmentation framework, namely GraphPatcher, to enhance test-time generalization of any GNNs on low-degree nodes. Specifically, GraphPatcher iteratively generates virtual nodes to patch artificially created low-degree nodes via corruptions, aiming at progressively reconstructing target GNN’s predictions over a sequence of increasingly corrupted nodes. Through this scheme, GraphPatcher not only learns how to enhance low-degree nodes (when the neighborhoods are heavily corrupted) but also preserves the original superior performance of GNNs on high-degree nodes (when lightly corrupted). Additionally, GraphPatcher is model-agnostic and can also mitigate the degree bias for either self-supervised or supervised GNNs. Comprehensive experiments are conducted over seven benchmark datasets and GraphPatcher consistently enhances common GNNs’ overall performance by up to 3.6% and low-degree performance by up to 6.5%, significantly outperforming state-of-the-art baselines. The source code is publicly available at https://github.com/jumxglhf/GraphPatcher.
- AAAI
 Large-Scale Graph Neural Networks: The Past and New FrontiersRui Xue, Haoyu Han, Tong Zhao, Neil Shah, Jiliang Tang, and Xiaorui LiuIn AAAI Conference on Artificial Intelligence, 2024
Large-Scale Graph Neural Networks: The Past and New FrontiersRui Xue, Haoyu Han, Tong Zhao, Neil Shah, Jiliang Tang, and Xiaorui LiuIn AAAI Conference on Artificial Intelligence, 2024Graph Neural Networks (GNNs) have gained significant attention in recent years due to their ability to model complex relationships between entities in graph-structured data such as social networks, protein structures, and knowledge graphs. However, due to the size of real-world industrial graphs and the special architecture of GNNs, it is a long-lasting challenge for engineers and researchers to deploy GNNs on large-scale graphs, which significantly limits their applications in real-world applications. In this tutorial, we will cover the fundamental scalability challenges of GNNs, frontiers of large- scale GNNs including classic approaches and some newly emerging techniques, the evaluation and comparison of scalable GNNs, and their large-scale real-world applications. Overall, this tutorial aims to provide a systematic and comprehensive understanding of the challenges and state-of-the-art techniques for scaling GNNs. The summary and discussion on future directions will inspire engineers and researchers to explore new ideas and developments in this rapidly evolving field.
- SDM Large-Scale Graph Neural Networks: The Past and New FrontiersRui Xue, Haoyu Han, Tong Zhao, Neil Shah, Jiliang Tang, and Xiaorui LiuIn SIAM International Conference on Data Mining, 2024
Graph Neural Networks (GNNs) have gained significant attention in recent years due to their ability to model complex relationships between entities in graph-structured data such as social networks, protein structures, and knowledge graphs. However, due to the size of real-world industrial graphs and the special architecture of GNNs, it is a long-lasting challenge for engineers and researchers to deploy GNNs on large-scale graphs, which significantly limits their applications in real-world applications. In this tutorial, we will cover the fundamental scalability challenges of GNNs, frontiers of large- scale GNNs including classic approaches and some newly emerging techniques, the evaluation and comparison of scalable GNNs, and their large-scale real-world applications. Overall, this tutorial aims to provide a systematic and comprehensive understanding of the challenges and state-of-the-art techniques for scaling GNNs. The summary and discussion on future directions will inspire engineers and researchers to explore new ideas and developments in this rapidly evolving field.
2023
- preprint
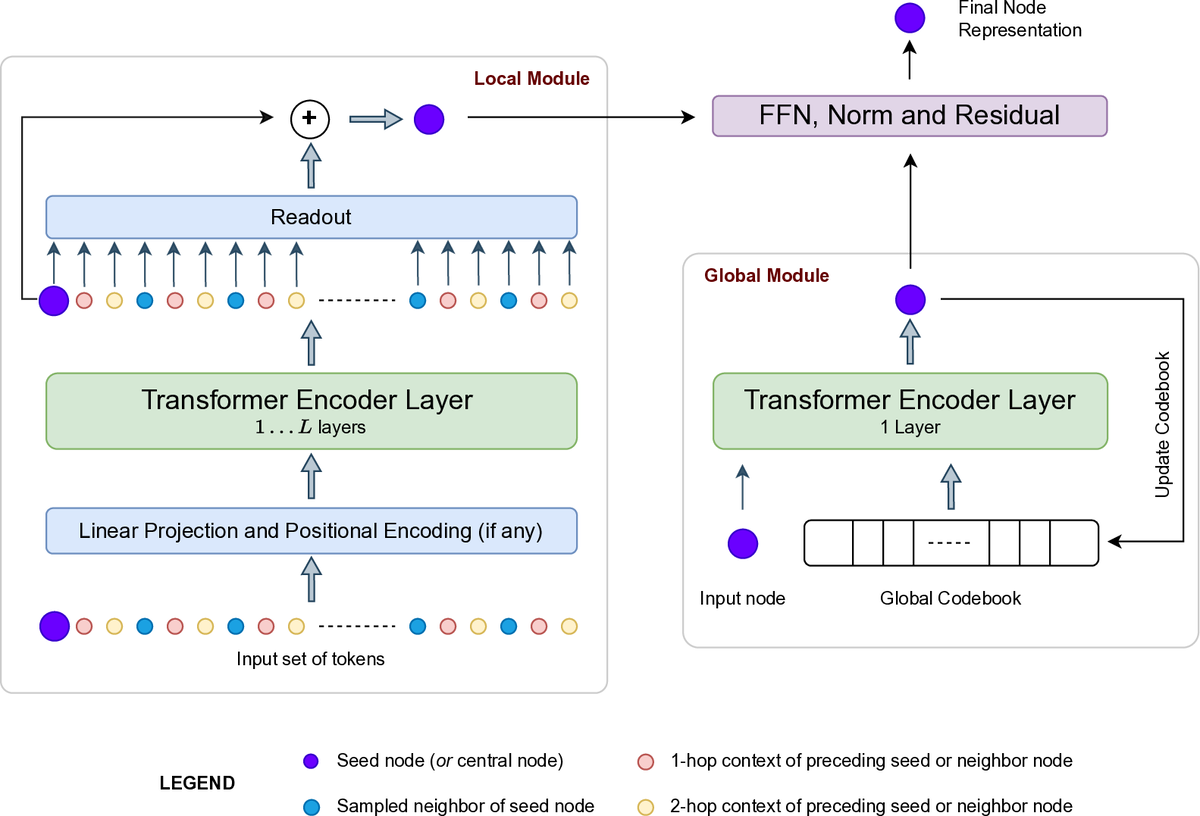 Graph Transformers for Large GraphsVijay Prakash Dwivedi, Yozen Liu, Anh Tuan Luu, Xavier Bresson, Neil Shah, and Tong ZhaoarXiv preprint, 2023
Graph Transformers for Large GraphsVijay Prakash Dwivedi, Yozen Liu, Anh Tuan Luu, Xavier Bresson, Neil Shah, and Tong ZhaoarXiv preprint, 2023Transformers have recently emerged as powerful neural networks for graph learning, showcasing state-of-the-art performance on several graph property prediction tasks. However, these results have been limited to small-scale graphs, where the computational feasibility of the global attention mechanism is possible. The next goal is to scale up these architectures to handle very large graphs on the scale of millions or even billions of nodes. With large-scale graphs, global attention learning is proven impractical due to its quadratic complexity w.r.t. the number of nodes. On the other hand, neighborhood sampling techniques become essential to manage large graph sizes, yet finding the optimal trade-off between speed and accuracy with sampling techniques remains challenging. This work advances representation learning on single large-scale graphs with a focus on identifying model characteristics and critical design constraints for developing scalable graph transformer (GT) architectures. We argue such GT requires layers that can adeptly learn both local and global graph representations while swiftly sampling the graph topology. As such, a key innovation of this work lies in the creation of a fast neighborhood sampling technique coupled with a local attention mechanism that encompasses a 4-hop reception field, but achieved through just 2-hop operations. This local node embedding is then integrated with a global node embedding, acquired via another self-attention layer with an approximate global codebook, before finally sent through a downstream layer for node predictions. The proposed GT framework, named LargeGT, overcomes previous computational bottlenecks and is validated on three large-scale node classification benchmarks. We report a 3x speedup and 16.8% performance gain on ogbn-products and snap-patents, while we also scale LargeGT on ogbn-papers100M with a 5.9% performance improvement.
- NeurIPS
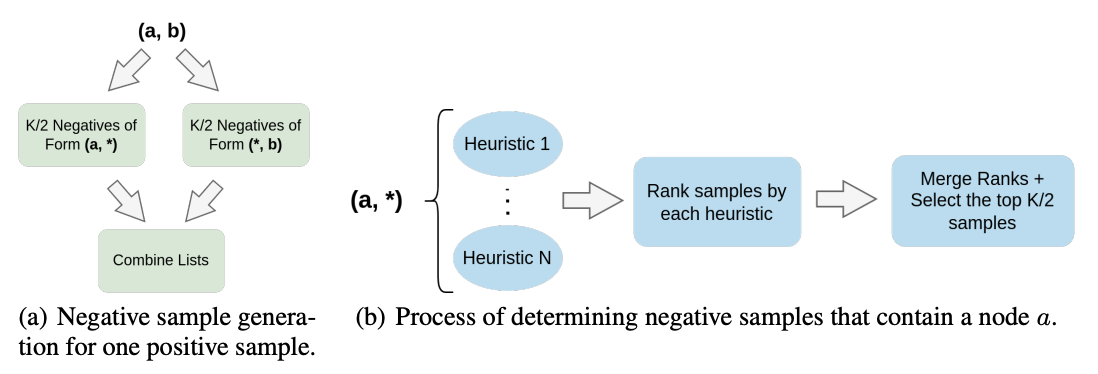 Evaluating Graph Neural Networks for Link Prediction: Current Pitfalls and New BenchmarkingJuanhui Li, Harry Shomer, Haitao Mao, Shenglai Zeng, Yao Ma, Neil Shah, Jiliang Tang, and Dawei YinIn Conference on Neural Information Processing Systems, 2023
Evaluating Graph Neural Networks for Link Prediction: Current Pitfalls and New BenchmarkingJuanhui Li, Harry Shomer, Haitao Mao, Shenglai Zeng, Yao Ma, Neil Shah, Jiliang Tang, and Dawei YinIn Conference on Neural Information Processing Systems, 2023Link prediction attempts to predict whether an unseen edge exists based on only a portion of edges of a graph. A flurry of methods have been introduced in recent years that attempt to make use of graph neural networks (GNNs) for this task. Furthermore, new and diverse datasets have also been created to better evaluate the effectiveness of these new models. However, multiple pitfalls currently exist that hinder our ability to properly evaluate these new methods. These pitfalls mainly include: (1) Lower than actual performance on multiple baselines, (2) A lack of a unified data split and evaluation metric on some datasets, and (3) An unrealistic evaluation setting that uses easy negative samples. To overcome these challenges, we first conduct a fair comparison across prominent methods and datasets, utilizing the same dataset and hyperparameter search settings. We then create a more practical evaluation setting based on a Heuristic Related Sampling Technique (HeaRT), which samples hard negative samples via multiple heuristics. The new evaluation setting helps promote new challenges and opportunities in link prediction by aligning the evaluation with real-world situations. Our implementation and data are available at https://github.com/Juanhui28/HeaRT
- NeurIPS
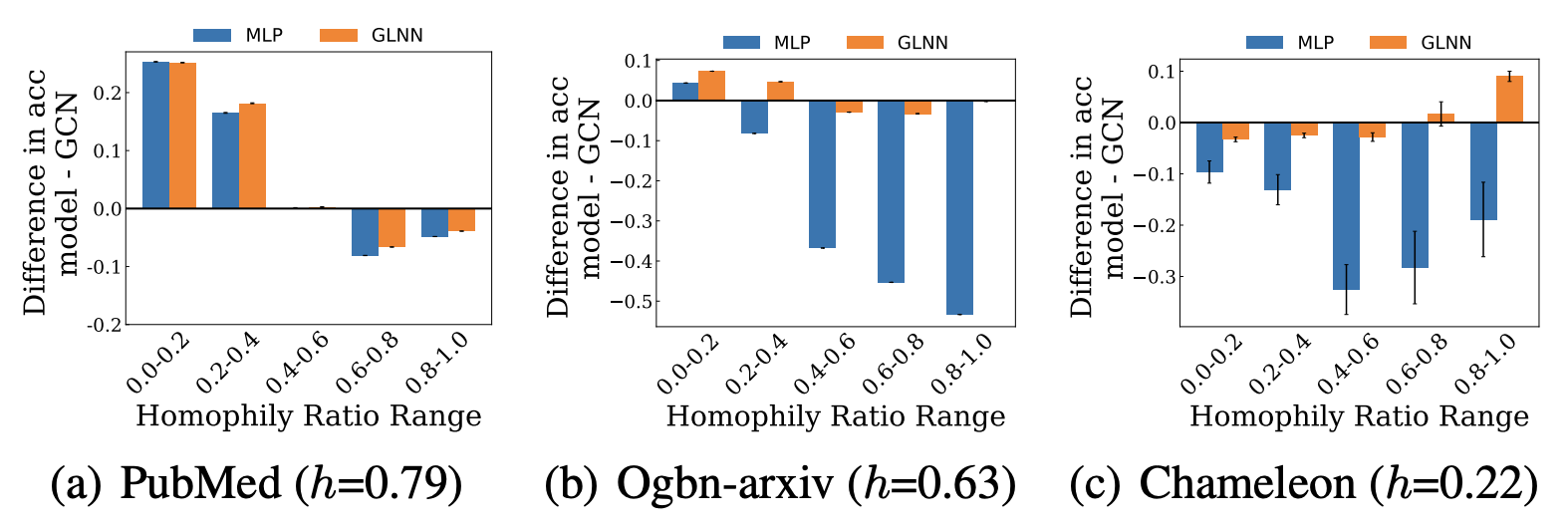 Demystifying Structural Disparity in Graph Neural Networks: Can One Size Fit All?Haitao Mao, Zhikai Chen, Wei Jin, Haoyu Han, Yao Ma, Tong Zhao, Neil Shah, and Jiliang TangIn Conference on Neural Information Processing Systems, 2023
Demystifying Structural Disparity in Graph Neural Networks: Can One Size Fit All?Haitao Mao, Zhikai Chen, Wei Jin, Haoyu Han, Yao Ma, Tong Zhao, Neil Shah, and Jiliang TangIn Conference on Neural Information Processing Systems, 2023Recent studies on Graph Neural Networks(GNNs) provide both empirical and theoretical evidence supporting their effectiveness in capturing structural patterns on both homophilic and certain heterophilic graphs. Notably, most real-world homophilic and heterophilic graphs are comprised of a mixture of nodes in both homophilic and heterophilic structural patterns, exhibiting a structural disparity. However, the analysis of GNN performance with respect to nodes exhibiting different structural patterns, e.g., homophilic nodes in heterophilic graphs, remains rather limited. In the present study, we provide evidence that Graph Neural Networks(GNNs) on node classification typically perform admirably on homophilic nodes within homophilic graphs and heterophilic nodes within heterophilic graphs while struggling on the opposite node set, exhibiting a performance disparity. We theoretically and empirically identify effects of GNNs on testing nodes exhibiting distinct structural patterns. We then propose a rigorous, non-i.i.d PAC-Bayesian generalization bound for GNNs, revealing reasons for the performance disparity, namely the aggregated feature distance and homophily ratio difference between training and testing nodes. Furthermore, we demonstrate the practical implications of our new findings via (1) elucidating the effectiveness of deeper GNNs; and (2) revealing an over-looked distribution shift factor on graph out-of-distribution problem and proposing a new scenario accordingly.
- NeurIPS GraphPatcher: Mitigating Degree Bias for Graph Neural Networks via Test-time AugmentationMingxuan Ju, Tong Zhao, Wenhao Yu, Neil Shah, and Yanfang YeIn Conference on Neural Information Processing Systems, 2023
Recent studies have shown that graph neural networks (GNNs) exhibit strong biases towards the node degree: they usually perform satisfactorily on high-degree nodes with rich neighbor information but struggle with low-degree nodes. Existing works tackle this problem by deriving either designated GNN architectures or training strategies specifically for low-degree nodes. Though effective, these approaches unintentionally create an artificial out-of-distribution scenario, where models mainly or even only observe low-degree nodes during the training, leading to a downgraded performance for high-degree nodes that GNNs originally perform well at. In light of this, we propose a test-time augmentation framework, namely GraphPatcher, to enhance test-time generalization of any GNNs on low-degree nodes. Specifically, GraphPatcher iteratively generates virtual nodes to patch artificially created low-degree nodes via corruptions, aiming at progressively reconstructing target GNN’s predictions over a sequence of increasingly corrupted nodes. Through this scheme, GraphPatcher not only learns how to enhance low-degree nodes (when the neighborhoods are heavily corrupted) but also preserves the original superior performance of GNNs on high-degree nodes (when lightly corrupted). Additionally, GraphPatcher is model-agnostic and can also mitigate the degree bias for either self-supervised or supervised GNNs. Comprehensive experiments are conducted over seven benchmark datasets and GraphPatcher consistently enhances common GNNs’ overall performance by up to 3.6% and low-degree performance by up to 6.5%, significantly outperforming state-of-the-art baselines. The source code is publicly available at https://github.com/jumxglhf/GraphPatcher.
-
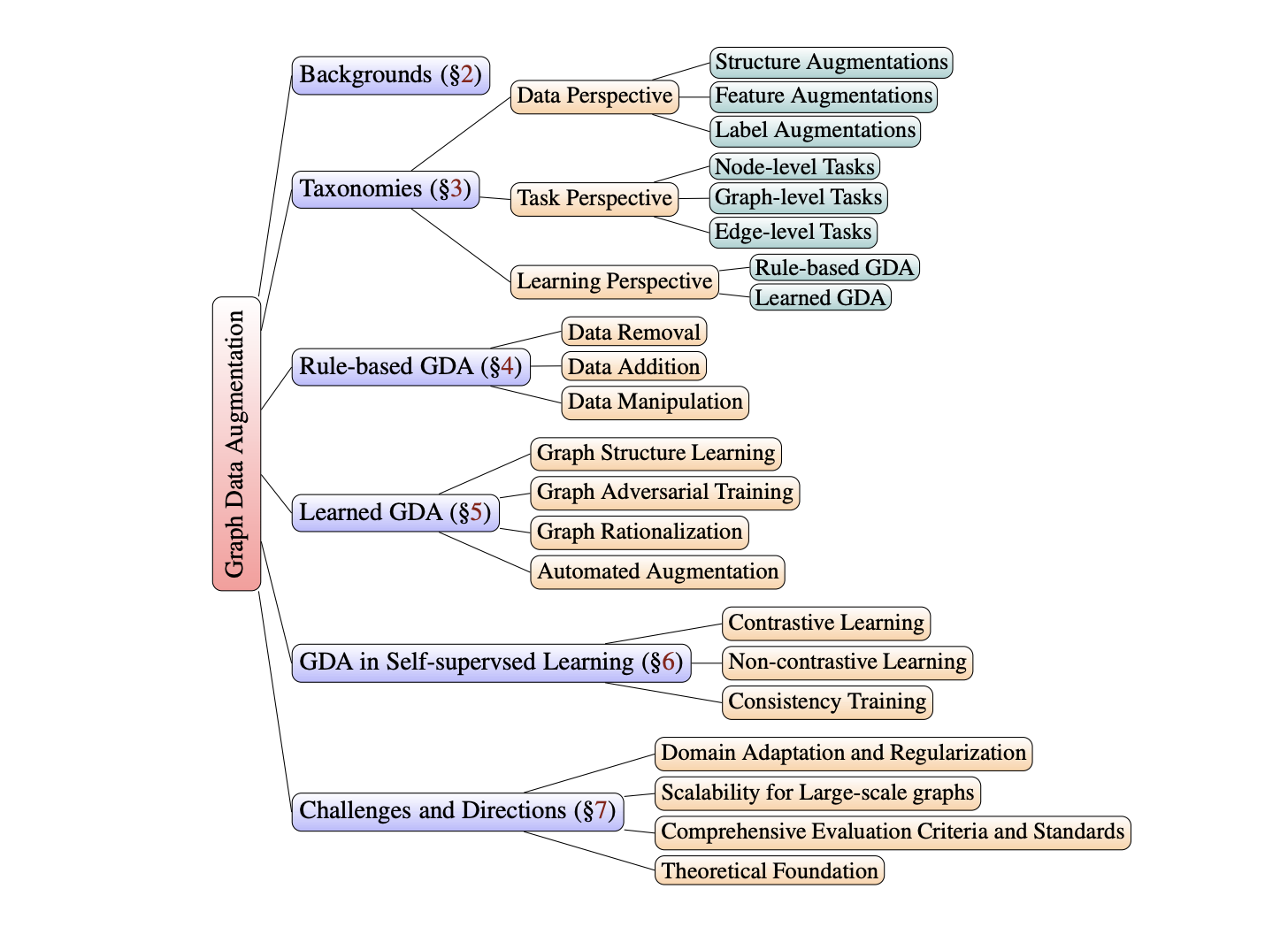 Graph Data Augmentation for Graph Machine Learning: A SurveyTong Zhao, Wei Jin, Yozen Liu, Yingheng Wang, Gang Liu, Stephan Gunnemann, Neil Shah, and Meng JiangIn IEEE Data Engineering Bulletin 2023, 2023
Graph Data Augmentation for Graph Machine Learning: A SurveyTong Zhao, Wei Jin, Yozen Liu, Yingheng Wang, Gang Liu, Stephan Gunnemann, Neil Shah, and Meng JiangIn IEEE Data Engineering Bulletin 2023, 2023Data augmentation has recently seen increased interest in graph machine learning given its demonstrated ability to improve model performance and generalization by added training data. Despite this recent surge, the area is still relatively under-explored, due to the challenges brought by complex, non-Euclidean structure of graph data, which limits the direct analogizing of traditional augmentation operations on other types of image, video or text data. Our work aims to give a necessary and timely overview of existing graph data augmentation methods; notably, we present a comprehensive and systematic survey of graph data augmentation approaches, summarizing the literature in a structured manner. We first introduce three different taxonomies for categorizing graph data augmentation methods from the data, task, and learning perspectives, respectively. Next, we introduce recent advances in graph data augmentation, differentiated by their methodologies and applications. We conclude by outlining currently unsolved challenges and directions for future research. Overall, our work aims to clarify the landscape of existing literature in graph data augmentation and motivates additional work in this area, providing a helpful resource for researchers and practitioners in the broader graph machine learning domain. Additionally, we provide a continuously updated reading list at https://github.com/zhao-tong/graph-data-augmentation-papers.
- KDD
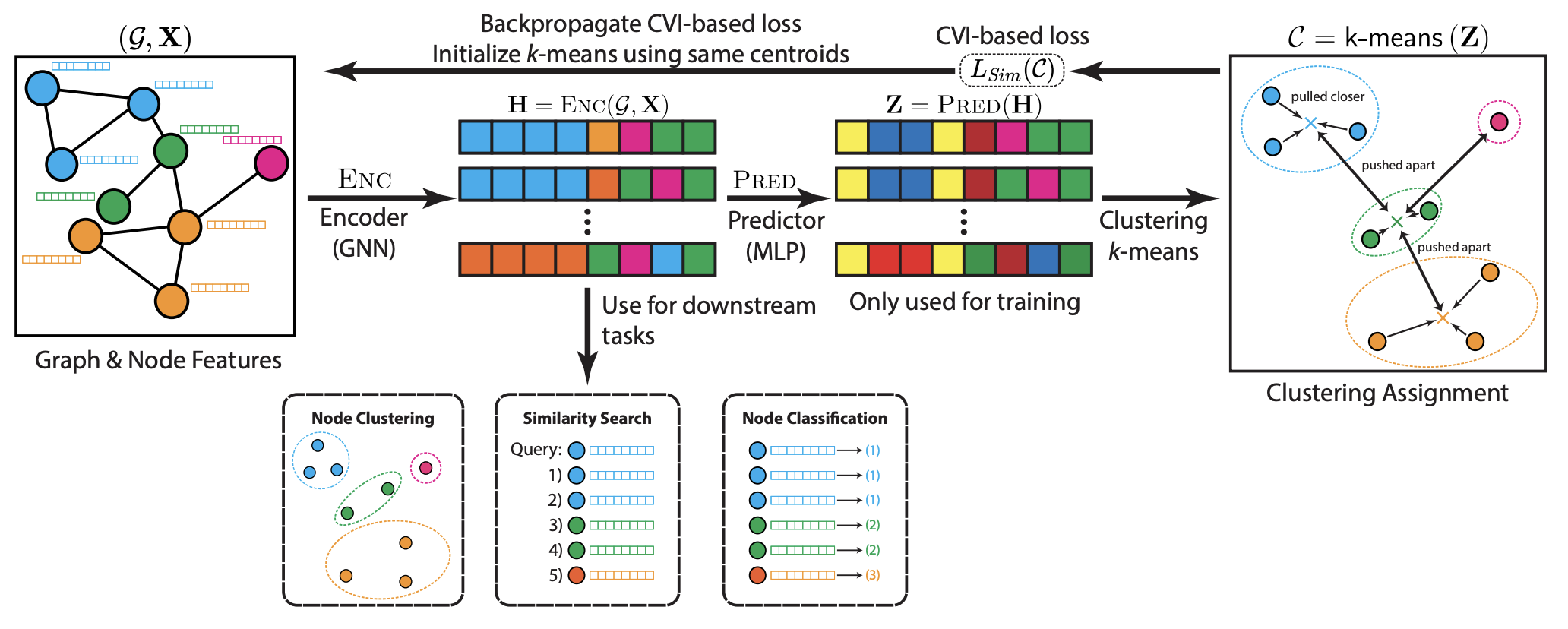 CARL-G: Clustering-Accelerated Representation Learning on GraphsWilliam Shiao, Uday Singh Saini, Yozen Liu, Tong Zhao, Neil Shah, and Evangelos PapalexakisIn ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2023
CARL-G: Clustering-Accelerated Representation Learning on GraphsWilliam Shiao, Uday Singh Saini, Yozen Liu, Tong Zhao, Neil Shah, and Evangelos PapalexakisIn ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2023Self-supervised learning on graphs has made large strides in achieving great performance in various downstream tasks. However, many state-of-the-art methods suffer from a number of impediments, which prevent them from realizing their full potential. For instance, contrastive methods typically require negative sampling, which is often computationally costly. While non-contrastive methods avoid this expensive step, most existing methods either rely on overly complex architectures or dataset-specific augmentations. In this paper, we ask: Can we borrow from classical unsupervised machine learning literature in order to overcome those obstacles? Guided by our key insight that the goal of distance-based clustering closely resembles that of contrastive learning: both attempt to pull representations of similar items together and dissimilar items apart. As a result, we propose CARL-G - a novel clustering-based framework for graph representation learning that uses a loss inspired by Cluster Validation Indices (CVIs), i.e., internal measures of cluster quality (no ground truth required). CARL-G is adaptable to different clustering methods and CVIs, and we show that with the right choice of clustering method and CVI, CARL-G outperforms node classification baselines on 4/5 datasets with up to a 79x training speedup compared to the best-performing baseline. CARL-G also performs at par or better than baselines in node clustering and similarity search tasks, training up to 1,500x faster than the best-performing baseline. Finally, we also provide theoretical foundations for the use of CVI-inspired losses in graph representation learning.
- KDD
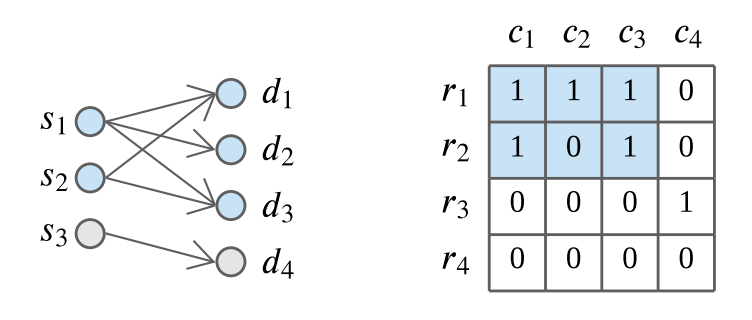 Sketch-Based Anomaly Detection in Streaming GraphsSiddharth Bhatia, Mohit Wadhwa, Kenji Kawaguchi, Neil Shah, Philip Yu, and Bryan HooiIn ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2023
Sketch-Based Anomaly Detection in Streaming GraphsSiddharth Bhatia, Mohit Wadhwa, Kenji Kawaguchi, Neil Shah, Philip Yu, and Bryan HooiIn ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2023Given a stream of graph edges from a dynamic graph, how can we assign anomaly scores to edges and subgraphs in an online manner, for the purpose of detecting unusual behavior, using constant time and memory? For example, in intrusion detection, existing work seeks to detect either anomalous edges or anomalous subgraphs, but not both. In this paper, we first extend the count-min sketch data structure to a higher-order sketch. This higher-order sketch has the useful property of preserving the dense subgraph structure (dense subgraphs in the input turn into dense submatrices in the data structure). We then propose 4 online algorithms that utilize this enhanced data structure, which (a) detect both edge and graph anomalies; (b) process each edge and graph in constant memory and constant update time per newly arriving edge, and; (c) outperform state-of-the-art baselines on 4 real-world datasets. Our method is the first streaming approach that incorporates dense subgraph search to detect graph anomalies in constant memory and time.
- KDD Large-Scale Graph Neural Networks: The Past and New FrontiersRui Xue, Haoyu Han, Tong Zhao, Neil Shah, Jiliang Tang, and Xiaorui LiuIn ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2023
Graph Neural Networks (GNNs) have gained significant attention in recent years due to their ability to model complex relationships between entities in graph-structured data such as social networks, protein structures, and knowledge graphs. However, due to the size of real-world industrial graphs and the special architecture of GNNs, it is a long-lasting challenge for engineers and researchers to deploy GNNs on large-scale graphs, which significantly limits their applications in real-world applications. In this tutorial, we will cover the fundamental scalability challenges of GNNs, frontiers of large- scale GNNs including classic approaches and some newly emerging techniques, the evaluation and comparison of scalable GNNs, and their large-scale real-world applications. Overall, this tutorial aims to provide a systematic and comprehensive understanding of the challenges and state-of-the-art techniques for scaling GNNs. The summary and discussion on future directions will inspire engineers and researchers to explore new ideas and developments in this rapidly evolving field.
- ACL
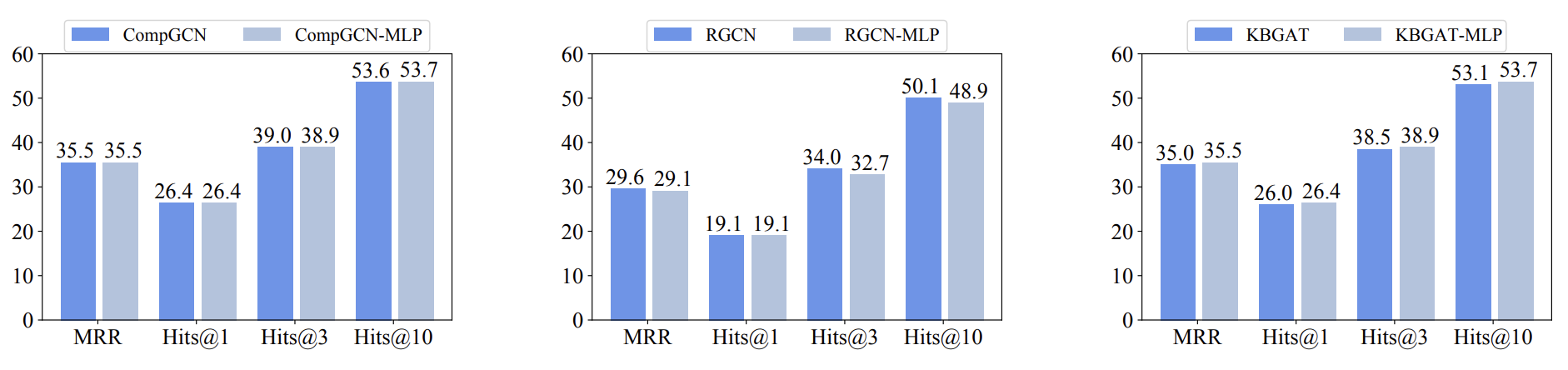 Are Message Passing Neural Networks Really Helpful for Knowledge Graph Completion?Juanhui Li, Harry Shomer, Jiayuan Ding, Yiqi Wang, Yao Ma, Neil Shah, Jiliang Tang, and Dawei YinIn Annual Meeting of the Association of Computational Linguistics, 2023
Are Message Passing Neural Networks Really Helpful for Knowledge Graph Completion?Juanhui Li, Harry Shomer, Jiayuan Ding, Yiqi Wang, Yao Ma, Neil Shah, Jiliang Tang, and Dawei YinIn Annual Meeting of the Association of Computational Linguistics, 2023Knowledge graphs (KGs) facilitate a wide variety of applications. Despite great efforts in creation and maintenance, even the largest KGs are far from complete. Hence, KG completion (KGC) has become one of the most crucial tasks for KG research. Recently, considerable literature in this space has centered around the use of Message Passing (Graph) Neural Networks (MPNNs), to learn powerful embeddings. The success of these methods is naturally attributed to the use of MPNNs over simpler multi-layer perceptron (MLP) models, given their additional message passing (MP) component. In this work, we find that surprisingly, simple MLP models are able to achieve comparable performance to MPNNs, suggesting that MP may not be as crucial as previously believed. With further exploration, we show careful scoring function and loss function design has a much stronger influence on KGC model performance. This suggests a conflation of scoring function design, loss function design, and MP in prior work, with promising insights regarding the scalability of state-of-the-art KGC methods today, as well as careful attention to more suitable MP designs for KGC tasks tomorrow. Our codes are publicly available at: https://github.com/Juanhui28/Are_MPNNs_helpful.
- ICML
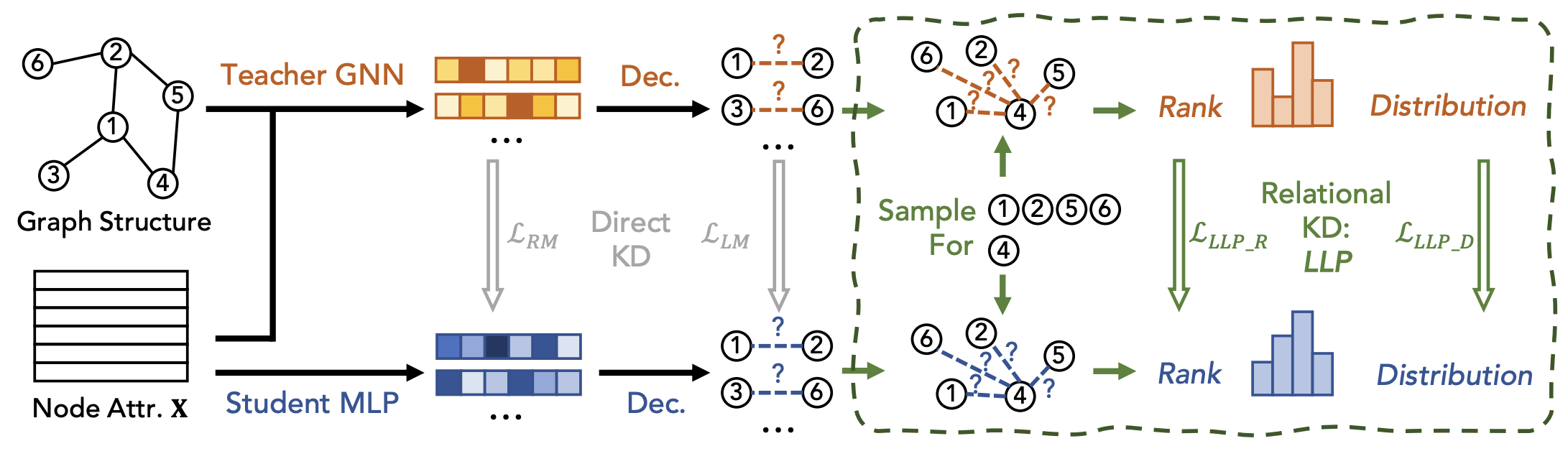 Linkless Link Prediction via Relational DistillationZhichun Guo, William Shiao, Shichang Zhang, Yozen Liu, Nitesh Chawla, Neil Shah, and Tong ZhaoIn International Conference on Machine Learning, 2023
Linkless Link Prediction via Relational DistillationZhichun Guo, William Shiao, Shichang Zhang, Yozen Liu, Nitesh Chawla, Neil Shah, and Tong ZhaoIn International Conference on Machine Learning, 2023Graph Neural Networks (GNNs) have shown exceptional performance in the task of link prediction. Despite their effectiveness, the high latency brought by non-trivial neighborhood data dependency limits GNNs in practical deployments. Conversely, the known efficient MLPs are much less effective than GNNs due to the lack of relational knowledge. In this work, to combine the advantages of GNNs and MLPs, we start with exploring direct knowledge distillation (KD) methods for link prediction, i.e., predicted logit-based matching and node representation-based matching. Upon observing direct KD analogs do not perform well for link prediction, we propose a relational KD framework, Linkless Link Prediction (LLP), to distill knowledge for link prediction with MLPs. Unlike simple KD methods that match independent link logits or node representations, LLP distills relational knowledge that is centered around each (anchor) node to the student MLP. Specifically, we propose rank-based matching and distribution-based matching strategies that complement each other. Extensive experiments demonstrate that LLP boosts the link prediction performance of MLPs with significant margins, and even outperforms the teacher GNNs on 7 out of 8 benchmarks. LLP also achieves a 70.68x speedup in link prediction inference compared to GNNs on the large-scale OGB dataset.
- SIRIP
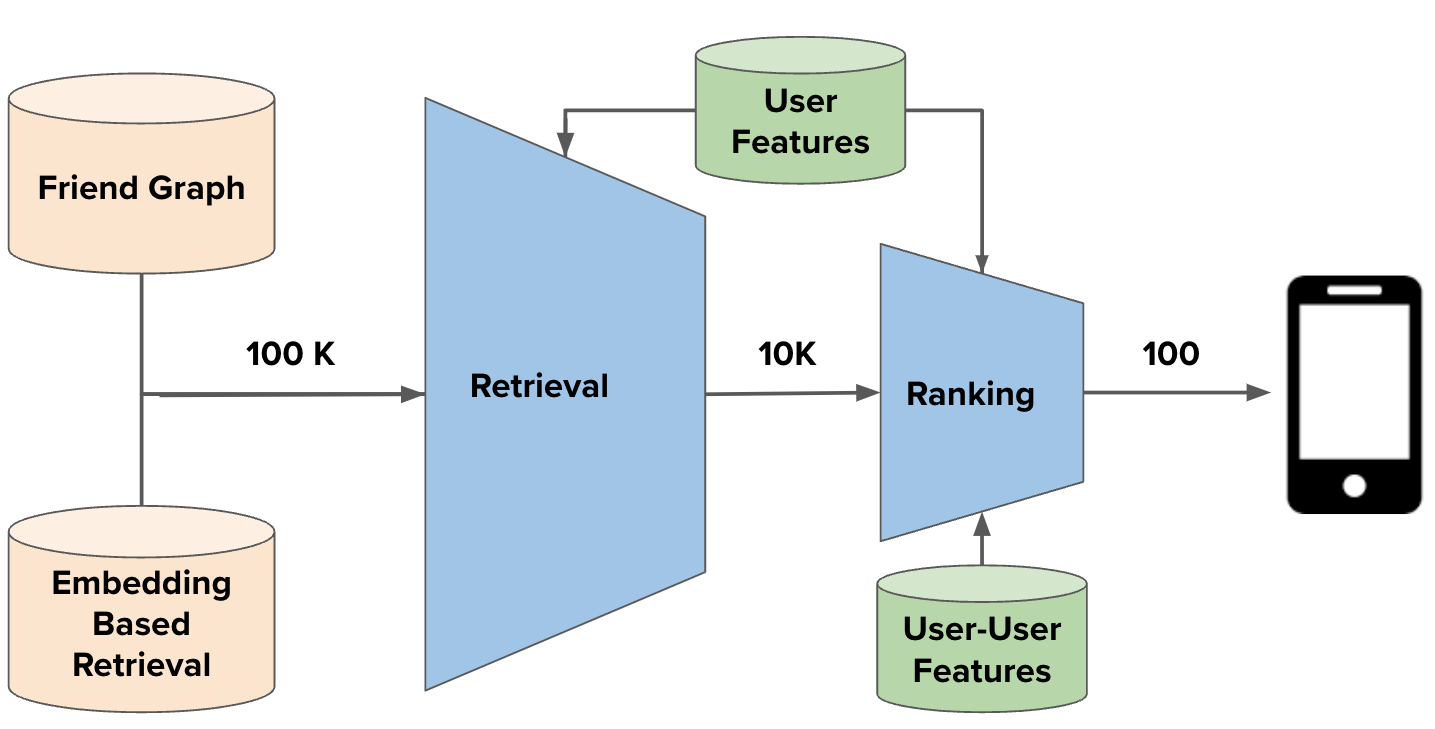 Embedding-based Retrieval in Friend RecommendationJiahui Shi, Vivek Chaurasiya, Yozen Liu, Shubham Vij, Yan Wu, Satya Kanduri, Neil Shah, Peicheng Yu, and 4 more authorsIn ACM SIGIR Conference on Research and Development in Information Retrieval, 2023
Embedding-based Retrieval in Friend RecommendationJiahui Shi, Vivek Chaurasiya, Yozen Liu, Shubham Vij, Yan Wu, Satya Kanduri, Neil Shah, Peicheng Yu, and 4 more authorsIn ACM SIGIR Conference on Research and Development in Information Retrieval, 2023Friend recommendation systems in online social and professional networks such as Snapchat helps users find friends and build connections, leading to better user engagement and retention. Traditional friend recommendation systems take advantage of the principle of locality and use graph traversal to retrieve friend candidates, e.g. Friends-of-Friends (FoF). While this approach has been adopted and shown efficacy in companies with large online networks such as Linkedin and Facebook, it suffers several challenges: (i) discrete graph traversal offers limited reach in cold-start settings, (ii) it is expensive and infeasible in realtime settings beyond 1 or 2 hop requests owing to latency constraints, and (iii) it cannot well-capture the complexity of graph topology or connection strengths, forcing one to resort to other mechanisms to rank and find top-K candidates. In this paper, we proposed a new Embedding Based Retrieval (EBR) system for retrieving friend candidates, which complements the traditional FoF retrieval by retrieving candidates beyond 2-hop, and providing a natural way to rank FoF candidates. Through online A/B test, we observe statistically significant improvements in the number of friendships made with EBR as an additional retrieval source in both low- and high-density network markets. Our contributions in this work include deploying a novel retrieval system to a large-scale friend recommendation system at Snapchat, generating embeddings for billions of users using Graph Neural Networks, and building EBR infrastructure in production to support Snapchat scale.
- ICLR
 MLPInit: Embarrassingly Simple GNN Training Acceleration with MLP InitializationXiaotian Han, Tong Zhao, Yozen Liu, Xia Hu, and Neil ShahIn International Conference on Learning Representations, 2023
MLPInit: Embarrassingly Simple GNN Training Acceleration with MLP InitializationXiaotian Han, Tong Zhao, Yozen Liu, Xia Hu, and Neil ShahIn International Conference on Learning Representations, 2023Training graph neural networks (GNNs) on large graphs is complex and extremely time consuming. This is attributed to overheads caused by sparse matrix multiplication, which are sidestepped when training multi-layer perceptrons (MLPs) with only node features. MLPs, by ignoring graph context, are simple and faster for graph data, however they usually sacrifice prediction accuracy, limiting their applications for graph data. We observe that for most message passing-based GNNs, we can trivially derive an analog MLP (we call this a PeerMLP) with an equivalent weight space, by setting the trainable parameters with the same shapes, making us curious about \textbf{\emph{how do GNNs using weights from a fully trained PeerMLP perform?}} Surprisingly, we find that GNNs initialized with such weights significantly outperform their PeerMLPs, motivating us to use PeerMLP training as a precursor, initialization step to GNN training. To this end, we propose an embarrassingly simple, yet hugely effective initialization method for GNN training acceleration, called MLPInit. Our extensive experiments on multiple large-scale graph datasets with diverse GNN architectures validate that MLPInit can accelerate the training of GNNs (up to 33X speedup on OGB-Products) and often improve prediction performance (e.g., up to 7.97% improvement for GraphSAGE across 7 datasets for node classification, and up to 17.81% improvement across 4 datasets for link prediction on metric Hits@10). The code is available at \href{https://github.com/snap-research/MLPInit-for-GNNs}.
- ICLR
 Multi-task Self-supervised Graph Neural Networks Enable Stronger Task GeneralizationMingxuan Ju, Tong Zhao, Qianlong Wen, Wenhao Yu, Neil Shah, Yanfang Ye, and Chuxu ZhangIn International Conference on Learning Representations, 2023
Multi-task Self-supervised Graph Neural Networks Enable Stronger Task GeneralizationMingxuan Ju, Tong Zhao, Qianlong Wen, Wenhao Yu, Neil Shah, Yanfang Ye, and Chuxu ZhangIn International Conference on Learning Representations, 2023Self-supervised learning (SSL) for graph neural networks (GNNs) has attracted increasing attention from the graph machine learning community in recent years, owing to its capability to learn performant node embeddings without costly label information. One weakness of conventional SSL frameworks for GNNs is that they learn through a single philosophy, such as mutual information maximization or generative reconstruction. When applied to various downstream tasks, these frameworks rarely perform equally well for every task, because one philosophy may not span the extensive knowledge required for all tasks. To enhance the task generalization across tasks, as an important first step forward in exploring fundamental graph models, we introduce PARETOGNN, a multi-task SSL framework for node representation learning over graphs. Specifically, PARETOGNN is self-supervised by manifold pretext tasks observing multiple philosophies. To reconcile different philosophies, we explore a multiple-gradient descent algorithm, such that PARETOGNN actively learns from every pretext task while minimizing potential conflicts. We conduct comprehensive experiments over four downstream tasks (i.e., node classification, node clustering, link prediction, and partition prediction), and our proposal achieves the best overall performance across tasks on 11 widely adopted benchmark datasets. Besides, we observe that learning from multiple philosophies enhances not only the task generalization but also the single task performances, demonstrating that PARETOGNN achieves better task generalization via the disjoint yet complementary knowledge learned from different philosophies. Our code is publicly available at https://github.com/jumxglhf/ParetoGNN.
- ICLR
 Link Prediction with Non-Contrastive LearningWilliam Shiao, Zhichun Guo, Tong Zhao, Vagelis Papalexakis, Yozen Liu, and Neil ShahIn International Conference on Learning Representations, 2023
Link Prediction with Non-Contrastive LearningWilliam Shiao, Zhichun Guo, Tong Zhao, Vagelis Papalexakis, Yozen Liu, and Neil ShahIn International Conference on Learning Representations, 2023A recent focal area in the space of graph neural networks (GNNs) is graph self-supervised learning (SSL), which aims to derive useful node representations without labeled data. Notably, many state-of-the-art graph SSL methods are contrastive methods, which use a combination of positive and negative samples to learn node representations. Owing to challenges in negative sampling (slowness and model sensitivity), recent literature introduced non-contrastive methods, which instead only use positive samples. Though such methods have shown promising performance in node-level tasks, their suitability for link prediction tasks, which are concerned with predicting link existence between pairs of nodes (and have broad applicability to recommendation systems contexts) is yet unexplored. In this work, we extensively evaluate the performance of existing non-contrastive methods for link prediction in both transductive and inductive settings. While most existing non-contrastive methods perform poorly overall, we find that, surprisingly, BGRL generally performs well in transductive settings. However, it performs poorly in the more realistic inductive settings where the model has to generalize to links to/from unseen nodes. We find that non-contrastive models tend to overfit to the training graph and use this analysis to propose T-BGRL, a novel non-contrastive framework that incorporates cheap corruptions to improve the generalization ability of the model. This simple modification strongly improves inductive performance in 5/6 of our datasets, with up to a 120% improvement in Hits@50–all with comparable speed to other non-contrastive baselines and up to 14x faster than the best-performing contrastive baseline. Our work imparts interesting findings about non-contrastive learning for link prediction and paves the way for future researchers to further expand upon this area.
- ICLR
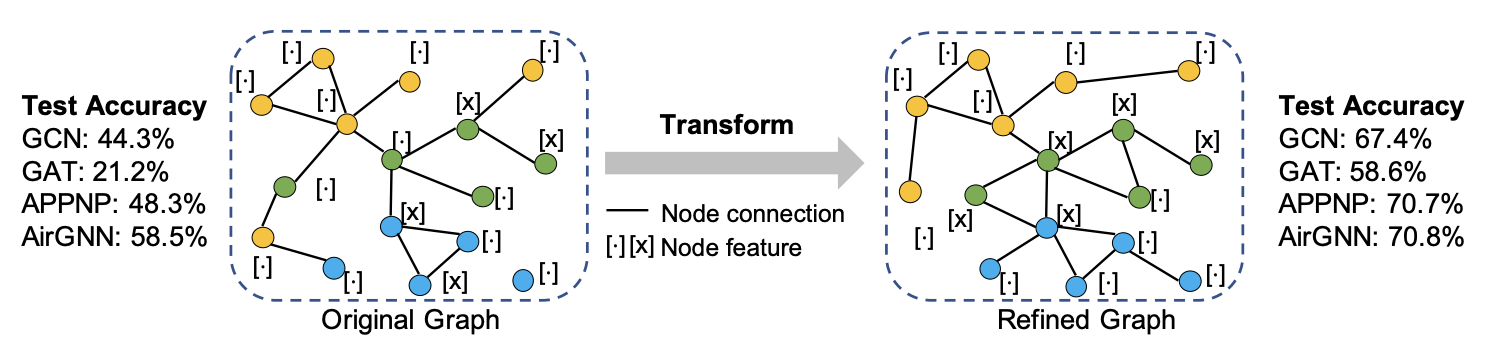 Empowering Graph Representation Learning with Test-Time Graph TransformationWei Jin, Tong Zhao, Jiayuan Ding, Yozen Liu, Jiliang Tang, and Neil ShahIn International Conference on Learning Representations, 2023
Empowering Graph Representation Learning with Test-Time Graph TransformationWei Jin, Tong Zhao, Jiayuan Ding, Yozen Liu, Jiliang Tang, and Neil ShahIn International Conference on Learning Representations, 2023As powerful tools for representation learning on graphs, graph neural networks (GNNs) have facilitated various applications from drug discovery to recommender systems. Nevertheless, the effectiveness of GNNs is immensely challenged by issues related to data quality, such as distribution shift, abnormal features and adversarial attacks. Recent efforts have been made on tackling these issues from a modeling perspective which requires additional cost of changing model architectures or re-training model parameters. In this work, we provide a data-centric view to tackle these issues and propose a graph transformation framework named GTrans which adapts and refines graph data at test time to achieve better performance. We provide theoretical analysis on the design of the framework and discuss why adapting graph data works better than adapting the model. Extensive experiments have demonstrated the effectiveness of GTrans on three distinct scenarios for eight benchmark datasets where suboptimal data is presented. Remarkably, GTrans performs the best in most cases with improvements up to 2.8%, 8.2% and 3.8% over the best baselines on three experimental settings. Code is released at https://github.com/ChandlerBang/GTrans.
- WSDM
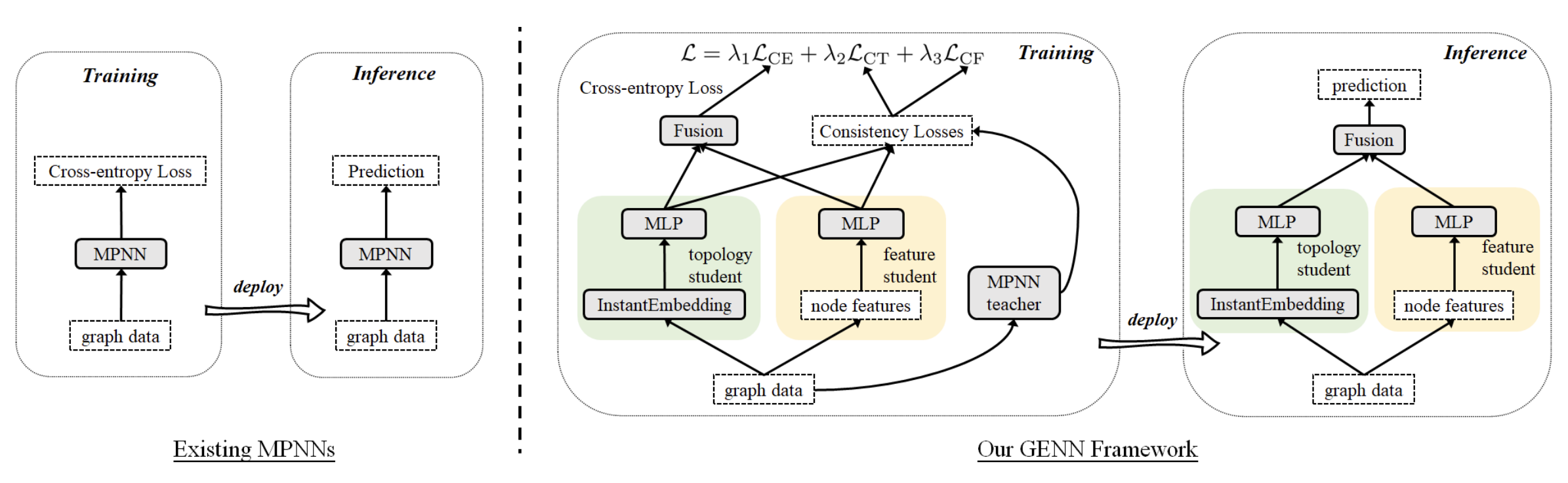 Graph Explicit Neural Networks: Explicitly Encoding Graphs for Efficient and Accurate InferenceYiwei Wang, Bryan Hooi, Yozen Liu, and Neil ShahIn ACM International Conference on Web Search and Data Mining, 2023
Graph Explicit Neural Networks: Explicitly Encoding Graphs for Efficient and Accurate InferenceYiwei Wang, Bryan Hooi, Yozen Liu, and Neil ShahIn ACM International Conference on Web Search and Data Mining, 2023As the state-of-the-art graph learning models, the message passing based neural networks (MPNNs) implicitly use the graph topology as the "pathways" to propagate node features. This implicit use of graph topology induces the MPNNs’ over-reliance on (node) features and high inference latency, which hinders their large-scale applications in industrial contexts. To mitigate these weaknesses, we propose the Graph Explicit Neural Network (GENN) framework. GENN can be flexibly applied to various MPNNs and improves them by providing more efficient and accurate inference that is robust in feature-constrained settings. Specifically, we carefully incorporate recent developments in network embedding methods to efficiently prioritize the graph topology for inference. From this vantage, GENN explicitly encodes the topology as an important source of information to mitigate the reliance on node features. Moreover, by adopting knowledge distillation (KD) techniques, GENN takes an MPNN as the teacher to supervise the training for better effectiveness while avoiding the teacher’s high inference latency. Empirical results show that our GENN infers dramatically faster than its MPNN teacher by 40x-78x. In terms of accuracy, GENN yields significant gains (more than 40%) for its MPNN teacher when the node features are limited based on our explicit encoding. Moreover, GENN outperforms the MPNN teacher even in feature-rich settings thanks to our KD design.
- SDM
 Augmentation Methods for Graph LearningTong Zhao, Kaize Ding, Wei Jin, Gang Liu, Meng Jiang, and Neil ShahIn SIAM International Conference on Data Mining, 2023
Augmentation Methods for Graph LearningTong Zhao, Kaize Ding, Wei Jin, Gang Liu, Meng Jiang, and Neil ShahIn SIAM International Conference on Data Mining, 2023Data augmentation (DA) has recently seen increased interest in graph mining and graph machine learning (ML) owing to its ability to create additional training data and improving resulting trained model generalization. Despite these developments, the area is still quite underexplored, due to the challenges brought by complex, non-Euclidean structure of graph data, which limits the direct analogizing of traditional label-preserving augmentation operations in e.g. computer vision or natural language to this domain. In this tutorial, we present a comprehensive, systematic and structured survey of graph DA (GDA) approaches. We first overview necessary background in graph machine learning, graph neural networks (GNNs), and DA. Next, we present a breadth of literature, separated by heuristic augmentation approaches, learned augmentation approaches, and conclude. We anticipate this tutorial will be valuable for researchers in the graph ML domain, as well as practitioners utilizing these techniques for a wide variety of low-resource applications lacking significant labeled data.
- LoG
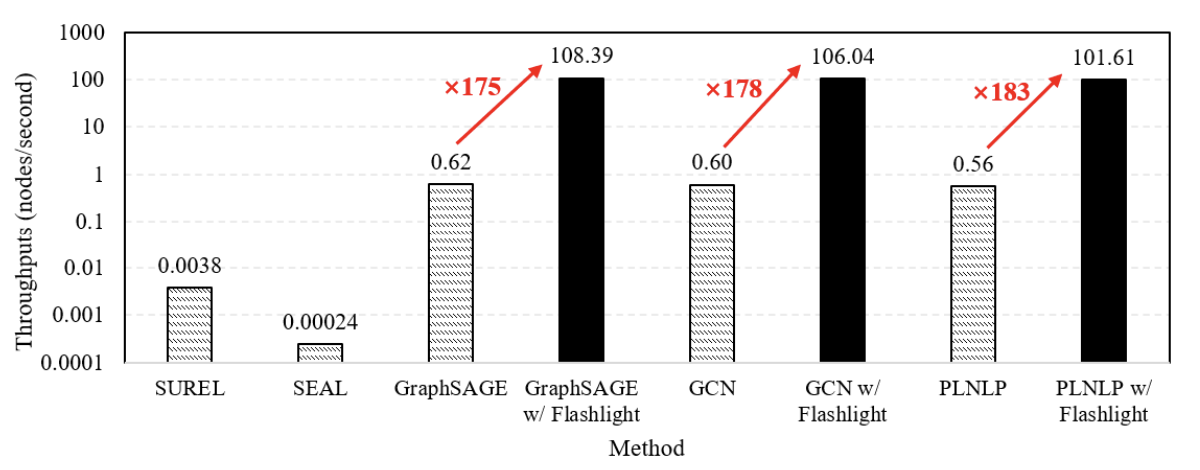 Flashlight: Scalable Link Prediction with Effective DecodersYiwei Wang, Bryan Hooi, Yozen Liu, Tong Zhao, Zhichun Guo, and Neil ShahIn Learning on Graphs Conference, 2023
Flashlight: Scalable Link Prediction with Effective DecodersYiwei Wang, Bryan Hooi, Yozen Liu, Tong Zhao, Zhichun Guo, and Neil ShahIn Learning on Graphs Conference, 2023Link prediction (LP) has been recognized as an important task in graph learning with its broad practical applications. A typical application of LP is to retrieve the top scoring neighbors for a given source node, such as the friend recommendation. These services desire the high inference scalability to find the top scoring neighbors from many candidate nodes at low latencies. There are two popular decoders that the recent LP models mainly use to compute the edge scores from node embeddings: the HadamardMLP and Dot Product decoders. After theoretical and empirical analysis, we find that the HadamardMLP decoders are generally more effective for LP. However, HadamardMLP lacks the scalability for retrieving top scoring neighbors on large graphs, since to the best of our knowledge, there does not exist an algorithm to retrieve the top scoring neighbors for HadamardMLP decoders in sublinear complexity. To make HadamardMLP scalable, we propose the Flashlight algorithm to accelerate the top scoring neighbor retrievals for HadamardMLP: a sublinear algorithm that progressively applies approximate maximum inner product search (MIPS) techniques with adaptively adjusted query embeddings. Empirical results show that Flashlight improves the inference speed of LP by more than 100 times on the large OGBL-CITATION2 dataset without sacrificing effectiveness. Our work paves the way for large-scale LP applications with the effective HadamardMLP decoders by greatly accelerating their inference.
- ICWSM
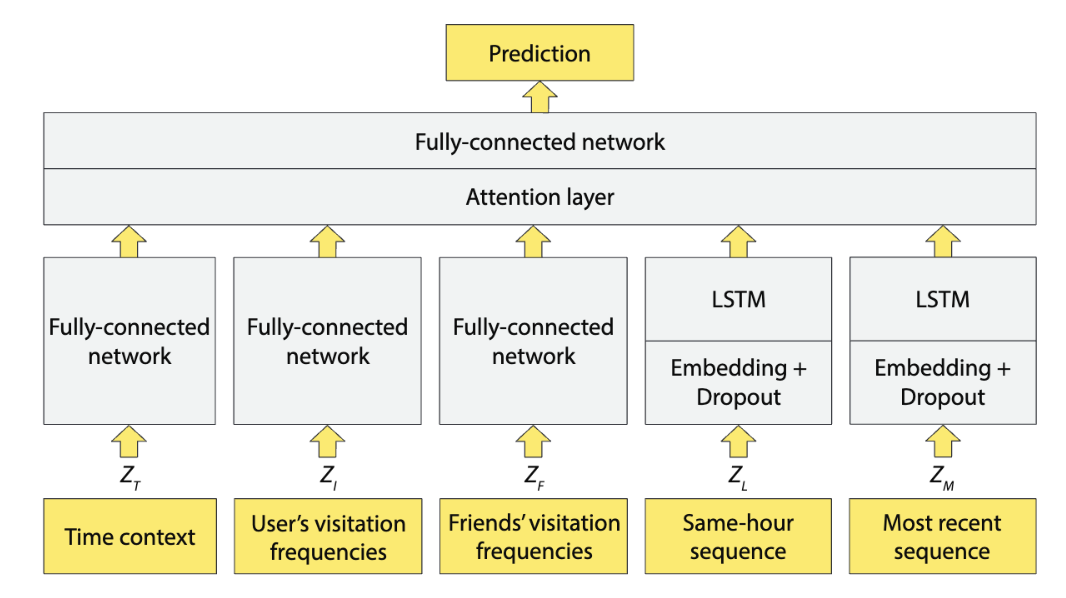 Predicting Future Location Categories of Users in a Large Social PlatformRaiyan Baten, Yozen Liu, Heinrich Peters, Francesco Barbieri, Neil Shah, Leonardo Neves, and Maarten BosIn AAAI International Conference on Web and Social Media, 2023
Predicting Future Location Categories of Users in a Large Social PlatformRaiyan Baten, Yozen Liu, Heinrich Peters, Francesco Barbieri, Neil Shah, Leonardo Neves, and Maarten BosIn AAAI International Conference on Web and Social Media, 2023Understanding the users’ patterns of visiting various location categories can help online platforms improve content personalization and user experiences. Current literature on predicting future location categories of a user typically employs features that can be traced back to the user, such as spatial geo-coordinates and demographic identities. Moreover, existing approaches commonly suffer from cold-start and generalization problems, and often cannot specify when the user will visit the predicted location category. In a large social platform, it is desirable for prediction models to avoid using user-identifiable data, generalize to unseen and new users, and be able to make predictions for specific times in the future. In this work, we construct a neural model, LocHabits, using data from Snapchat. The model omits user-identifiable inputs, leverages temporal and sequential regularities in the location category histories of Snapchat users and their friends, and predicts the users’ next-hour location categories. We evaluate our model on several real-life, large-scale datasets from Snapchat and FourSquare, and find that the model can outperform baselines by 14.94% accuracy. We confirm that the model can (1) generalize to unseen users from different areas and times, and (2) fall back on collective trends in the cold-start scenario. We also study the relative contributions of various factors in making the predictions and find that the users’ visitation preferences and most-recent visitation sequences play more important roles than time contexts, same-hour sequences, and social influence features.
2022
- NeurIPS
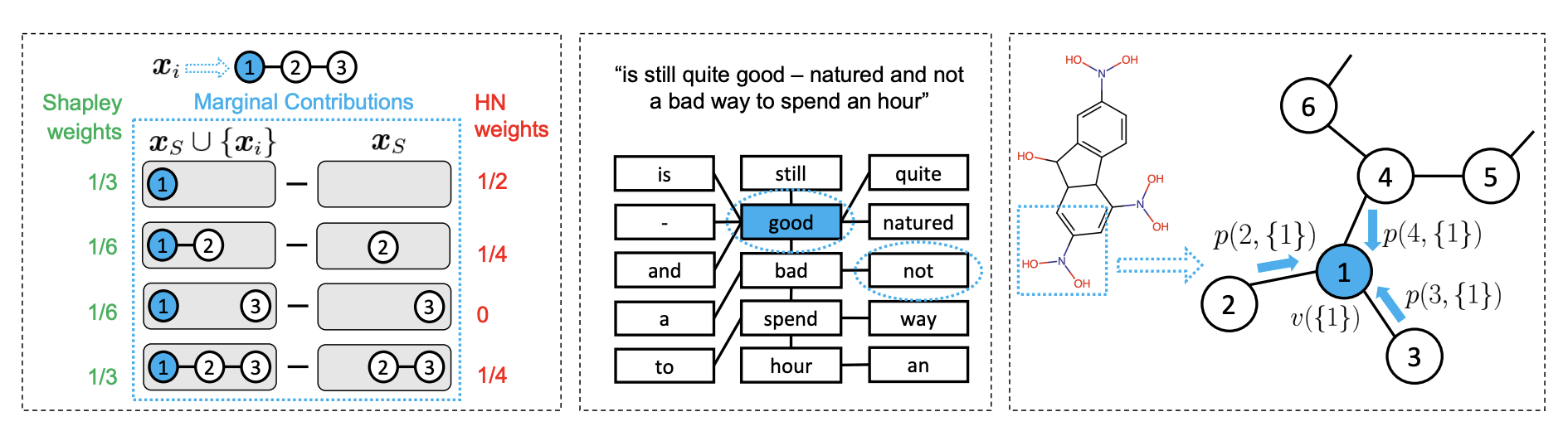 Explaining Graph Neural Networks with Structure-Aware Cooperative GamesShichang Zhang, Yozen Liu, Neil Shah, and Yizhou SunIn Conference on Neural Information Processing Systems, 2022
Explaining Graph Neural Networks with Structure-Aware Cooperative GamesShichang Zhang, Yozen Liu, Neil Shah, and Yizhou SunIn Conference on Neural Information Processing Systems, 2022Explaining machine learning models is an important and increasingly popular area of research interest. The Shapley value from game theory has been proposed as a prime approach to compute feature importance towards model predictions on images, text, tabular data, and recently graph neural networks (GNNs) on graphs. In this work, we revisit the appropriateness of the Shapley value for GNN explanation, where the task is to identify the most important subgraph and constituent nodes for GNN predictions. We claim that the Shapley value is a non-ideal choice for graph data because it is by definition not structure-aware. We propose a Graph Structure-aware eXplanation (GStarX) method to leverage the critical graph structure information to improve the explanation. Specifically, we define a scoring function based on a new structure-aware value from the cooperative game theory proposed by Hamiache and Navarro (HN). When used to score node importance, the HN value utilizes graph structures to attribute cooperation surplus between neighbor nodes, resembling message passing in GNNs, so that node importance scores reflect not only the node feature importance, but also the node structural roles. We demonstrate that GStarX produces qualitatively more intuitive explanations, and quantitatively improves explanation fidelity over strong baselines on chemical graph property prediction and text graph sentiment classification.
- NeurIPS
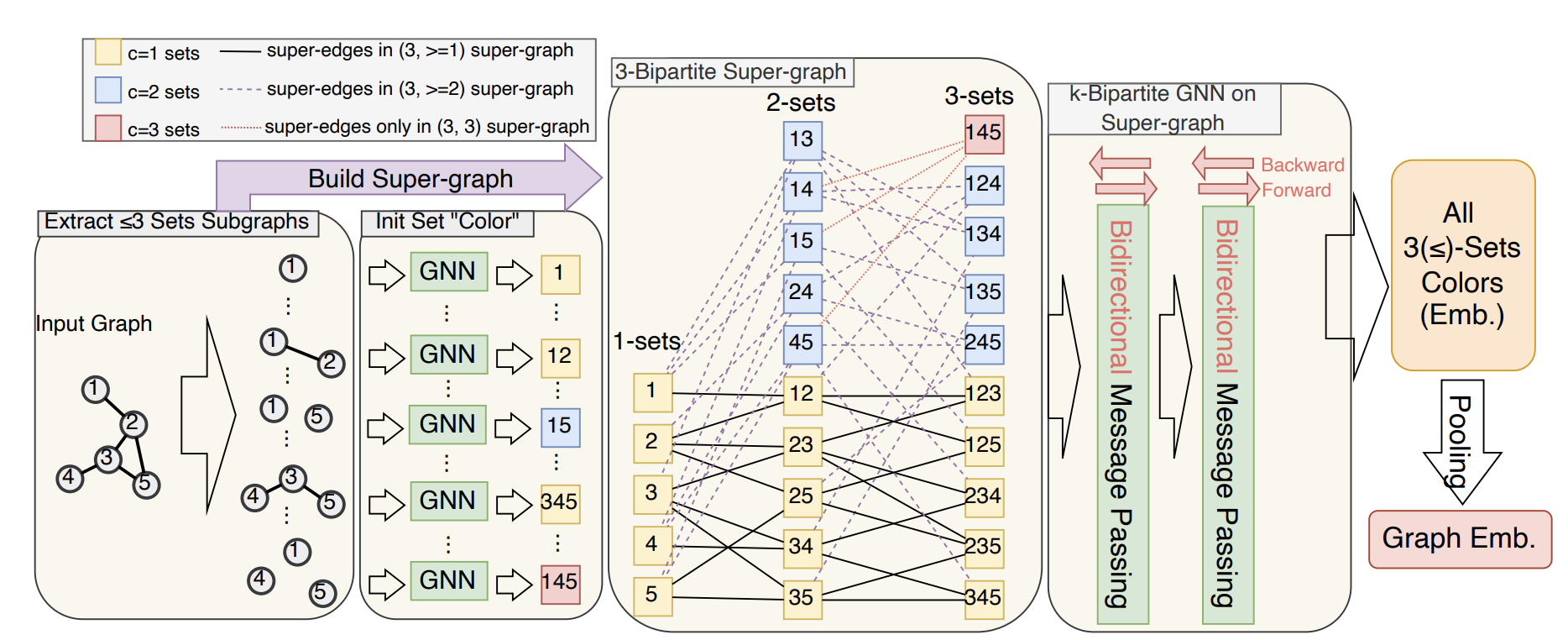 A Practical, Progressively Expressive Graph Neural NetworkLingxiao Zhao, Louis Haertel, Neil Shah, and Leman AkogluIn Conference on Neural Information Processing Systems, 2022
A Practical, Progressively Expressive Graph Neural NetworkLingxiao Zhao, Louis Haertel, Neil Shah, and Leman AkogluIn Conference on Neural Information Processing Systems, 2022Message passing neural networks (MPNNs) have become a dominant flavor of graph neural networks (GNNs) in recent years. Yet, MPNNs come with notable limitations; namely, they are at most as powerful as the 1-dimensional Weisfeiler-Leman (1-WL) test in distinguishing graphs in a graph isomorphism testing frame-work. To this end, researchers have drawn inspiration from the k-WL hierarchy to develop more expressive GNNs. However, current k-WL-equivalent GNNs are not practical for even small values of k, as k-WL becomes combinatorially more complex as k grows. At the same time, several works have found great empirical success in graph learning tasks without highly expressive models, implying that chasing expressiveness with a coarse-grained ruler of expressivity like k-WL is often unneeded in practical tasks. To truly understand the expressiveness-complexity tradeoff, one desires a more fine-grained ruler, which can more gradually increase expressiveness. Our work puts forth such a proposal: Namely, we first propose the (k, c)(<=)-SETWL hierarchy with greatly reduced complexity from k-WL, achieved by moving from k-tuples of nodes to sets with <=k nodes defined over <=c connected components in the induced original graph. We show favorable theoretical results for this model in relation to k-WL, and concretize it via (k, c)(<=)-SETGNN, which is as expressive as (k, c)(<=)-SETWL. Our model is practical and progressively-expressive, increasing in power with k and c. We demonstrate effectiveness on several benchmark datasets, achieving several state-of-the-art results with runtime and memory usage applicable to practical graphs. We open source our implementation at https://github.com/LingxiaoShawn/KCSetGNN.
- CIKM
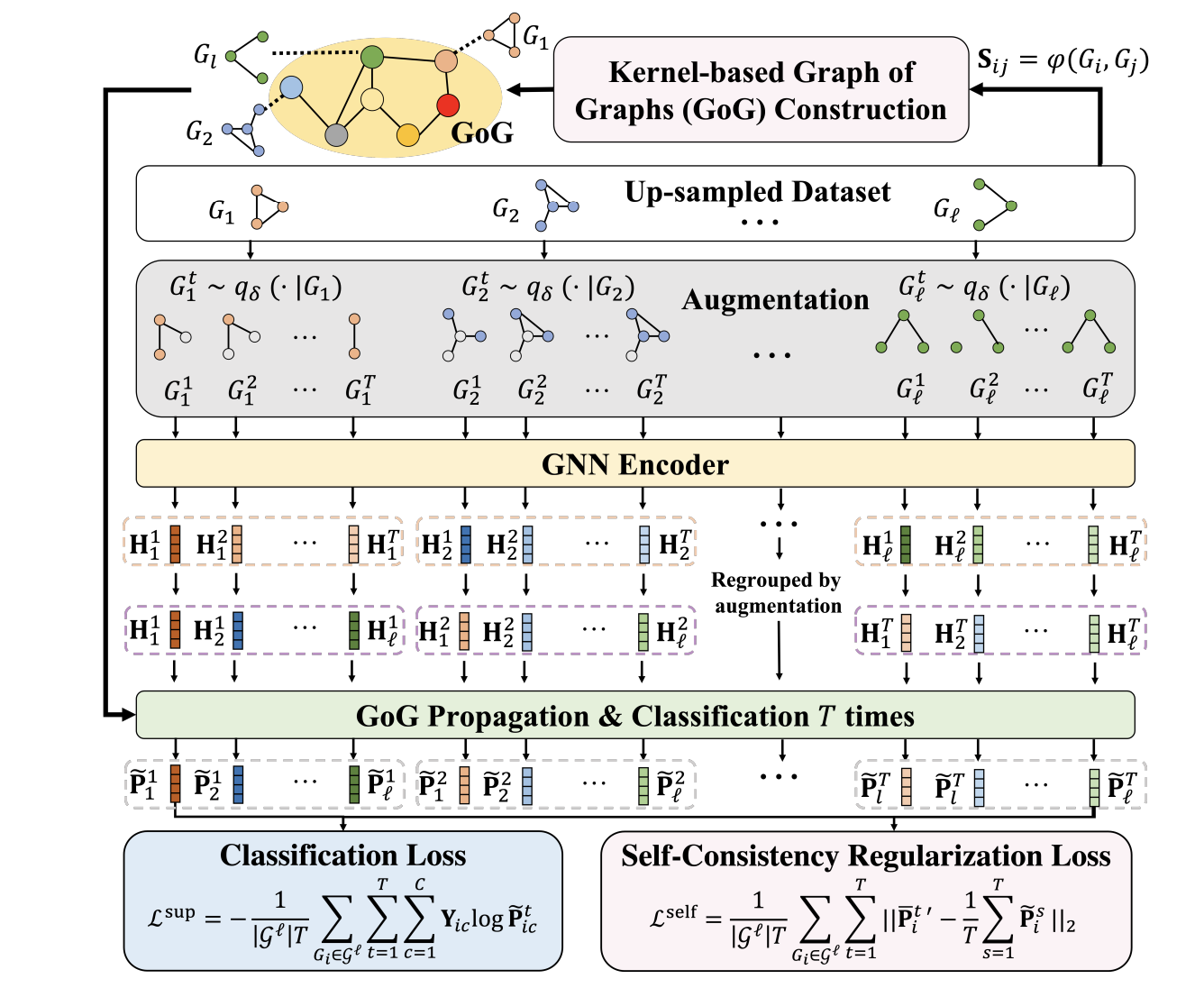 Imbalanced Graph Classification via Graph-of-Graph Neural NetworksYu Wang, Yuying Zhao, Neil Shah, and Tyler DerrIn ACM International Conference on Information and Knowledge Management, 2022
Imbalanced Graph Classification via Graph-of-Graph Neural NetworksYu Wang, Yuying Zhao, Neil Shah, and Tyler DerrIn ACM International Conference on Information and Knowledge Management, 2022Graph Neural Networks (GNNs) have achieved unprecedented success in identifying categorical labels of graphs. However, most existing graph classification problems with GNNs follow the protocol of balanced data splitting, which misaligns with many real-world scenarios in which some classes have much fewer labels than others. Directly training GNNs under this imbalanced scenario may lead to uninformative representations of graphs in minority classes, and compromise the overall classification performance, which signifies the importance of developing effective GNNs towards handling imbalanced graph classification. Existing methods are either tailored for non-graph structured data or designed specifically for imbalanced node classification while few focus on imbalanced graph classification. To this end, we introduce a novel framework, Graph-of-Graph Neural Networks (G^2GNN), which alleviates the graph imbalance issue by deriving extra supervision globally from neighboring graphs and locally from stochastic augmentations of graphs. Globally, we construct a graph of graphs (GoG) based on kernel similarity and perform GoG propagation to aggregate neighboring graph representations. Locally, we employ topological augmentation via masking node features or dropping edges with self-consistency regularization to generate stochastic augmentations of each graph that improve the model generalibility. Extensive graph classification experiments conducted on seven benchmark datasets demonstrate our proposed G^2GNN outperforms numerous baselines by roughly 5% in both F1-macro and F1-micro scores. The implementation of G^2GNN is available at https://github.com/YuWVandy/G2GNN.
- ICWSM
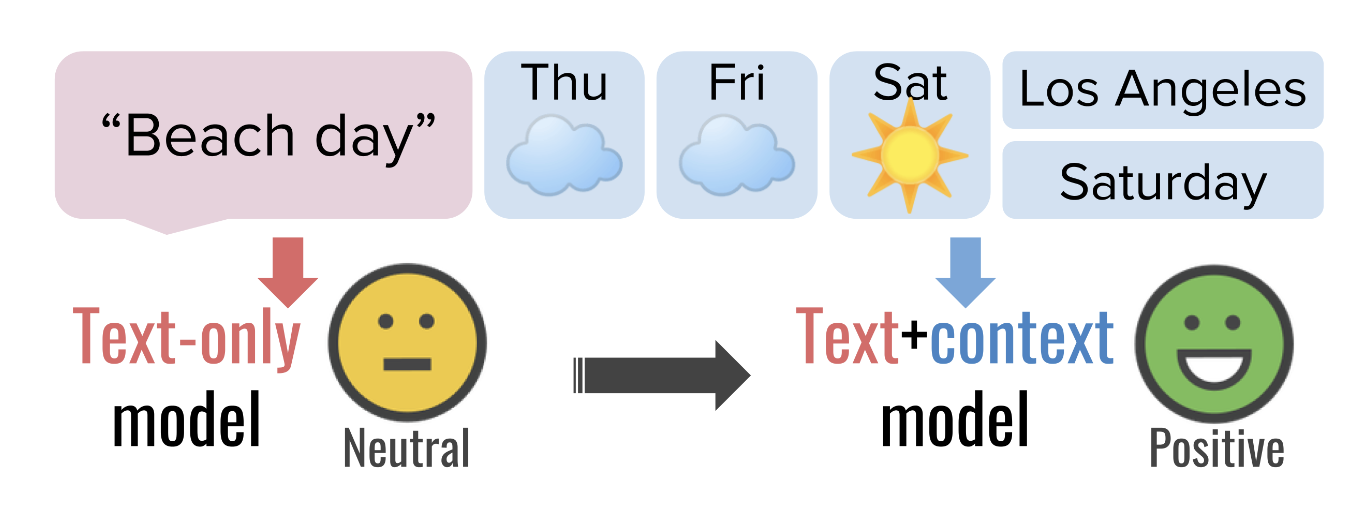 Sunshine with a Chance of Smiles: How does Weather Impact Sentiment on Social Media?Julie Jiang, Nils Murrugarra-Llerena, Maarten Bos, Yozen Liu, Neil Shah, Leonardo Neves, and Francesco BarbieriIn AAAI International Conference on Web and Social Media, 2022
Sunshine with a Chance of Smiles: How does Weather Impact Sentiment on Social Media?Julie Jiang, Nils Murrugarra-Llerena, Maarten Bos, Yozen Liu, Neil Shah, Leonardo Neves, and Francesco BarbieriIn AAAI International Conference on Web and Social Media, 2022The environment we are in can affect our mood and behavior. One environmental factor is weather, which is linked to sentiment as expressed on social media. However, less is known about how integrating changes in weather, along with time and location contextual cues, can improve sentiment detection and understanding. In this paper, we explore the effects of three contextual features–weather, location, and time–on expressed sentiment in social media. Leveraging a large Snapchat dataset, we provide extensive experimental evidence that including contextual features in addition to textual features significantly improves textual sentiment detection performance by 3% over transformer-based language models. Our results also generalize cross-domain to Twitter. Ablation studies indicate the relative importance of weather compared to location and time. We also conduct correlation analyses on 8 million Snapchat posts to highlight the link between past weather and current sentiment, showing that weather has a lasting impact on mood. Users generally exhibit more positive sentiment in better weather conditions as well as in improved weather conditions. Additionally, we show that temperature’s link with mood holds after controlling for time or population density, but there exist geographical differences in how temperature affects mood. Our work demonstrates the effectiveness of including external contexts in linguistic tasks and carries design implications for researchers and designers of social media.
- ICLR
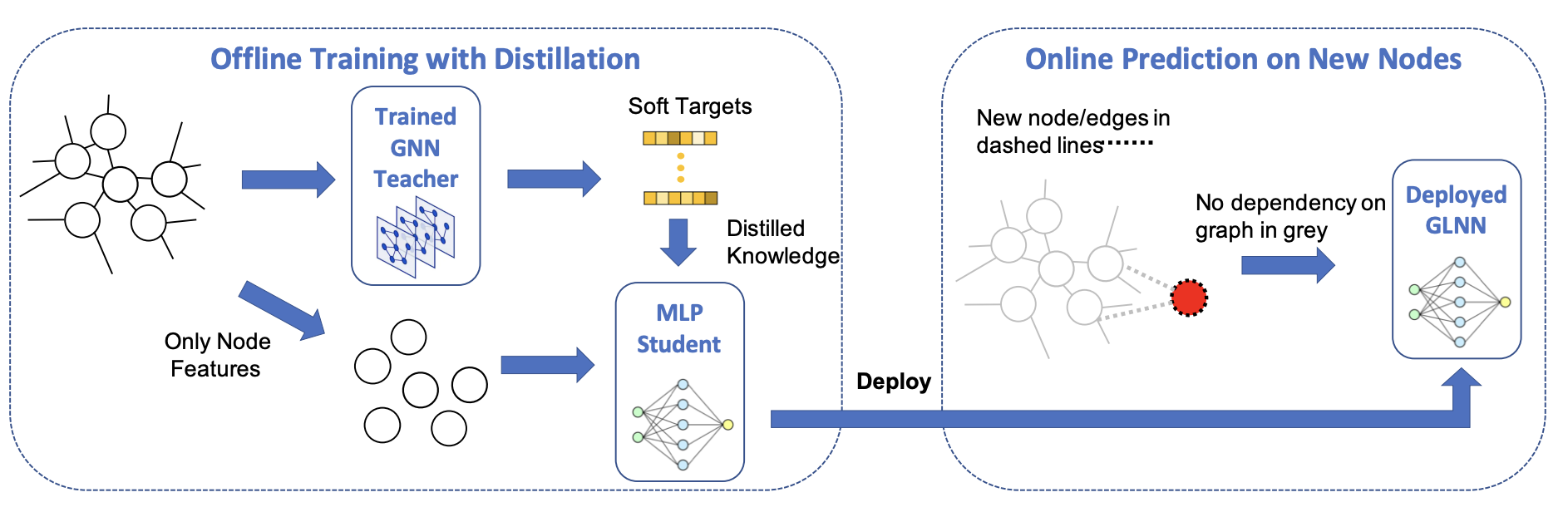 Graph-less Neural Networks: Teaching Old MLPs new Tricks via DistillationShichang Zhang, Yozen Liu, Yizhou Sun, and Neil ShahIn International Conference on Learning Representations, 2022
Graph-less Neural Networks: Teaching Old MLPs new Tricks via DistillationShichang Zhang, Yozen Liu, Yizhou Sun, and Neil ShahIn International Conference on Learning Representations, 2022Graph Neural Networks (GNNs) are popular for graph machine learning and have shown great results on wide node classification tasks. Yet, they are less popular for practical deployments in the industry owing to their scalability challenges incurred by data dependency. Namely, GNN inference depends on neighbor nodes multiple hops away from the target, and fetching them burdens latency-constrained applications. Existing inference acceleration methods like pruning and quantization can speed up GNNs by reducing Multiplication-and-ACcumulation (MAC) operations, but the improvements are limited given the data dependency is not resolved. Conversely, multi-layer perceptrons (MLPs) have no graph dependency and infer much faster than GNNs, even though they are less accurate than GNNs for node classification in general. Motivated by these complementary strengths and weaknesses, we bring GNNs and MLPs together via knowledge distillation (KD). Our work shows that the performance of MLPs can be improved by large margins with GNN KD. We call the distilled MLPs Graph-less Neural Networks (GLNNs) as they have no inference graph dependency. We show that GLNNs with competitive accuracy infer faster than GNNs by 146X-273X and faster than other acceleration methods by 14X-27X. Under a production setting involving both transductive and inductive predictions across 7 datasets, GLNN accuracies improve over stand-alone MLPs by 12.36% on average and match GNNs on 6/7 datasets. Comprehensive analysis shows when and why GLNNs can achieve competitive accuracies to GNNs and suggests GLNN as a handy choice for latency-constrained applications.
- ICLR
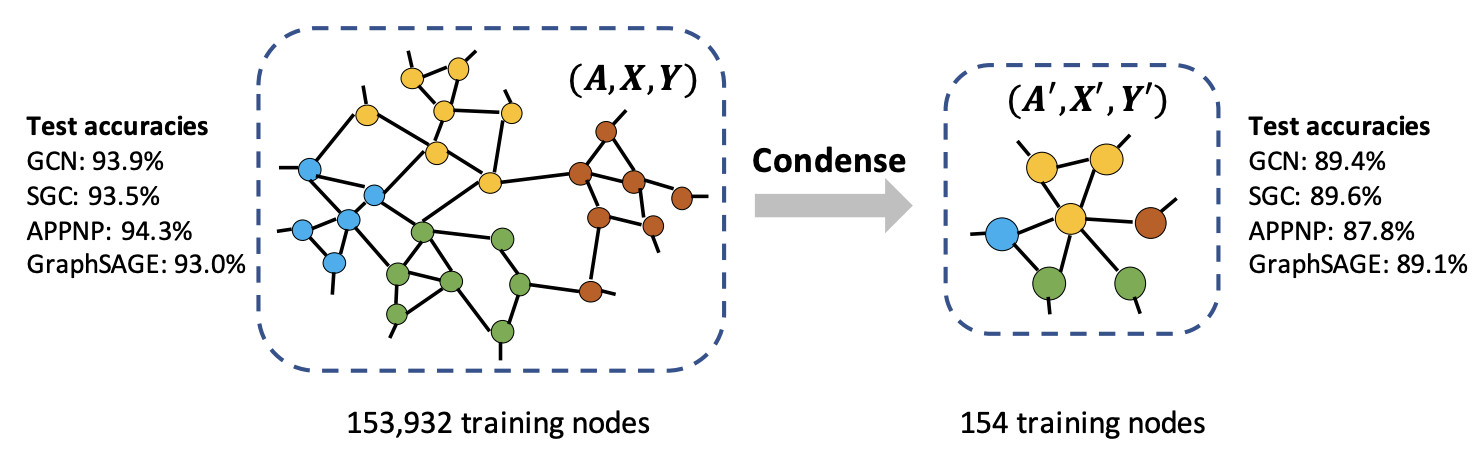 Graph Condensation for Graph Neural NetworksWei Jin, Lingxiao Zhao, Shichang Zhang, Yozen Liu, Jiliang Tang, and Neil ShahIn International Conference on Learning Representations, 2022
Graph Condensation for Graph Neural NetworksWei Jin, Lingxiao Zhao, Shichang Zhang, Yozen Liu, Jiliang Tang, and Neil ShahIn International Conference on Learning Representations, 2022Given the prevalence of large-scale graphs in real-world applications, the storage and time for training neural models have raised increasing concerns. To alleviate the concerns, we propose and study the problem of graph condensation for graph neural networks (GNNs). Specifically, we aim to condense the large, original graph into a small, synthetic and highly-informative graph, such that GNNs trained on the small graph and large graph have comparable performance. We approach the condensation problem by imitating the GNN training trajectory on the original graph through the optimization of a gradient matching loss and design a strategy to condense node futures and structural information simultaneously. Extensive experiments have demonstrated the effectiveness of the proposed framework in condensing different graph datasets into informative smaller graphs. In particular, we are able to approximate the original test accuracy by 95.3% on Reddit, 99.8% on Flickr and 99.0% on Citeseer, while reducing their graph size by more than 99.9%, and the condensed graphs can be used to train various GNN architectures.Code is released at https://github.com/ChandlerBang/GCond.
- ICLR
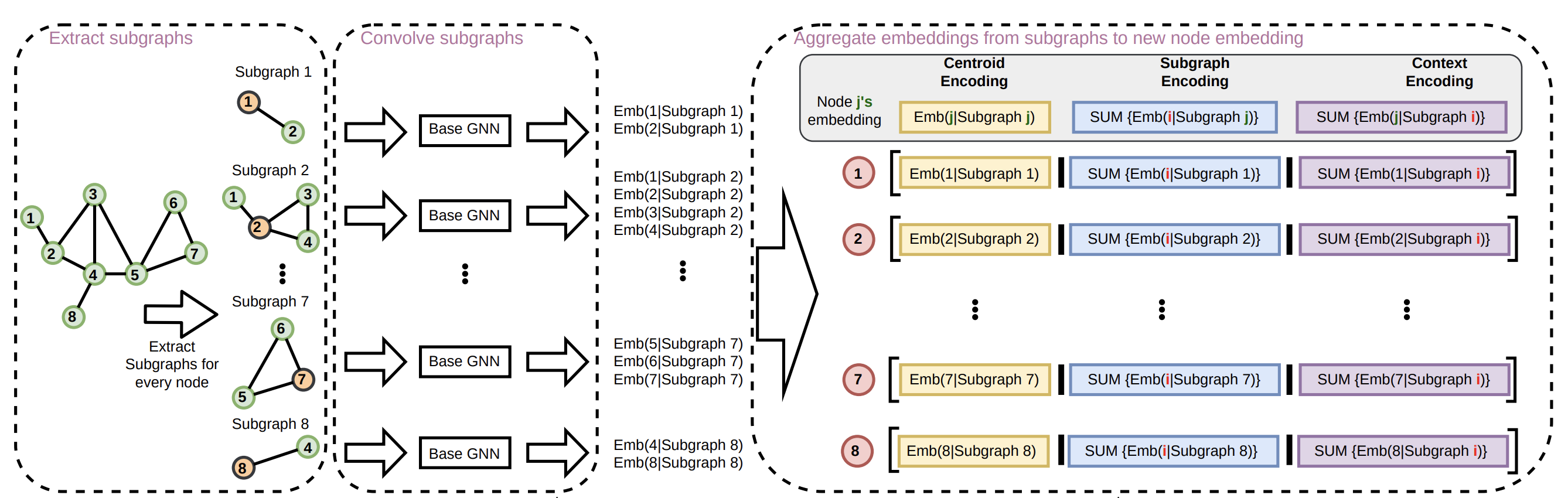 From Stars to Subgraphs: Uplifting any GNN with Local Structure AwarenessLingxiao Zhao, Wei Jin, Leman Akoglu, and Neil ShahIn International Conference on Learning Representations, 2022
From Stars to Subgraphs: Uplifting any GNN with Local Structure AwarenessLingxiao Zhao, Wei Jin, Leman Akoglu, and Neil ShahIn International Conference on Learning Representations, 2022Message Passing Neural Networks (MPNNs) are a common type of Graph Neural Network (GNN), in which each node’s representation is computed recursively by aggregating representations (messages) from its immediate neighbors akin to a star-shaped pattern. MPNNs are appealing for being efficient and scalable, how-ever their expressiveness is upper-bounded by the 1st-order Weisfeiler-Lehman isomorphism test (1-WL). In response, prior works propose highly expressive models at the cost of scalability and sometimes generalization performance. Our work stands between these two regimes: we introduce a general framework to uplift any MPNN to be more expressive, with limited scalability overhead and greatly improved practical performance. We achieve this by extending local aggregation in MPNNs from star patterns to general subgraph patterns (e.g.,k-egonets):in our framework, each node representation is computed as the encoding of a surrounding induced subgraph rather than encoding of immediate neighbors only (i.e. a star). We choose the subgraph encoder to be a GNN (mainly MPNNs, considering scalability) to design a general framework that serves as a wrapper to up-lift any GNN. We call our proposed method GNN-AK(GNN As Kernel), as the framework resembles a convolutional neural network by replacing the kernel with GNNs. Theoretically, we show that our framework is strictly more powerful than 1&2-WL, and is not less powerful than 3-WL. We also design subgraph sampling strategies which greatly reduce memory footprint and improve speed while maintaining performance. Our method sets new state-of-the-art performance by large margins for several well-known graph ML tasks; specifically, 0.08 MAE on ZINC,74.79% and 86.887% accuracy on CIFAR10 and PATTERN respectively.
- ICLR
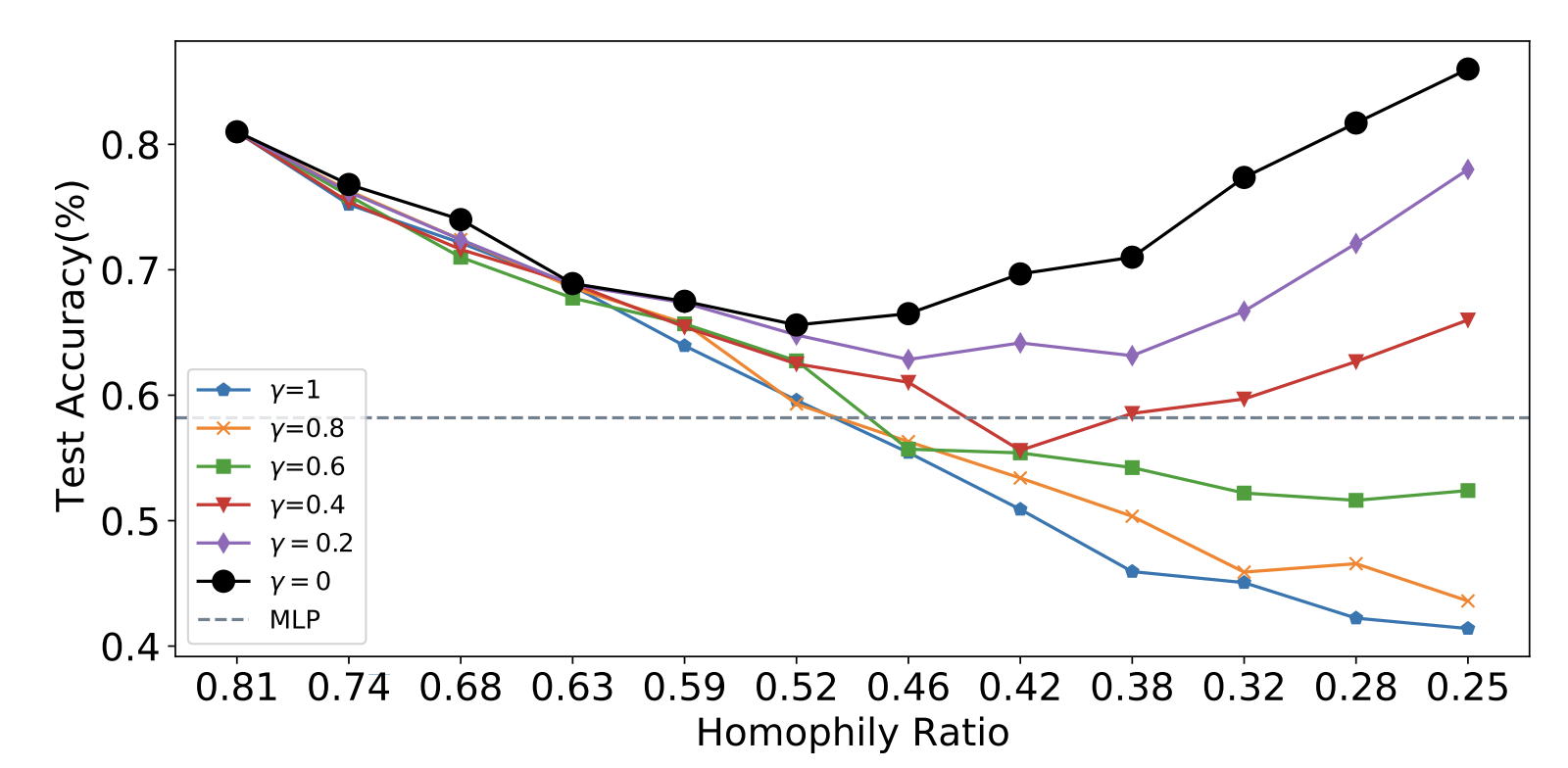 Is Homophily a Necessity for Graph Neural Networks?Yao Ma, Xiaorui Liu, Neil Shah, and Jiliang TangIn International Conference on Learning Representations, 2022
Is Homophily a Necessity for Graph Neural Networks?Yao Ma, Xiaorui Liu, Neil Shah, and Jiliang TangIn International Conference on Learning Representations, 2022Graph neural networks (GNNs) have shown great prowess in learning representations suitable for numerous graph-based machine learning tasks. When applied to semi-supervised node classification, GNNs are widely believed to work well due to the homophily assumption ("like attracts like"), and fail to generalize to heterophilous graphs where dissimilar nodes connect. Recent works design new architectures to overcome such heterophily-related limitations, citing poor baseline performance and new architecture improvements on a few heterophilous graph benchmark datasets as evidence for this notion. In our experiments, we empirically find that standard graph convolutional networks (GCNs) can actually achieve better performance than such carefully designed methods on some commonly used heterophilous graphs. This motivates us to reconsider whether homophily is truly necessary for good GNN performance. We find that this claim is not quite true, and in fact, GCNs can achieve strong performance on heterophilous graphs under certain conditions. Our work carefully characterizes these conditions, and provides supporting theoretical understanding and empirical observations. Finally, we examine existing heterophilous graphs benchmarks and reconcile how the GCN (under)performs on them based on this understanding.
- ICLR
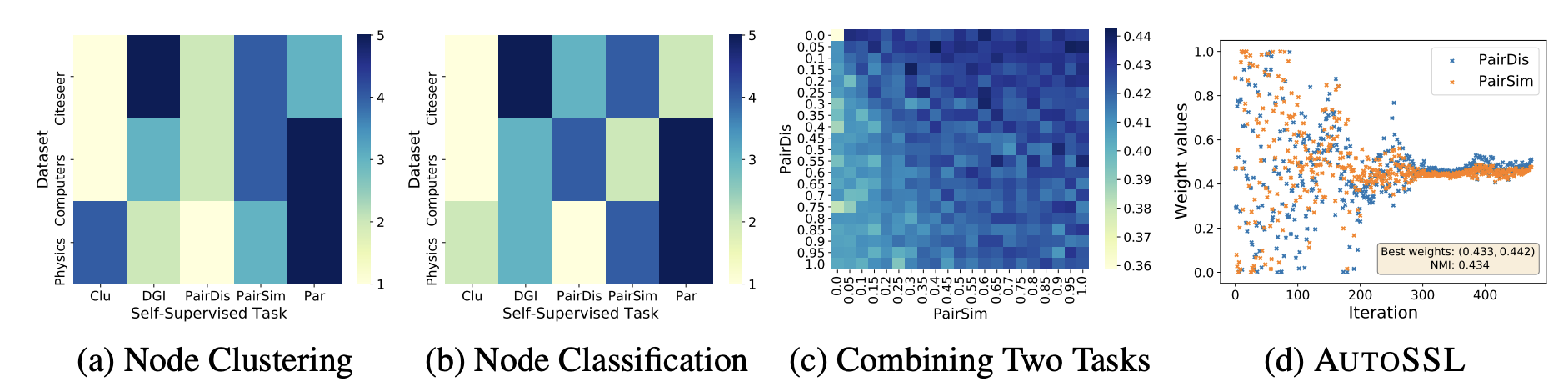 Automated Self-Supervised Learning for GraphsWei Jin, Xiaorui Liu, Xiaoyu Zhao, Yao Ma, Neil Shah, and Jiliang TangIn International Conference on Learning Representations, 2022
Automated Self-Supervised Learning for GraphsWei Jin, Xiaorui Liu, Xiaoyu Zhao, Yao Ma, Neil Shah, and Jiliang TangIn International Conference on Learning Representations, 2022Graph self-supervised learning has gained increasing attention due to its capacity to learn expressive node representations. Many pretext tasks, or loss functions have been designed from distinct perspectives. However, we observe that different pretext tasks affect downstream tasks differently cross datasets, which suggests that searching pretext tasks is crucial for graph self-supervised learning. Different from existing works focusing on designing single pretext tasks, this work aims to investigate how to automatically leverage multiple pretext tasks effectively. Nevertheless, evaluating representations derived from multiple pretext tasks without direct access to ground truth labels makes this problem challenging. To address this obstacle, we make use of a key principle of many real-world graphs, i.e., homophily, or the principle that "like attracts like," as the guidance to effectively search various self-supervised pretext tasks. We provide theoretical understanding and empirical evidence to justify the flexibility of homophily in this search task. Then we propose the AutoSSL framework which can automatically search over combinations of various self-supervised tasks. By evaluating the framework on 7 real-world datasets, our experimental results show that AutoSSL can significantly boost the performance on downstream tasks including node clustering and node classification compared with training under individual tasks. Code is released at https://github.com/ChandlerBang/AutoSSL.
- WSDM
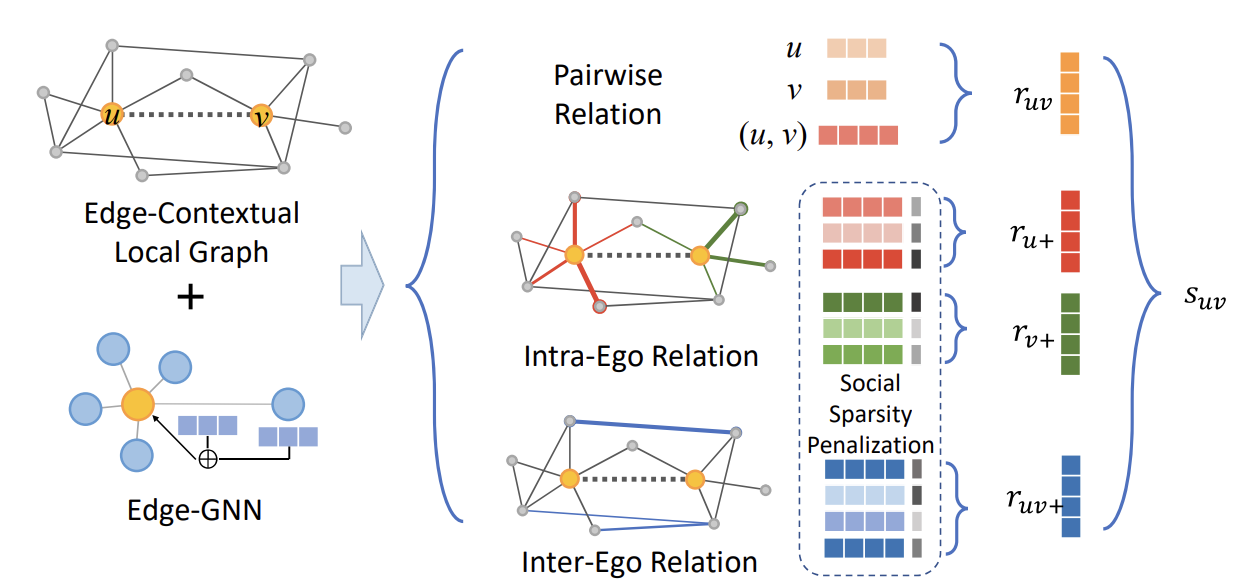 Ranking Friend Stories on Social Platforms with Edge-Contextual Local Graph ConvolutionsXianfeng Tang, Yozen Liu, Xinran He, Suhang Wang, and Neil ShahIn ACM International Conference on Web Search and Data Mining, 2022
Ranking Friend Stories on Social Platforms with Edge-Contextual Local Graph ConvolutionsXianfeng Tang, Yozen Liu, Xinran He, Suhang Wang, and Neil ShahIn ACM International Conference on Web Search and Data Mining, 2022Social platforms have paved the way in creating new, modern ways for users to communicate with each other. In recent years, multiple platforms have introduced ”Stories” features, which enable broadcasting of ephemeral multimedia content. Specifically, ”Friend Stories,” or Stories meant to be consumed by one’s close friends, are a popular feature, promoting significant user-user interactions by allowing people to see (visually) what their friends and family are up to. A key challenge in surfacing Friend Stories for a given user, is in ranking over each viewing user’s friends to efficiently prioritize and route limited user attention. In this work, we explore the novel problem of Friend Story Ranking from a graph representation learning perspective. More generally, our problem is a link ranking task, where inferences are made over existing links (relations), unlike common node or graph-based tasks, or link prediction tasks, where the goal is to make inferences about non-existing links. We propose ELR, an edge-contextual approach which carefully considers local graph structure, differences between local edge types and directionality, and rich edge attributes, building on the backbone of graph convolutions. ELR handles social sparsity challenges by considering and attending over neighboring nodes, and incorporating multiple edge types in local surrounding egonet structures. We validate ELR on two large country-level datasets with millions of users and tens of millions of links from Snapchat. ELR shows superior performance over alternatives by 8% and 5% error reduction measured by MSE and MAE correspondingly. Further generality, data efficiency and ablation experiments confirm the advantages of ELR.
- WSDM
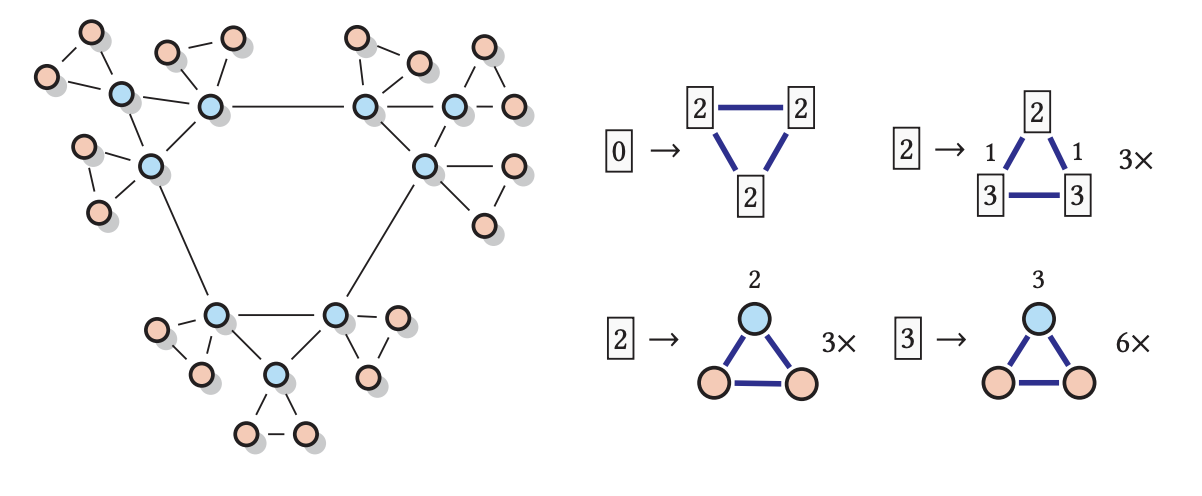 Attributed Graph Modeling with Vertex Replacement GrammarsSatyaki Sikdar, Neil Shah, and Tim WeningerIn ACM International Conference on Web Search and Data Mining, 2022
Attributed Graph Modeling with Vertex Replacement GrammarsSatyaki Sikdar, Neil Shah, and Tim WeningerIn ACM International Conference on Web Search and Data Mining, 2022Recent work at the intersection of formal language theory and graph theory has explored graph grammars for graph modeling. However, existing models and formalisms can only operate on homogeneous (i.e., untyped or unattributed) graphs. We relax this restriction and introduce the Attributed Vertex Replacement Grammar (AVRG), which can be efficiently extracted from heterogeneous (i.e., typed, colored, or attributed) graphs. Unlike current state-of-the-art methods, which train enormous models over complicated deep neural architectures, the AVRG model is unsupervised and interpretable. It is based on context-free string grammars and works by encoding graph rewriting rules into a graph grammar containing graphlets and instructions on how they fit together. We show that the AVRG can encode succinct models of input graphs yet faithfully preserve their structure and assortativity properties. Experiments on large real-world datasets show that graphs generated from the AVRG model exhibit substructures and attribute configurations that match those found in the input networks.
- WSDM
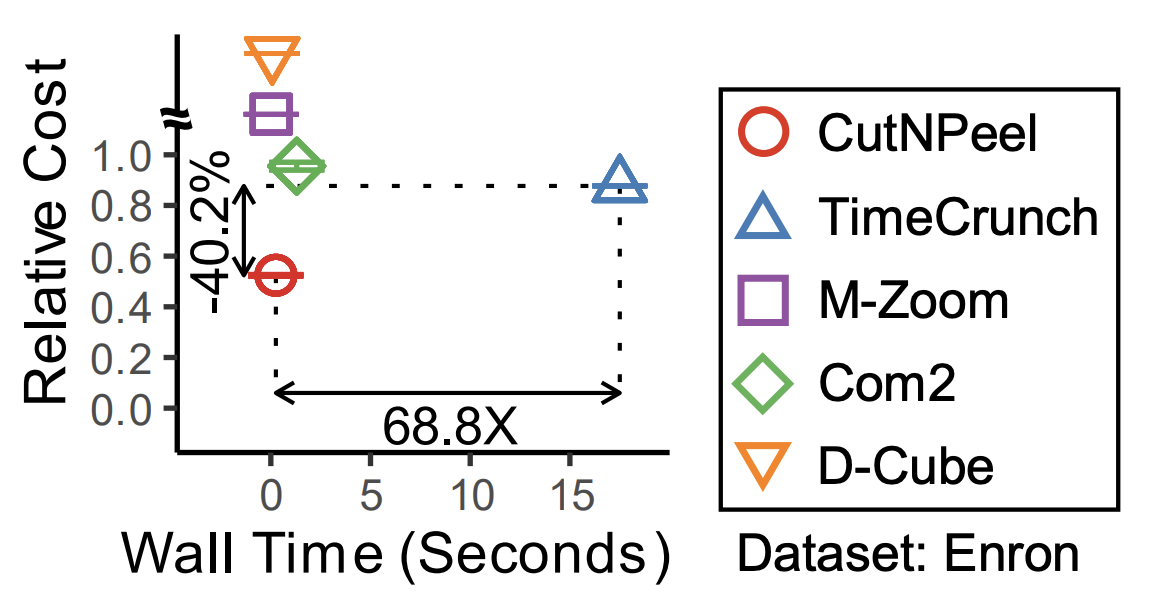 Finding a Concise, Precise and Exhaustive Set of Near Bi-Cliques in Dynamic GraphsHyeonjeong Shin, Taehyung Kwon, Neil Shah, and Kijung ShinIn ACM International Conference on Web Search and Data Mining, 2022
Finding a Concise, Precise and Exhaustive Set of Near Bi-Cliques in Dynamic GraphsHyeonjeong Shin, Taehyung Kwon, Neil Shah, and Kijung ShinIn ACM International Conference on Web Search and Data Mining, 2022A variety of tasks on dynamic graphs, including anomaly detection, community detection, compression, and graph understanding, have been formulated as problems of identifying constituent (near) bi-cliques (i.e., complete bipartite graphs). Even when we restrict our attention to maximal ones, there can be exponentially many near bi-cliques, and thus finding all of them is practically impossible for large graphs. Then, two questions naturally arise: (Q1) What is a "good" set of near bi-cliques? That is, given a set of near bi-cliques in the input dynamic graph, how should we evaluate its quality? (Q2) Given a large dynamic graph, how can we rapidly identify a high-quality set of near bi-cliques in it? Regarding Q1, we measure how concisely, precisely, and exhaustively a given set of near bi-cliques describes the input dynamic graph. We combine these three perspectives systematically on the Minimum Description Length principle. Regarding Q2, we propose CutNPeel, a fast search algorithm for a high-quality set of near bi-cliques. By adaptively re-partitioning the input graph, CutNPeel reduces the search space and at the same time improves the search quality. Our experiments using six real-world dynamic graphs demonstrate that CutNPeel is (a) High-quality: providing near bi-cliques of up to 51.2% better quality than its state-of-the-art competitors, (b) Fast: up to 68.8x faster than the next-best competitor, and (c) Scalable: scaling to graphs with 134 million edges. We also show successful applications of CutNPeel to graph compression and pattern discovery.
2021
- CIKM
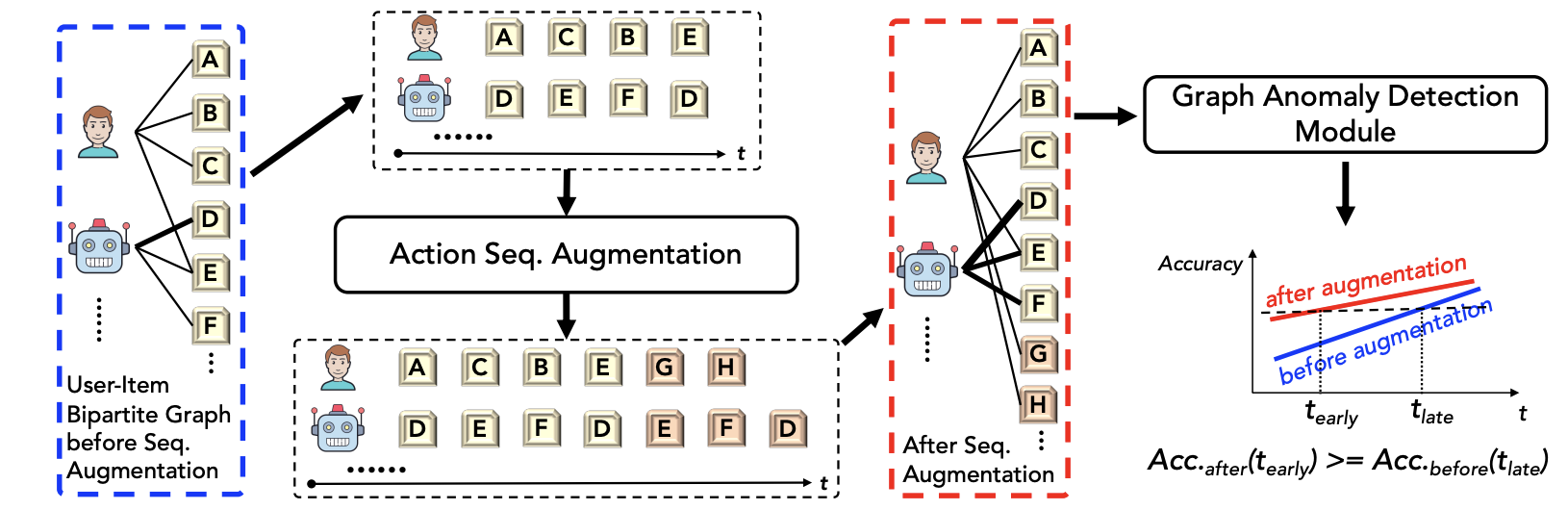 Action Sequence Augmentation for Early Graph-based Anomaly DetectionTong Zhao, Bo Ni, Wenhao Yu, Zhichun Guo, Neil Shah, and Meng JiangIn ACM International Conference on Information and Knowledge Management, 2021
Action Sequence Augmentation for Early Graph-based Anomaly DetectionTong Zhao, Bo Ni, Wenhao Yu, Zhichun Guo, Neil Shah, and Meng JiangIn ACM International Conference on Information and Knowledge Management, 2021The proliferation of web platforms has created incentives for online abuse. Many graph-based anomaly detection techniques are proposed to identify the suspicious accounts and behaviors. However, most of them detect the anomalies once the users have performed many such behaviors. Their performance is substantially hindered when the users’ observed data is limited at an early stage, which needs to be improved to minimize financial loss. In this work, we propose Eland, a novel framework that uses action sequence augmentation for early anomaly detection. Eland utilizes a sequence predictor to predict next actions of every user and exploits the mutual enhancement between action sequence augmentation and user-action graph anomaly detection. Experiments on three real-world datasets show that Eland improves the performance of a variety of graph-based anomaly detection methods. With Eland, anomaly detection performance at an earlier stage is better than non-augmented methods that need significantly more observed data by up to 15% on the Area under the ROC curve.
- CIKM
 A Unified View on Graph Neural Networks as Graph Signal DenoisingYao Ma, Xiaorui Liu, Tong Zhao, Yozen Liu, Jiliang Tang, and Neil ShahIn ACM International Conference on Information and Knowledge Management, 2021
A Unified View on Graph Neural Networks as Graph Signal DenoisingYao Ma, Xiaorui Liu, Tong Zhao, Yozen Liu, Jiliang Tang, and Neil ShahIn ACM International Conference on Information and Knowledge Management, 2021Graph Neural Networks (GNNs) have risen to prominence in learning representations for graph structured data. A single GNN layer typically consists of a feature transformation and a feature aggregation operation. The former normally uses feed-forward networks to transform features, while the latter aggregates the transformed features over the graph. Numerous recent works have proposed GNN models with different designs in the aggregation operation. In this work, we establish mathematically that the aggregation processes in a group of representative GNN models including GCN, GAT, PPNP, and APPNP can be regarded as (approximately) solving a graph denoising problem with a smoothness assumption. Such a unified view across GNNs not only provides a new perspective to understand a variety of aggregation operations but also enables us to develop a unified graph neural network framework UGNN. To demonstrate its promising potential, we instantiate a novel GNN model, ADA-UGNN, derived from UGNN, to handle graphs with adaptive smoothness across nodes. Comprehensive experiments show the effectiveness of ADA-UGNN.
- CIKM
 Niche Detection in User Content Consumption DataEkta Gujral, Leonardo Neves, Evangelos Papalexakis, and Neil ShahIn ACM International Conference on Information and Knowledge Management, 2021
Niche Detection in User Content Consumption DataEkta Gujral, Leonardo Neves, Evangelos Papalexakis, and Neil ShahIn ACM International Conference on Information and Knowledge Management, 2021Explainable machine learning methods have attracted increased interest in recent years. In this work, we pose and study the niche detection problem, which imposes an explainable lens on the classical problem of co-clustering interactions across two modes. In the niche detection problem, our goal is to identify niches, or co-clusters with node-attribute oriented explanations. Niche detection is applicable to many social content consumption scenarios, where an end goal is to describe and distill high-level insights about user-content associations: not only that certain users like certain types of content, but rather the types of users and content, explained via node attributes. Some examples are an e-commerce platform with who-buys-what interactions and user and product attributes, or a mobile call platform with who-calls-whom interactions and user attributes. Discovering and characterizing niches has powerful implications for user behavior understanding, as well as marketing and targeted content production. Unlike prior works, ours focuses on the intersection of explainable methods and co-clustering. First, we formalize the niche detection problem and discuss preliminaries. Next, we design an end-to-end framework, NED, which operates in two steps: discovering co-clusters of user behaviors based on interaction densities, and explaining them using attributes of involved nodes. Finally, we show experimental results on several public datasets, as well as a large-scale industrial dataset from Snapchat, demonstrating that NED improves in both co-clustering (20% accuracy) and explanation-related objectives (12% average precision) compared to state-of-the-art methods.
- TNNLS
 A Synergistic Approach for Graph Anomaly Detection with Pattern Mining and Feature LearningTong Zhao, Tianwen Jiang, Neil Shah, and Meng JiangIn IEEE Transactions on Neural Networks and Learning Systems, 2021
A Synergistic Approach for Graph Anomaly Detection with Pattern Mining and Feature LearningTong Zhao, Tianwen Jiang, Neil Shah, and Meng JiangIn IEEE Transactions on Neural Networks and Learning Systems, 2021Detecting anomalies on graph data has two types of methods. One is pattern mining that discovers strange structures globally such as quasi-cliques, bipartite cores, or dense blocks in the graph’s adjacency matrix. The other is feature learning that mainly uses graph neural networks (GNNs) to aggregate information from local neighborhood into node representations. However, there is a lack of study that utilizes both the global and local information for graph anomaly detection. In this article, we propose a synergistic approach that leverages pattern mining to inform the GNN algorithms on how to aggregate local information through connections to capture the global patterns. Specifically, it uses a GNN encoder to perform feature aggregation, and the pattern mining algorithms supervise the GNN training process through a novel loss function. We provide theoretical analysis on the effectiveness of the loss function, as well as empirical analysis on the proposed approach across a variety of GNN algorithms and pattern mining methods. Experiments on real-world data show that the synergistic approach performs significantly better than existing graph anomaly detection methods.
- AIES
 FairOD: Fairness-aware Outlier DetectionShubhranshu Shekhar, Neil Shah, and Leman AkogluIn AAAI/ACM Conference on Artificial Intelligence, Ethics, and Society, 2021
FairOD: Fairness-aware Outlier DetectionShubhranshu Shekhar, Neil Shah, and Leman AkogluIn AAAI/ACM Conference on Artificial Intelligence, Ethics, and Society, 2021Fairness and Outlier Detection (OD) are closely related, as it is exactly the goal of OD to spot rare, minority samples in a given population. However, when being a minority (as defined by protected variables, such as race/ethnicity/sex/age) does not reflect positive-class membership (such as criminal/fraud), OD produces unjust outcomes. Surprisingly, fairness-aware OD has been almost untouched in prior work, as fair machine learning literature mainly focuses on supervised settings. Our work aims to bridge this gap. Specifically, we develop desiderata capturing well-motivated fairness criteria for OD, and systematically formalize the fair OD problem. Further, guided by our desiderata, we propose FairOD, a fairness-aware outlier detector that has the following desirable properties: FairOD (1) exhibits treatment parity at test time, (2) aims to flag equal proportions of samples from all groups (i.e. obtain group fairness, via statistical parity), and (3) strives to flag truly high-risk samples within each group. Extensive experiments on a diverse set of synthetic and real world datasets show that FairOD produces outcomes that are fair with respect to protected variables, while performing comparable to (and in some cases, even better than) fairness-agnostic detectors in terms of detection performance.
- ICWSM
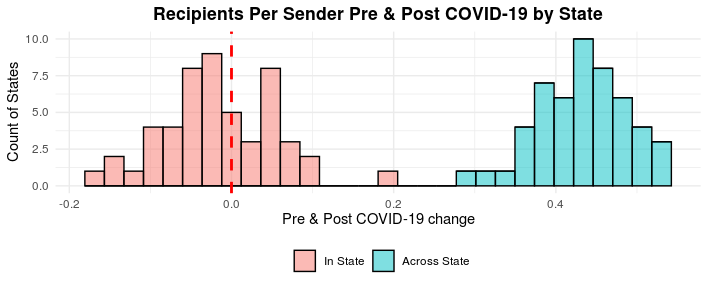 Online Communication Shifts in the Midst of the Covid-19 Pandemic: A Case Study on SnapchatQi Yang, Weinan Wang, Lucas Pierce, Rajan Vaish, Xiaolin Shi, and Neil ShahIn AAAI International Conference on Web and Social Media, 2021
Online Communication Shifts in the Midst of the Covid-19 Pandemic: A Case Study on SnapchatQi Yang, Weinan Wang, Lucas Pierce, Rajan Vaish, Xiaolin Shi, and Neil ShahIn AAAI International Conference on Web and Social Media, 2021The Covid-19 pandemic has created large shifts in how people stay connected with each other in lieu of social distancing and isolation measures. More and more, individuals have turned to online communications as a necessary replacement for in-person interaction. Despite this, the research community has little understanding of how online communications have been influenced by the offline impacts of Covid-19. Our work touches upon this topic. Specifically, we study research questions around the impact of Covid-19 on online public and private sharing propensity, its influence on online communication homophily, and correlations between online communication and offline case severity in the United States. To do so, we study the usage patterns of 79 million US-based users on Snapchat, a large, leading mobile multimedia-driven social sharing platform. Our findings suggest that Covid-19 has increased propensity to privately communicate with friends, while decreasing propensity to publicly share content when users are out-and-about. Moreover, online communications have observed a marked decrease in baseline homophily across locations, ages and genders, with relative increases in cross-group communications. Finally, we observe that increased offline positive Covid-19 case severity in US states is associated with widening gaps between across-state and within-state communication increases after the onset of Covid-19, as well as marked declines in public sharing. We hope our findings drive further interest and work on online communication changes during pandemics and other extended times of crisis.
- ICWSM
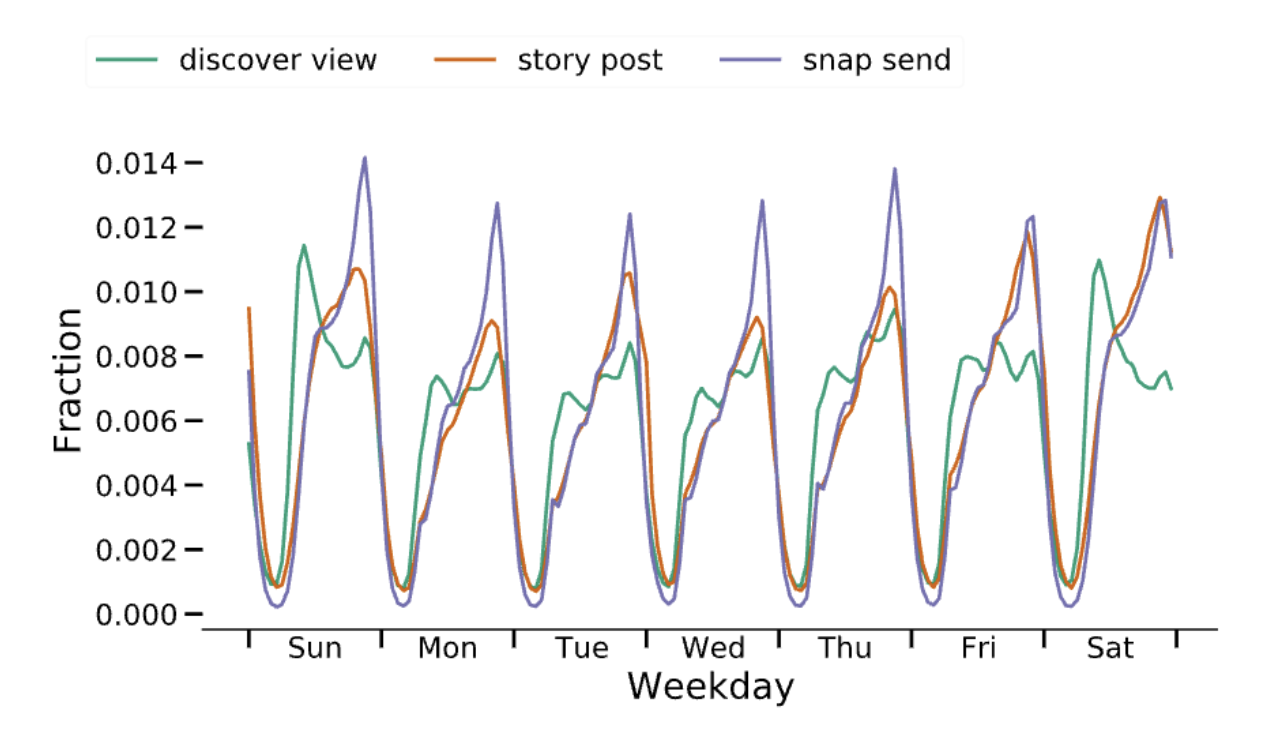 CEAM: The Effectiveness of Cyclic and Ephemeral Attention Models of User Behavior on Social PlatformsFarhan Asif Chowdhury, Yozen Liu, Koustuv Saha, Nicholas Vincent, Leonardo Neves, Neil Shah, and Maarten BosIn AAAI International Conference on Web and Social Media, 2021
CEAM: The Effectiveness of Cyclic and Ephemeral Attention Models of User Behavior on Social PlatformsFarhan Asif Chowdhury, Yozen Liu, Koustuv Saha, Nicholas Vincent, Leonardo Neves, Neil Shah, and Maarten BosIn AAAI International Conference on Web and Social Media, 2021To improve the user experience as well as business outcomes, social platforms aim to predict user behavior. To this end, recurrent models are often used to predict a user’s next behavior based on their most recent behavior. However, people have habits and routines, making it plausible to predict their behavior from more than just their most recent activity. Our work focuses on the interplay between ephemeral and cyclical components of user behaviors. By utilizing user activity data from social platform Snapchat, we uncover cyclic and ephemeral usage patterns on a per user level. Based on our findings, we imbued recurrent models with awareness: we augment an RNN with a cyclic module to complement traditional RNNs that model ephemeral behaviors and allow a flexible weighting of the two for the prediction task. We conducted extensive experiments to evaluate our model’s performance on four user behavior prediction tasks on the Snapchat platform. We achieve improved results on each task compared against existing methods, using this simple, but important insight in user behavior: Both cyclical and ephemeral components matter. We show that in some situations and for some people, ephemeral components may be more helpful for predicting behavior, while for others and in other situations, cyclical components may carry more weight.
- WWW
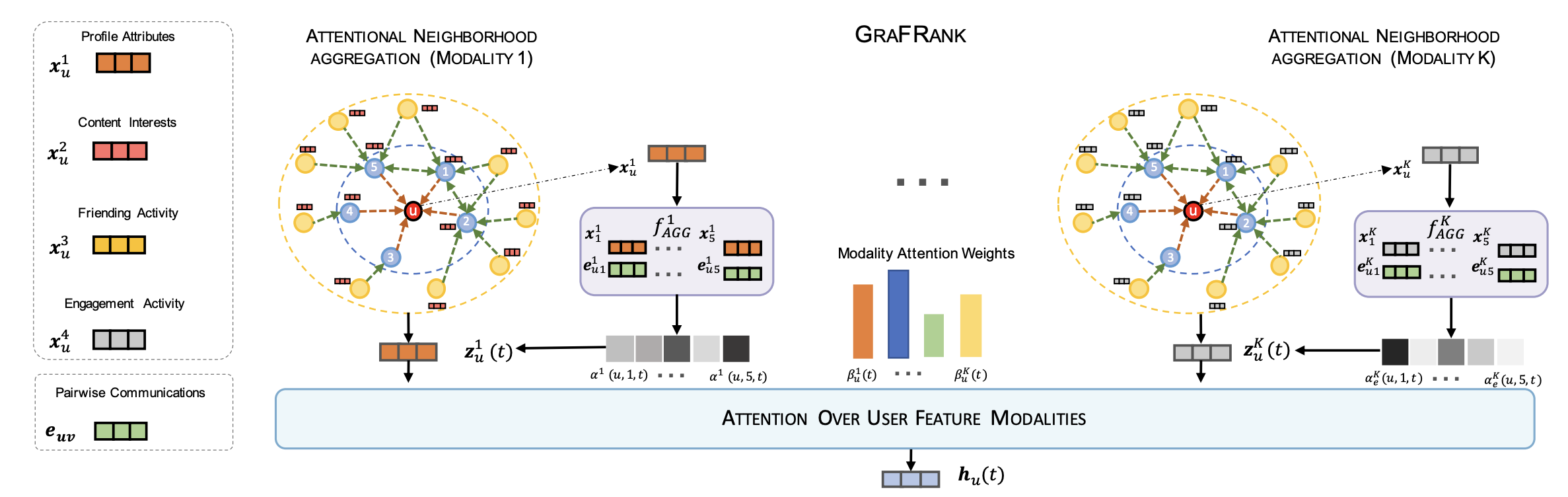 Graph Neural Networks for Friend Ranking in Large-scale Social PlatformsAravind Sankar, Yozen Liu, Jun Yu, and Neil ShahIn The Web Conference, 2021
Graph Neural Networks for Friend Ranking in Large-scale Social PlatformsAravind Sankar, Yozen Liu, Jun Yu, and Neil ShahIn The Web Conference, 2021Graph Neural Networks (GNNs) have recently enabled substantial advances in graph learning. Despite their rich representational capacity, GNNs remain under-explored for large-scale social modeling applications. One such industrially ubiquitous application is friend suggestion: recommending users other candidate users to befriend, to improve user connectivity, retention and engagement. However, modeling such user-user interactions on large-scale social platforms poses unique challenges: such graphs often have heavy-tailed degree distributions, where a significant fraction of users are inactive and have limited structural and engagement information. Moreover, users interact with different functionalities, communicate with diverse groups, and have multifaceted interaction patterns. We study the application of GNNs for friend suggestion, providing the first investigation of GNN design for this task, to our knowledge. To leverage the rich knowledge of in-platform actions, we formulate friend suggestion as multi-faceted friend ranking with multi-modal user features and link communication features. We design a neural architecture GraFRank to learn expressive user representations from multiple feature modalities and user-user interactions. Specifically, GraFRank employs modality-specific neighbor aggregators and cross-modality attentions to learn multi-faceted user representations. We conduct experiments on two multi-million user datasets from Snapchat, a leading mobile social platform, where GraFRank outperforms several state-of-the-art approaches on candidate retrieval (by 30% MRR) and ranking (by 20% MRR) tasks. Moreover, our qualitative analysis indicates notable gains for critical populations of less-active and low-degree users.
- CHI
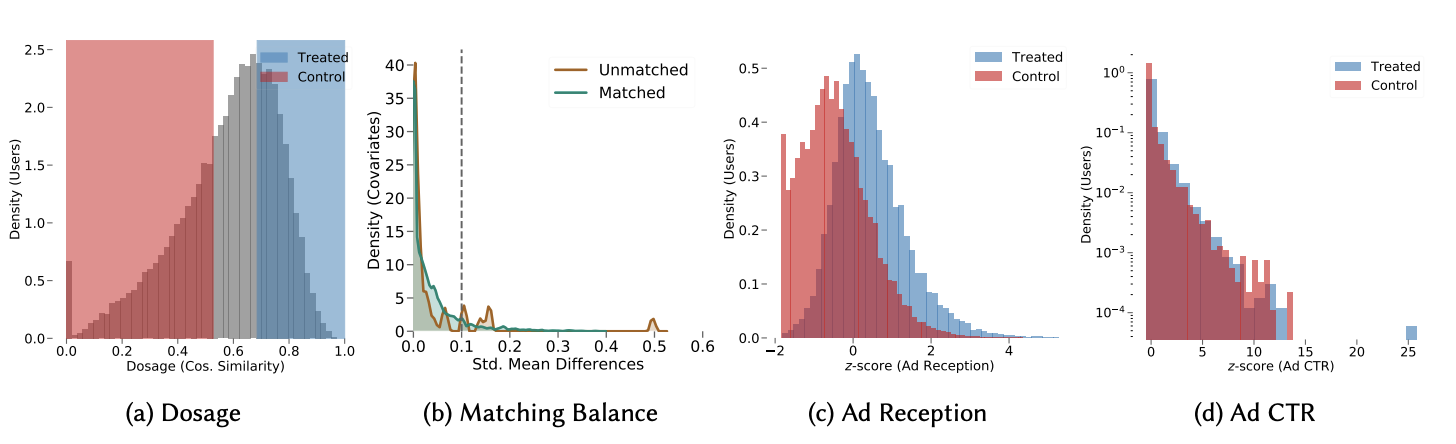 AdverTiming Matters: Examining User Ad Consumption for Effective Ad Allocations on Social MediaKoustuv Saha, Yozen Liu, Nicholas Vincent, Farhan Asif Chowdhury, Leonardo Neves, Neil Shah, and Maarten BosIn ACM SIGCHI Conference on Human Factors in Computing Systems, 2021
AdverTiming Matters: Examining User Ad Consumption for Effective Ad Allocations on Social MediaKoustuv Saha, Yozen Liu, Nicholas Vincent, Farhan Asif Chowdhury, Leonardo Neves, Neil Shah, and Maarten BosIn ACM SIGCHI Conference on Human Factors in Computing Systems, 2021Showing ads delivers revenue for online content distributors, but ad exposure can compromise user experience and cause user fatigue and frustration. Correctly balancing ads with other content is imperative. Currently, ad allocation relies primarily on demographics and inferred user interests, which are treated as static features and can be privacy-intrusive. This paper uses person-centric and momentary context features to understand optimal ad-timing. In a quasi-experimental study on a three-month longitudinal dataset of 100K Snapchat users, we find ad timing influences ad effectiveness. We draw insights on the relationship between ad effectiveness and momentary behaviors such as duration, interactivity, and interaction diversity. We simulate ad reallocation, finding that our study-driven insights lead to greater value for the platform. This work advances our understanding of ad consumption and bears implications for designing responsible ad allocation systems, improving both user and platform outcomes. We discuss privacy-preserving components and ethical implications of our work.
- AAAI
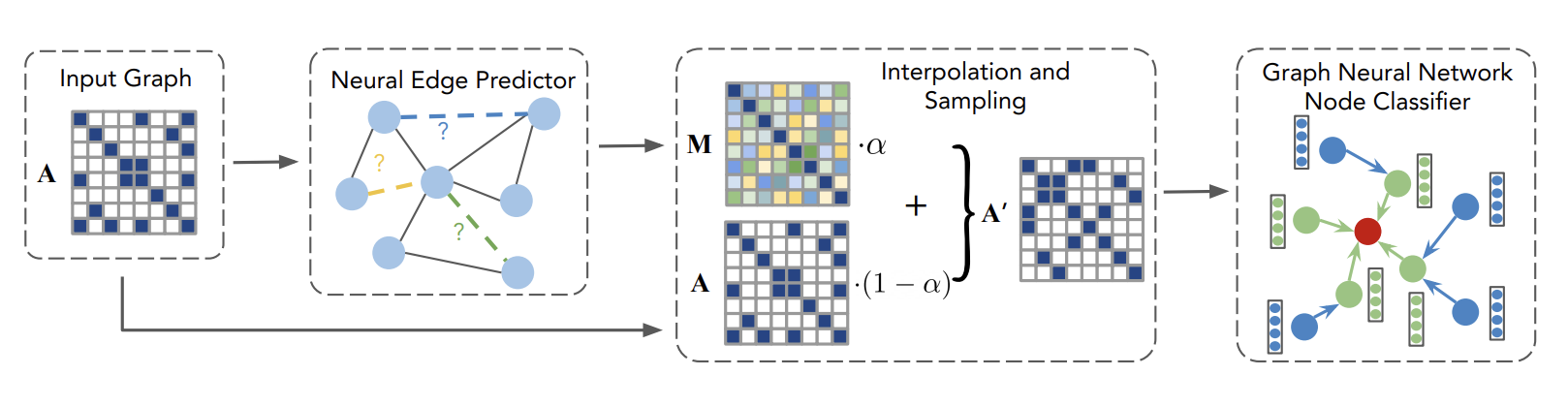 Data Augmentation for Graph Neural NetworksTong Zhao, Yozen Liu, Leonardo Neves, Oliver Woodford, Meng Jiang, and Neil ShahIn AAAI Conference on Artificial Intelligence, 2021
Data Augmentation for Graph Neural NetworksTong Zhao, Yozen Liu, Leonardo Neves, Oliver Woodford, Meng Jiang, and Neil ShahIn AAAI Conference on Artificial Intelligence, 2021Data augmentation has been widely used to improve generalizability of machine learning models. However, comparatively little work studies data augmentation for graphs. This is largely due to the complex, non-Euclidean structure of graphs, which limits possible manipulation operations. Augmentation operations commonly used in vision and language have no analogs for graphs. Our work studies graph data augmentation for graph neural networks (GNNs) in the context of improving semi-supervised node-classification. We discuss practical and theoretical motivations, considerations and strategies for graph data augmentation. Our work shows that neural edge predictors can effectively encode class-homophilic structure to promote intra-class edges and demote inter-class edges in given graph structure, and our main contribution introduces the GAug graph data augmentation framework, which leverages these insights to improve performance in GNN-based node classification via edge prediction. Extensive experiments on multiple benchmarks show that augmentation via GAug improves performance across GNN architectures and datasets.
- ICWSM
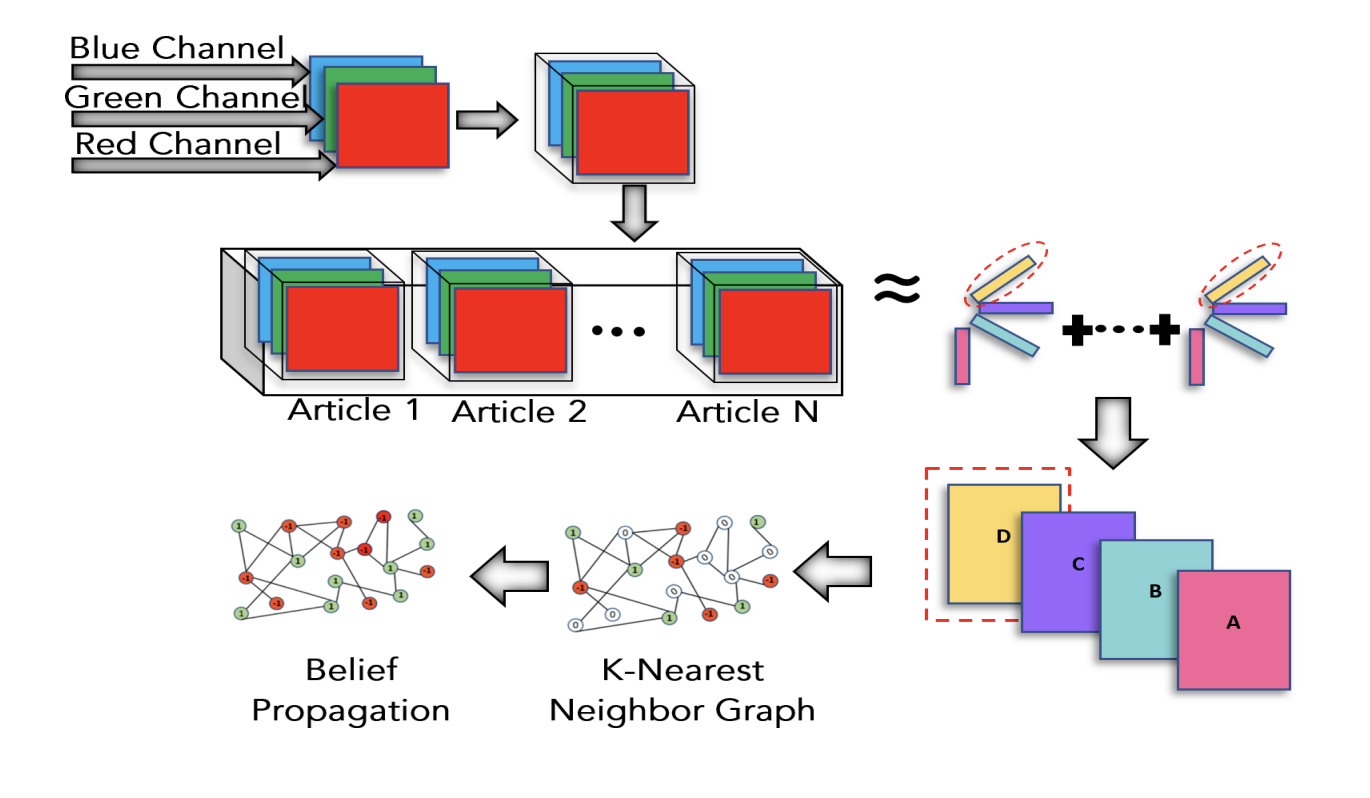 Identifying Misinformation from Website ScreenshotsSara Abdali, Rutuja Gurav, Siddharth Menon, Daniel Fonseca, Negin Entezari, Neil Shah, and Evangelos PapalexakisIn AAAI International Conference on Web and Social Media, 2021
Identifying Misinformation from Website ScreenshotsSara Abdali, Rutuja Gurav, Siddharth Menon, Daniel Fonseca, Negin Entezari, Neil Shah, and Evangelos PapalexakisIn AAAI International Conference on Web and Social Media, 2021Can the look and the feel of a website give information about the trustworthiness of an article? In this paper, we propose to use a promising, yet neglected aspect in detecting the misinformativeness: the overall look of the domain webpage. To capture this overall look, we take screenshots of news articles served by either misinformative or trustworthy web domains and leverage a tensor decomposition based semi-supervised classification technique. The proposed approach i.e., VizFake is insensitive to a number of image transformations such as converting the image to grayscale, vectorizing the image and losing some parts of the screenshots. VizFake leverages a very small amount of known labels, mirroring realistic and practical scenarios, where labels (especially for known misinformative articles), are scarce and quickly become dated. The F1 score of VizFake on a dataset of 50k screenshots of news articles spanning more than 500 domains is roughly 85% using only 5% of ground truth labels. Furthermore, tensor representations of VizFake, obtained in an unsupervised manner, allow for exploratory analysis of the data that provides valuable insights into the problem. Finally, we compare VizFake with deep transfer learning, since it is a very popular black-box approach for image classification and also well-known text text-based methods. VizFake achieves competitive accuracy with deep transfer learning models while being two orders of magnitude faster and not requiring laborious hyper-parameter tuning.
2020
- COLING
 The Devil is in the Details: Evaluating Limitations of Transformer-based Methods for Granular TasksBrihi Joshi, Francesco Barbieri, Neil Shah, and Leonardo NevesIn International Conference on Computational Linguistics, 2020
The Devil is in the Details: Evaluating Limitations of Transformer-based Methods for Granular TasksBrihi Joshi, Francesco Barbieri, Neil Shah, and Leonardo NevesIn International Conference on Computational Linguistics, 2020Contextual embeddings derived from transformer-based neural language models have shown state-of-the-art performance for various tasks such as question answering, sentiment analysis, and textual similarity in recent years. Extensive work shows how accurately such models can represent abstract, semantic information present in text. In this expository work, we explore a tangent direction and analyze such models’ performance on tasks that require a more granular level of representation. We focus on the problem of textual similarity from two perspectives: matching documents on a granular level (requiring embeddings to capture fine-grained attributes in the text), and an abstract level (requiring embeddings to capture overall textual semantics). We empirically demonstrate, across two datasets from different domains, that despite high performance in abstract document matching as expected, contextual embeddings are consistently (and at times, vastly) outperformed by simple baselines like TF-IDF for more granular tasks. We then propose a simple but effective method to incorporate TF-IDF into models that use contextual embeddings, achieving relative improvements of up to 36% on granular tasks.
- CIKM
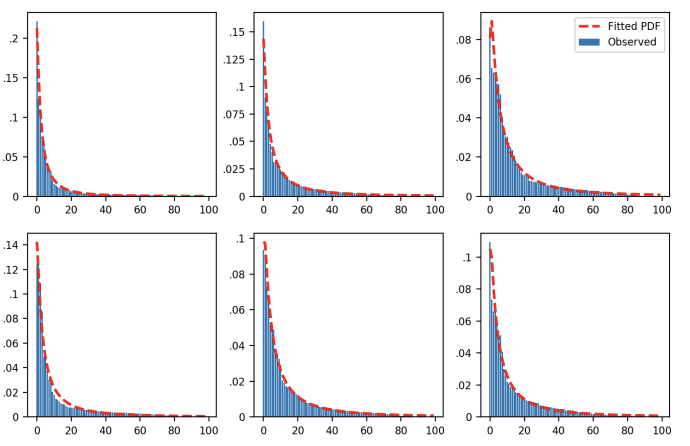 Social Factors in Closed-Network Content ConsumptionParisa Kaghazgaran, Maarten Bos, Leonardo Neves, and Neil ShahIn ACM International Conference on Information and Knowledge Management, 2020
Social Factors in Closed-Network Content ConsumptionParisa Kaghazgaran, Maarten Bos, Leonardo Neves, and Neil ShahIn ACM International Conference on Information and Knowledge Management, 2020How do users on social platforms consume content shared by their friends? Is this consumption socially motivated, and can we predict it? Considerable prior work has focused on inferring and learning user preferences with respect to broadcasted, or open-network content in public spheres like webpages or public videos. However, user engagement with narrowcasted, closed-network content shared by their friends is considerably under-explored, despite being a commonplace activity. Here we bridge this gap by focusing on consumption of visual media content in closed-network settings, using data from Snapchat, a large multimedia-driven social sharing service with over 200M daily active users. Broadly, we answer questions around content consumption patterns, social factors that are associated with such consumption habits, and predictability of consumption time. We propose models for patterns in users’ time-spending behaviors across friends, and observe that viewers preferentially and consistently spend more time on content from certain friends, even without considering any explicit notion of intrinsic content value. We also find that consumption time is highly correlated with several engagement-based social factors, suggesting a large social role in closed-network content consumption. Finally, we propose a novel approach of modeling future consumption time as a learning-to-rank task over users? friends. Our results demonstrate significant predictive value (0.815 P@1, 0.650 nDCG@10) using only social factors. We expect our work to motivate additional research in modeling consumption and ranking of online closed-network content.
- KDD
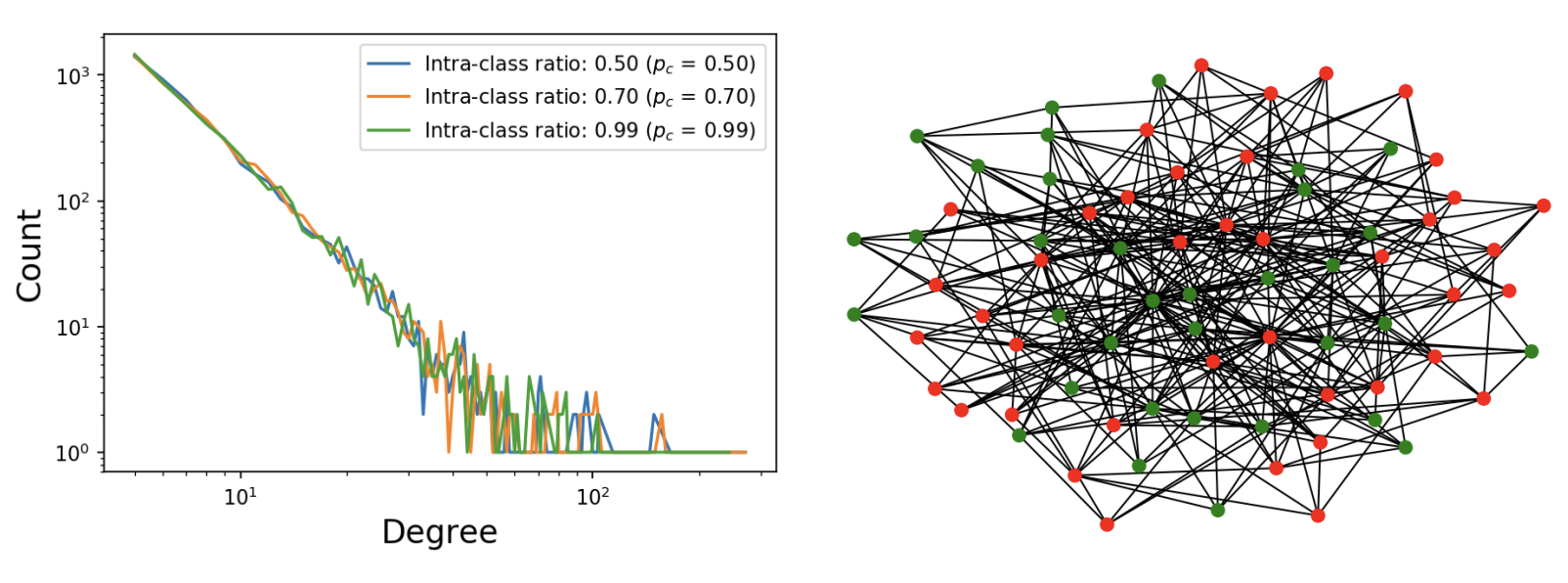 Scale-Free, Attributed and Class-Assortative Graph Generation to Facilitate Introspection of Graph Neural NetworksNeil ShahIn ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2020
Scale-Free, Attributed and Class-Assortative Graph Generation to Facilitate Introspection of Graph Neural NetworksNeil ShahIn ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2020Semi-supervised node classification on graphs is a complex interplay between graph structure, node features and class-assortative (homophily) properties, and the flexibility of a model to capture these nuances. Modern datasets used to push the frontier for these tasks exhibit diverse properties across these fronts, making it challenging to study how these properties individually and jointly influence performance of modern embedding-based methods like graph neural networks (GNNs) for this task. In this work-in-progress, we propose an intuitive and flexible scale-free graph generation model, CaBaM, which enables simulation of class-assortative and attributed graphs via the well-known Barabasi-Albert model. We show empirically and theoretically how our model can easily describe a variety of graph types, while imbuing the generated graphs with the necessary ingredients for attribute, topology, and label-aware semi-supervised node-classification.
- ECML-PKDD
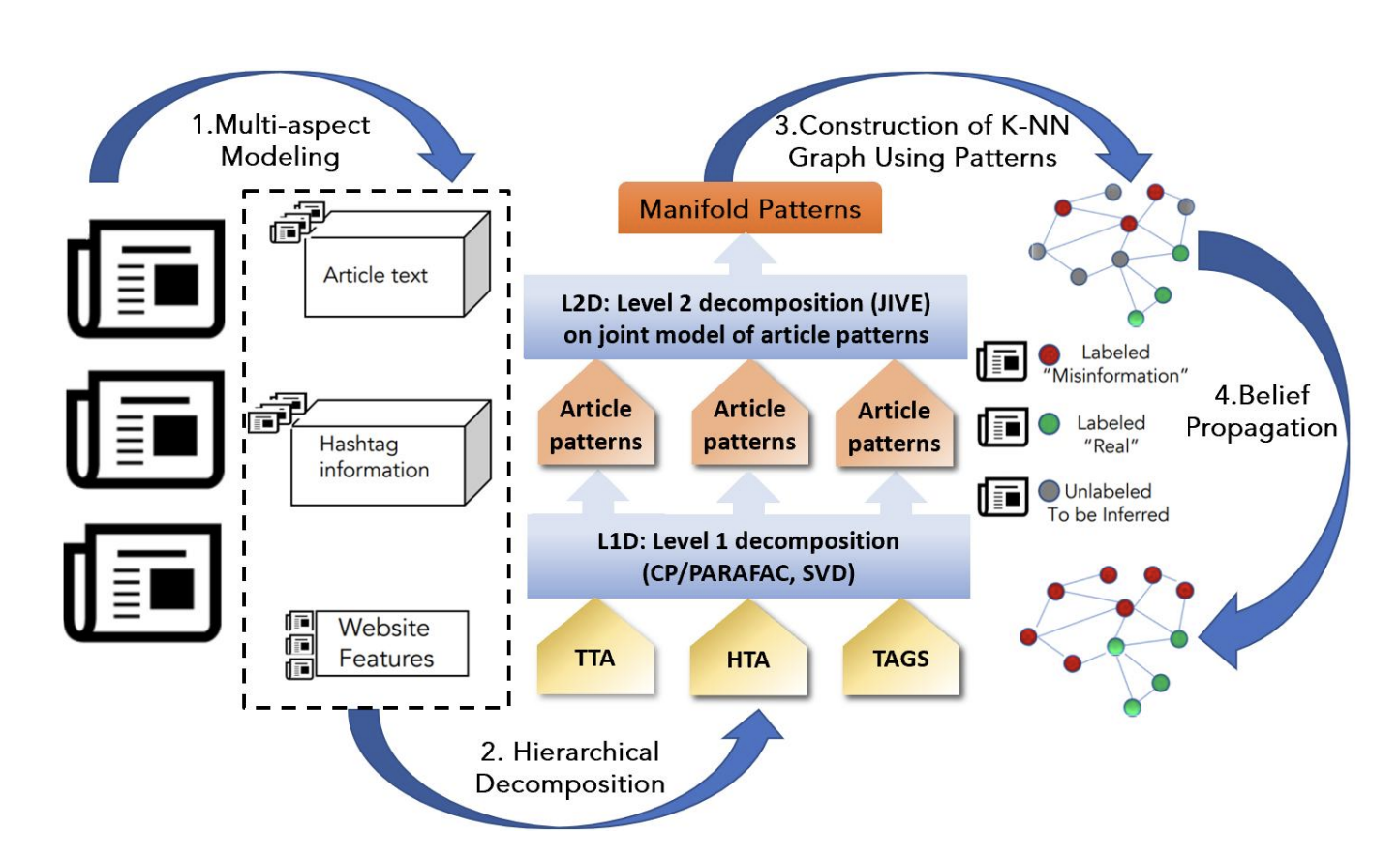 Semi-Supervised Multi-aspect Misinformation Detection with Hierarchical Joint DecompositionSara Abdali, Neil Shah, and Evangelos PapalexakisIn European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases, 2020
Semi-Supervised Multi-aspect Misinformation Detection with Hierarchical Joint DecompositionSara Abdali, Neil Shah, and Evangelos PapalexakisIn European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases, 2020Distinguishing between misinformation and real information is one of the most challenging problems in today’s interconnected world. The vast majority of the state-of-the-art in detecting misinformation is fully supervised, requiring a large number of high-quality human annotations. However, the availability of such annotations cannot be taken for granted, since it is very costly, time-consuming, and challenging to do so in a way that keeps up with the proliferation of misinformation. In this work, we are interested in exploring scenarios where the number of annotations is limited. In such scenarios, we investigate how tapping on a diverse number of resources that characterize a news article, henceforth referred to as "aspects" can compensate for the lack of labels. In particular, our contributions in this paper are twofold: 1) We propose the use of three different aspects: article content, context of social sharing behaviors, and host website/domain features, and 2) We introduce a principled tensor based embedding framework that combines all those aspects effectively. We propose HiJoD a 2-level decomposition pipeline which not only outperforms state-of-the-art methods with F1-scores of 74% and 81% on Twitter and Politifact datasets respectively but also is an order of magnitude faster than similar ensemble approaches.
- KDD
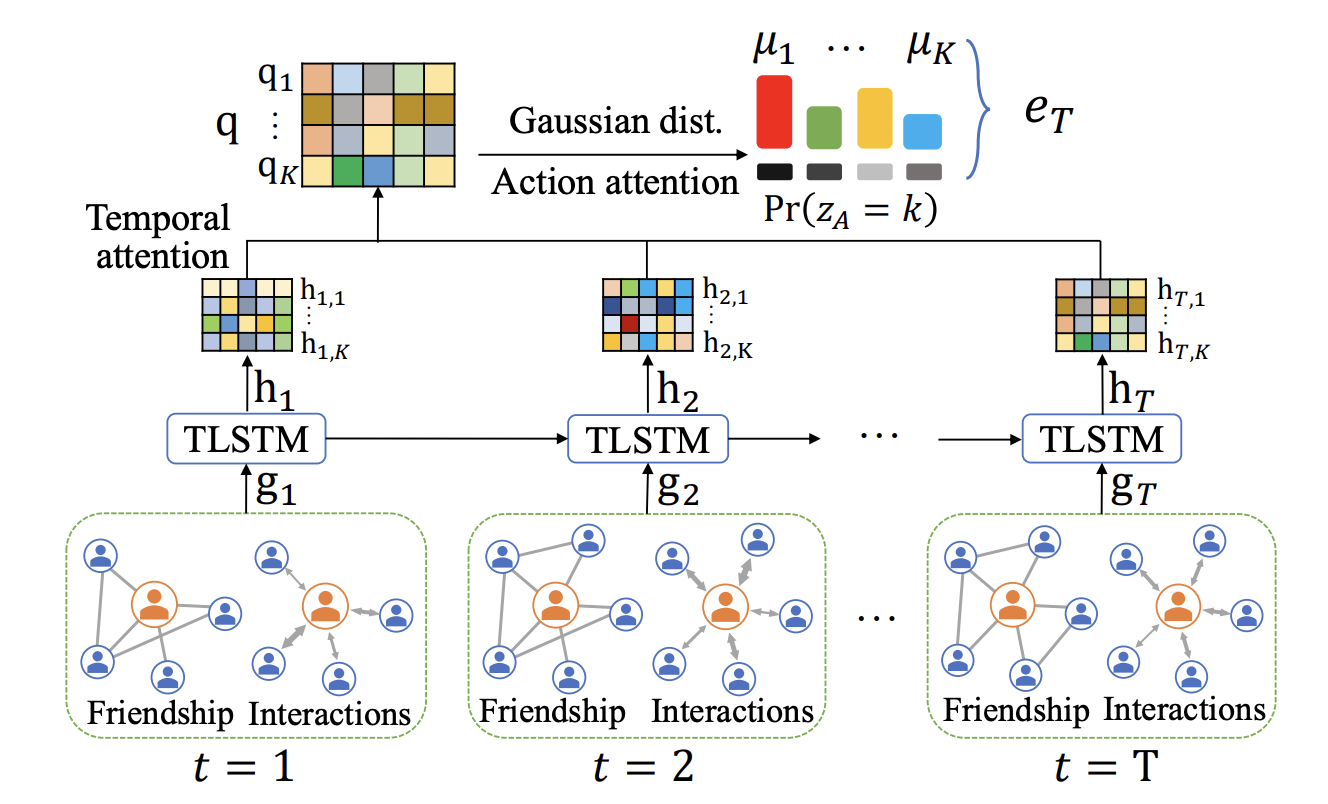 Knowing your FATE: Friendship, Action and Temporal Explanations for User Engagement Prediction on Social AppsXianfeng Tang, Yozen Liu, Neil Shah, Xiaolin Shi, Prasenjit Mitra, and Suhang WangIn ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2020
Knowing your FATE: Friendship, Action and Temporal Explanations for User Engagement Prediction on Social AppsXianfeng Tang, Yozen Liu, Neil Shah, Xiaolin Shi, Prasenjit Mitra, and Suhang WangIn ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2020With the rapid growth and prevalence of social network applications (Apps) in recent years, understanding user engagement has become increasingly important, to provide useful insights for future App design and development. While several promising neural modeling approaches were recently pioneered for accurate user engagement prediction, their black-box designs are unfortunately limited in model explainability. In this paper, we study a novel problem of explainable user engagement prediction for social network Apps. First, we propose a flexible definition of user engagement for various business scenarios, based on future metric expectations. Next, we design an end-to-end neural framework, FATE, which incorporates three key factors that we identify to influence user engagement, namely friendships, user actions, and temporal dynamics to achieve explainable engagement predictions. FATE is based on a tensor-based graph neural network (GNN), LSTM and a mixture attention mechanism, which allows for (a) predictive explanations based on learned weights across different feature categories, (b) reduced network complexity, and (c) improved performance in both prediction accuracy and training/inference time. We conduct extensive experiments on two large-scale datasets from Snapchat, where FATE outperforms state-of-the-art approaches by {≈}10% error and {≈}20% runtime reduction. We also evaluate explanations from FATE, showing strong quantitative and qualitative performance.
2019
- DSAA
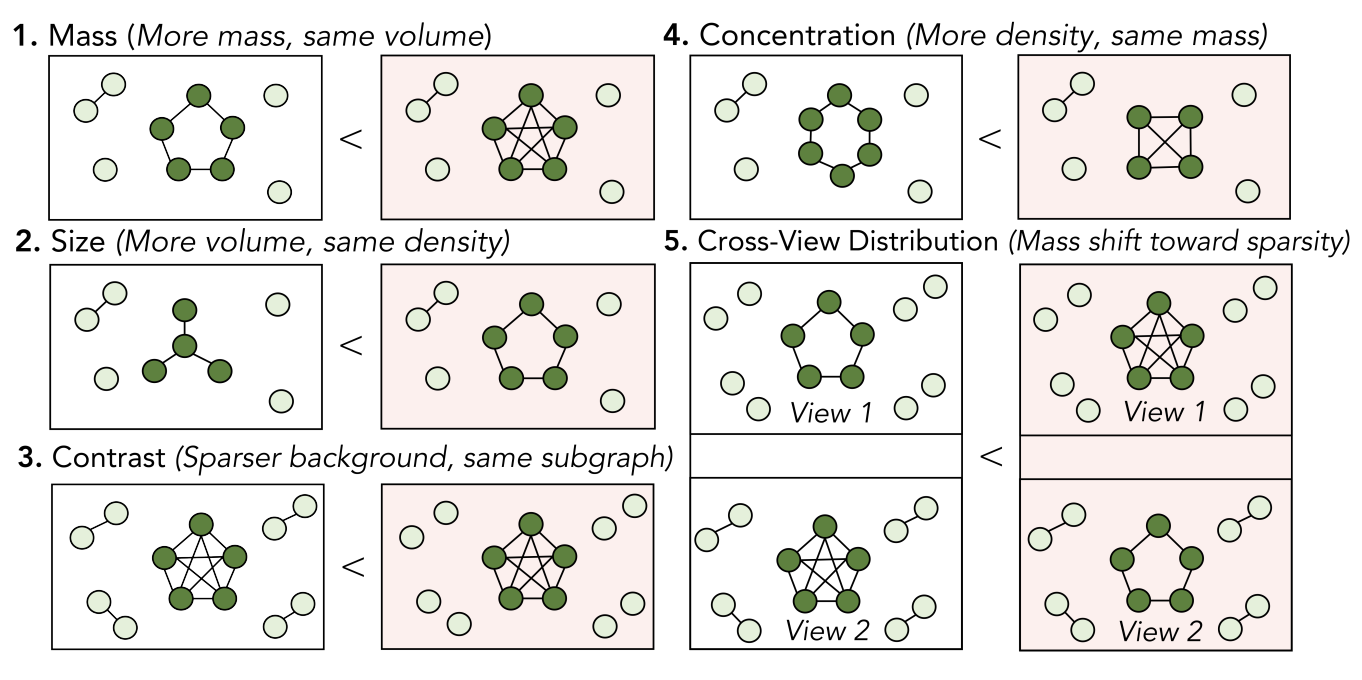 SliceNDice: Mining Suspicious Multi-attribute Entity Groups with Multi-view GraphsHamed Nilforoshan and Neil ShahIn IEEE International Conference on Data Science and Advanced Analytics, 2019
SliceNDice: Mining Suspicious Multi-attribute Entity Groups with Multi-view GraphsHamed Nilforoshan and Neil ShahIn IEEE International Conference on Data Science and Advanced Analytics, 2019Given the reach of web platforms, bad actors have considerable incentives to manipulate and defraud users at the expense of platform integrity. This has spurred research in numerous suspicious behavior detection tasks, including detection of sybil accounts, false information, and payment scams/fraud. In this paper, we draw the insight that many such initiatives can be tackled in a common framework by posing a detection task which seeks to find groups of entities which share too many properties with one another across multiple attributes (sybil accounts created at the same time and location, propaganda spreaders broadcasting articles with the same rhetoric and with similar reshares, etc.) Our work makes four core contributions: Firstly, we posit a novel formulation of this task as a multi-view graph mining problem, in which distinct views reflect distinct attribute similarities across entities, and contextual similarity and attribute importance are respected. Secondly, we propose a novel suspiciousness metric for scoring entity groups given the abnormality of their synchronicity across multiple views, which obeys intuitive desiderata that existing metrics do not. Finally, we propose the SliceNDice algorithm which enables efficient extraction of highly suspicious entity groups, and demonstrate its practicality in production, in terms of strong detection performance and discoveries on Snapchat’s large advertiser ecosystem (89% precision and numerous discoveries of real fraud rings), marked outperformance of baselines (over 97% precision/recall in simulated settings) and linear scalability.
- DSAA
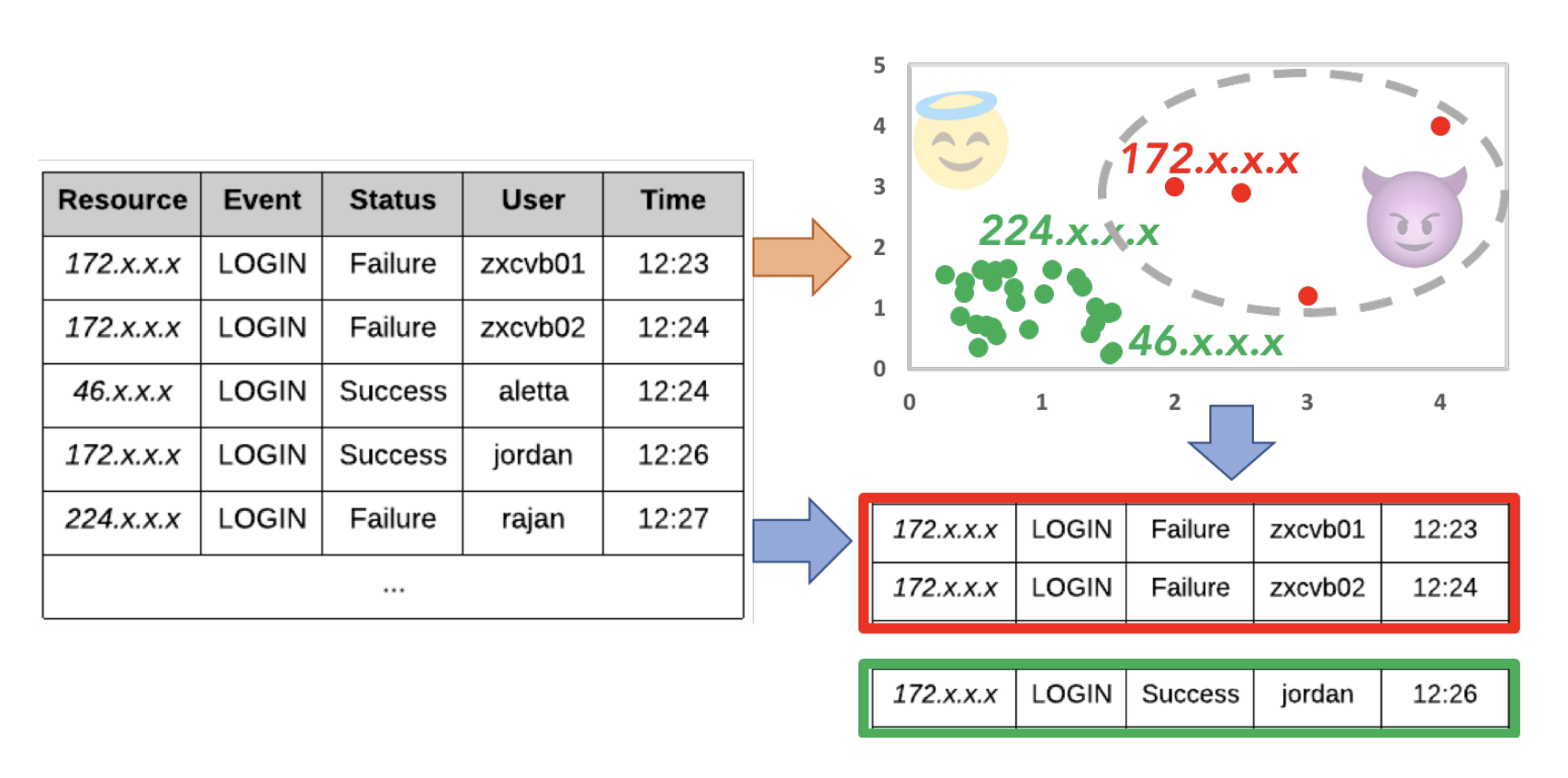 FARE: Schema-Agnostic Anomaly Detection in Social Event LogsNeil ShahIn IEEE International Conference on Data Science and Advanced Analytics, 2019
FARE: Schema-Agnostic Anomaly Detection in Social Event LogsNeil ShahIn IEEE International Conference on Data Science and Advanced Analytics, 2019Online social platforms are constantly under attack by bad actors. These bad actors often leverage resources (e.g. IPs, devices) under their control to attack the platform by targeting various, vulnerable endpoints (e.g. account authentication, sybil account creation, friending) which may process millions to billions of events every day. As the scale and multifacetedness of malicious behaviors grows, and new endpoints and corresponding events are utilized and processed every day, the development of fast, extensible and schema-agnostic anomaly detection approaches to enable standardized protocols for different classes of events is critical. This is a notable challenge given that practitioners often have neither time nor means to custom-build anomaly detection services for each new event class and type. Moreover, labeled data is rarely available in such diverse settings, making unsupervised methods appealing. In this work, we study unsupervised, schema-agnostic characterization and detection of resource usage anomalies in social event logs. We propose an efficient algorithmic approach to this end, and evaluate it with promising results on several log datasets of different event classes. Specifically, our contributions include a) formulation: a novel articulation of the schema-agnostic anomaly detection problem for event logs, b) approach: we propose FARE (Finding Anomalous Resources and Events), which integrates online resource anomaly detection and offline event culpability identification components, and c) efficacy: demonstrated accuracy (100% precision@250 on two industrial datasets from the Snapchat platform, with 50% anomalies previously uncaught by state-of-the-art production defenses), robustness (high precision/recall over suitable synthetic attacks and parameter choices) and scalability (near-linear in the number of events).
- KDD
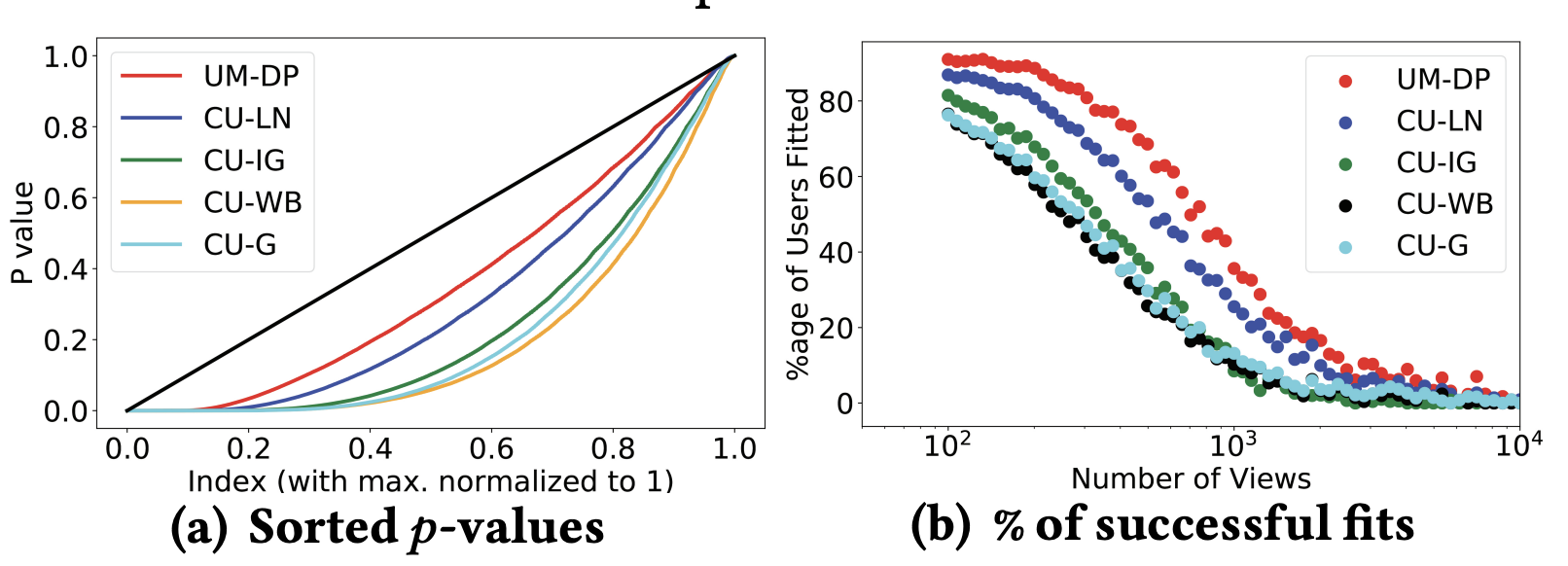 Modeling Dwell Time Engagement on Visual MultimediaHemank Lamba and Neil ShahIn ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2019
Modeling Dwell Time Engagement on Visual MultimediaHemank Lamba and Neil ShahIn ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2019Visual multimedia is one of the most prevalent sources of modern online content and engagement. However, despite its prevalence, little is known about user engagement with such content. For instance, how can we model engagement for a specific content or viewer sample, and across multiple samples? Can we model and discover patterns in these interactions, and detect outlying behaviors corresponding to abnormal engagement? In this paper, we study these questions in depth. Understanding these questions has implications in user modeling and understanding, ranking, trust and safety and more. For analysis, we consider content and viewer dwell time (engagement duration) behaviors with images and videos on Snapchat Stories, one of the largest multimedia-driven social sharing services. To our knowledge, we are the first to model and analyze dwell time behaviors on such media. Specifically, our contributions include (a) individual modeling: we propose and evaluate the ŁFmodel, ŁTmodel and \Vmodel parametric models to describe dwell times of unlooped/looped media and viewers which outperform alternatives, (b) aggregate modeling: we show how to flexibly summarize the respective joint distributions of multivariate parametrized fits across many samples using Vine Copulas in the analog ALFmodel, ALTmodel and AVmodel models, which enable inferences regarding aggregate behavioral patterns, and offer the ability to simulate real-looking engagement data (c) anomaly detection: we demonstrate our aggregate models can robustly detect anomalies present during training (0.9+ AUROC across most attack models), and also enable discovery of real dwell time anomalies.
- CHI
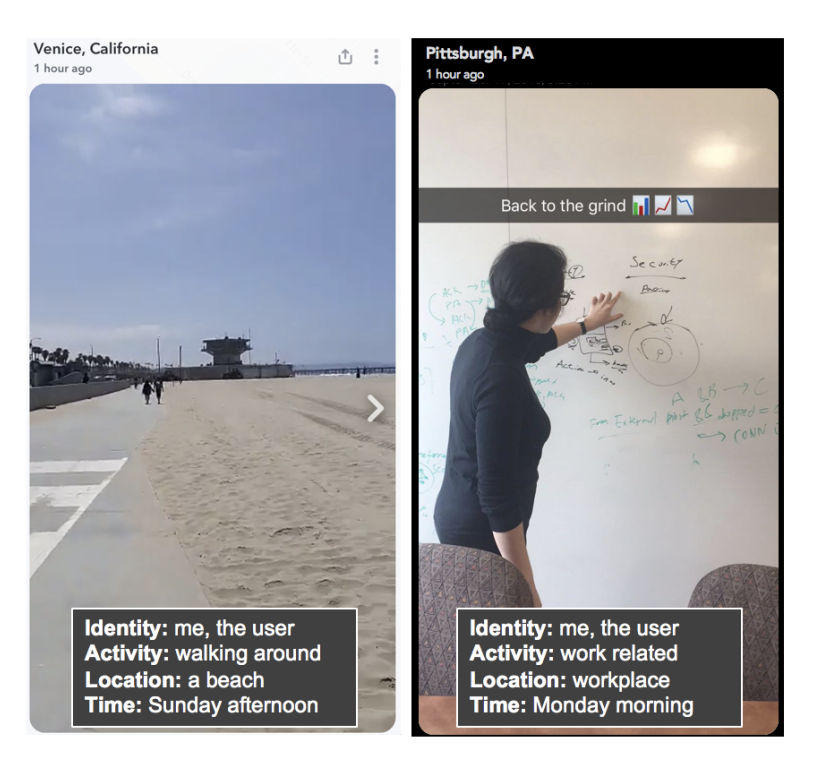 Impact of Contextual Factors on Public Snapchat SharingHana Habib, Neil Shah, and Rajan VaishIn ACM SIGCHI Conference on Human Factors in Computing Systems, 2019
Impact of Contextual Factors on Public Snapchat SharingHana Habib, Neil Shah, and Rajan VaishIn ACM SIGCHI Conference on Human Factors in Computing Systems, 2019Public sharing is integral to online platforms. This includes the popular multimedia messaging application Snapchat, on which public sharing is relatively new and unexplored in prior research. In mobile-first applications, sharing contexts are dynamic. However, it is unclear how context impacts users’ sharing decisions. As platforms increasingly rely on user-generated content, it is important to also broadly understand user motivations and considerations in public sharing. We explored these aspects of content sharing through a survey of 1,515 Snapchat users. Our results indicate that users primarily have intrinsic motivations for publicly sharing Snaps, such as to share an experience with the world, but also have considerations related to audience and sensitivity of content. Additionally, we found that Snaps shared publicly were contextually different from those privately shared. Our findings suggest that content sharing systems can be designed to support sharing motivations, yet also be sensitive to private contexts.
- ASONAM
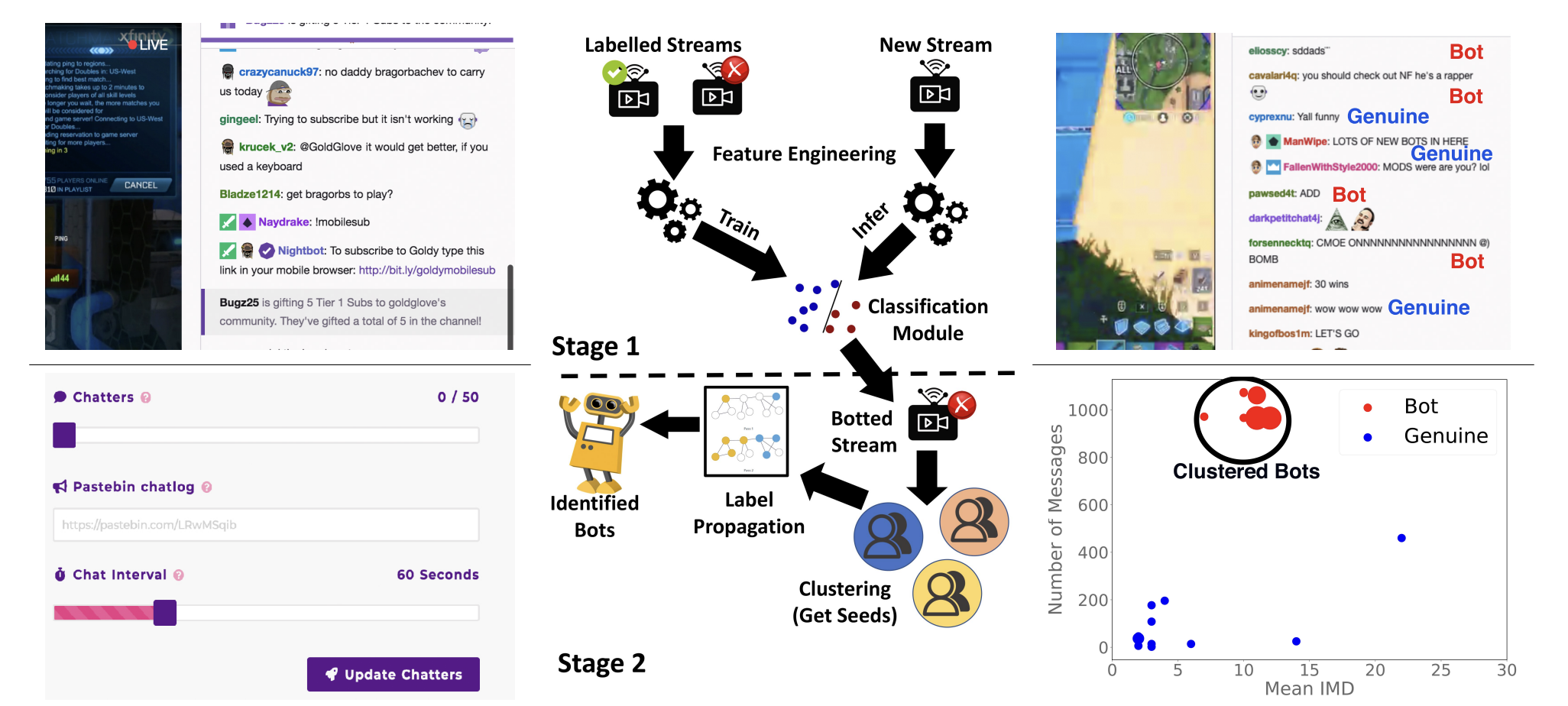 Characterizing and Detecting Livestreaming ChatbotsShreya Jain, Dipankar Niranjan, Hemank Lamba, Neil Shah, and Ponnurangam KumaraguruIn IEEE/ACM International Conference on Advances in Social Network Analysis and Mining, 2019
Characterizing and Detecting Livestreaming ChatbotsShreya Jain, Dipankar Niranjan, Hemank Lamba, Neil Shah, and Ponnurangam KumaraguruIn IEEE/ACM International Conference on Advances in Social Network Analysis and Mining, 2019Livestreaming platforms enable content producers, or streamers, to broadcast creative content to a potentially large viewer base. Chatrooms form an integral part of such platforms, enabling viewers to interact both with the streamer, and amongst themselves. Streams with high engagement (many viewers and active chatters) are typically considered engaging, and often promoted to end users by means of recommendation algorithms, and exposed to better monetization opportunities via revenue share from platform advertising, viewer donations, and thirdparty sponsorships. Given such incentives, some streamers make use of fraudulent means to increase perceived engagement by simulating chatter via fake “chatbots” which can be purchased from shady online marketplaces. This inauthentic engagement can negatively influence recommendation, hurt streamer and viewer trust in the platform, and harm monetization for honest streamers. In this paper, we tackle the novel problem of automating detection of chatbots on livestreaming platforms. To this end, we first formalize the livestreaming chatbot detection problem and characterize differences between botted and genuine chatter behavior observed from a real-world livestreaming chatter dataset collected from Twitch.tv. We then propose SHERLOCK, which posits a two-stage approach of detecting chatbotted streams, and subsequently detecting the constituent chatbots. Finally, we demonstrate effectiveness on both real and synthetic data: to this end, we propose a novel strategy for collecting labeled, synthetic chatter dataset (typically unavailable) from such platforms, enabling evaluation of proposed detection approaches against chatbot behaviors with varying signatures. Our approach achieves .97 precision/recall on the real-world dataset, and .80+ F1 scores across most simulated attack settings.
2018
-
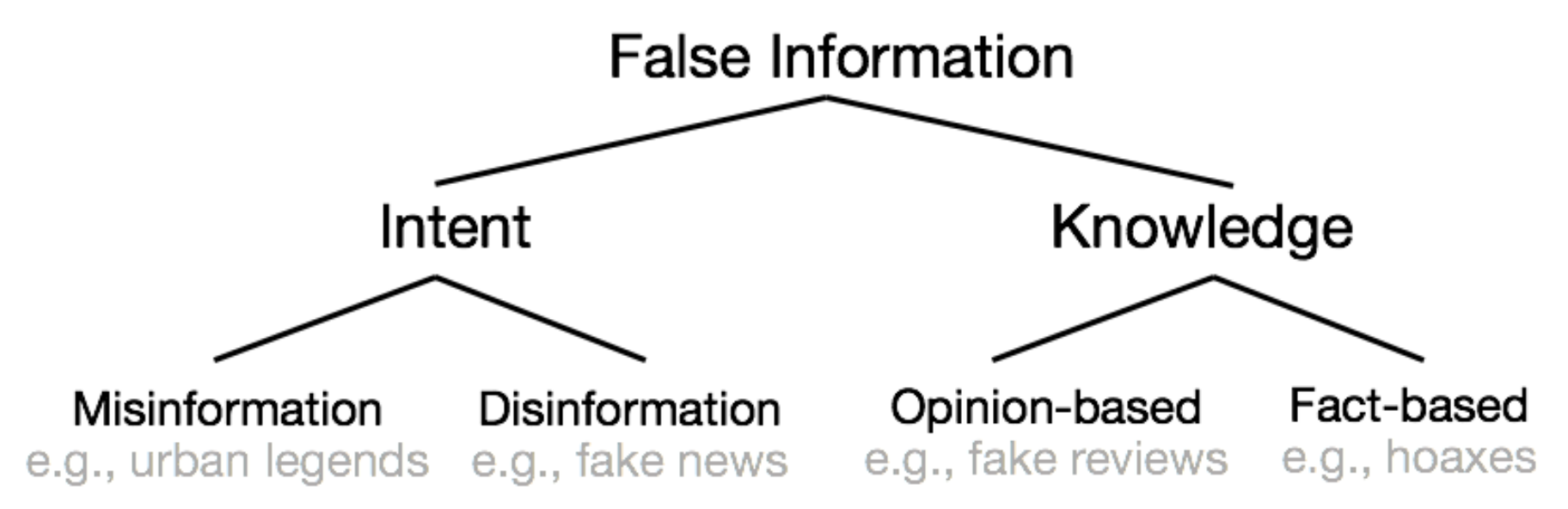 False Information on Web and Social Media: A SurveySrijan Kumar and Neil ShahIn Social Media Analytics: Advances and Applications, CRC Press 2018, 2018
False Information on Web and Social Media: A SurveySrijan Kumar and Neil ShahIn Social Media Analytics: Advances and Applications, CRC Press 2018, 2018False information can be created and spread easily through the web and social media platforms, resulting in widespread real-world impact. Characterizing how false information proliferates on social platforms and why it succeeds in deceiving readers are critical to develop efficient detection algorithms and tools for early detection. A recent surge of research in this area has aimed to address the key issues using methods based on feature engineering, graph mining, and information modeling. Majority of the research has primarily focused on two broad categories of false information: opinion-based (e.g., fake reviews), and fact-based (e.g., false news and hoaxes). Therefore, in this work, we present a comprehensive survey spanning diverse aspects of false information, namely (i) the actors involved in spreading false information, (ii) rationale behind successfully deceiving readers, (iii) quantifying the impact of false information, (iv) measuring its characteristics across different dimensions, and finally, (iv) algorithms developed to detect false information. In doing so, we create a unified framework to describe these recent methods and highlight a number of important directions for future research.
- ASONAM
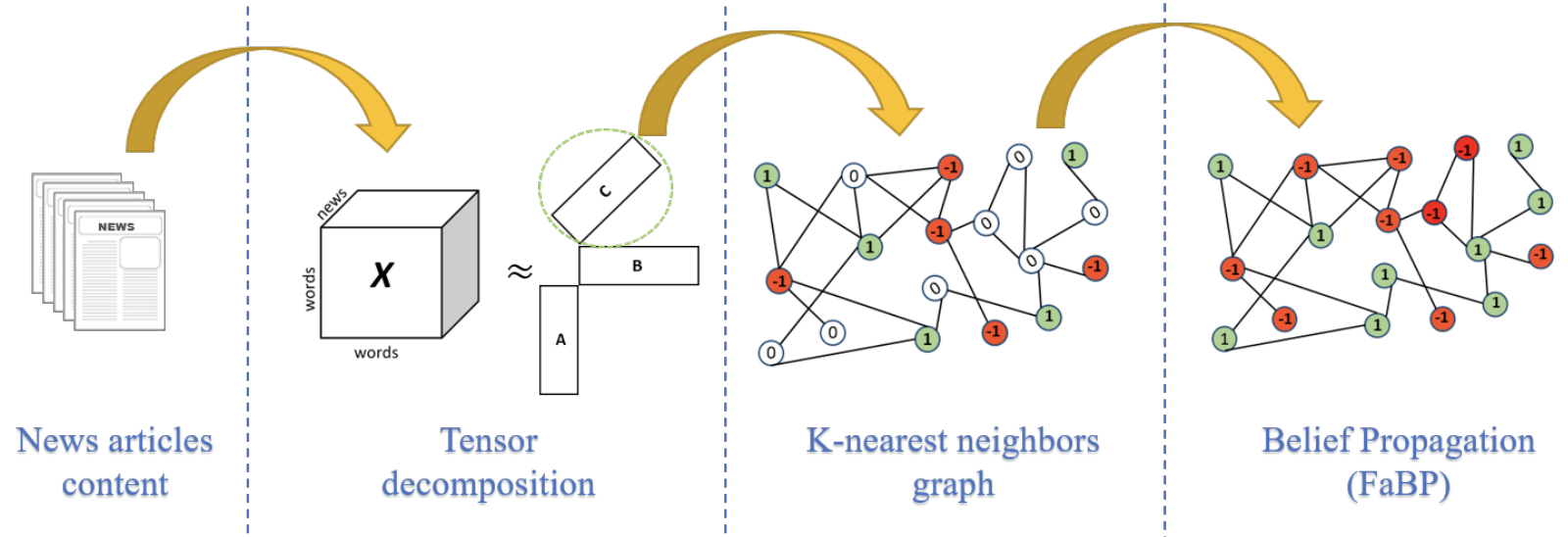 Semi-supervised Content-based Detection of Misinformation via Tensor EmbeddingsGisel Bastidas Guacho, Sara Abdali, Neil Shah, and Evangelos E. PapalexakisIn IEEE/ACM International Conference on Advances in Social Network Analysis and Mining, 2018
Semi-supervised Content-based Detection of Misinformation via Tensor EmbeddingsGisel Bastidas Guacho, Sara Abdali, Neil Shah, and Evangelos E. PapalexakisIn IEEE/ACM International Conference on Advances in Social Network Analysis and Mining, 2018Fake news may be intentionally created to promote economic, political and social interests, and can lead to negative impacts on humans beliefs and decisions. Hence, detection of fake news is an emerging problem that has become extremely prevalent during the last few years. Most existing works on this topic focus on manual feature extraction and supervised classification models leveraging a large number of labeled (fake or real) articles. In contrast, we focus on content-based detection of fake news articles, while assuming that we have a small amount of labels, made available by manual fact-checkers or automated sources. We argue this is a more realistic setting in the presence of massive amounts of content, most of which cannot be easily factchecked. To that end, we represent collections of news articles as multi-dimensional tensors, leverage tensor decomposition to derive concise article embeddings that capture spatial/contextual information about each news article, and use those embeddings to create an article-by-article graph on which we propagate limited labels. Results on three real-world datasets show that our method performs on par or better than existing models that are fully supervised, in that we achieve better detection accuracy using fewer labels. In particular, our proposed method achieves 75.43% of accuracy using only 30% of labels of a public dataset while an SVM-based classifier achieved 67.43%. Furthermore, our method achieves 70.92% of accuracy in a large dataset using only 2% of labels.
- ECML-PKDD
 Beyond Outlier Detection: LookOut for Pictorial ExplanationNikhil Gupta, Dhivya Eswaran, Neil Shah, Leman Akoglu, and Christos FaloutsosIn European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases, 2018
Beyond Outlier Detection: LookOut for Pictorial ExplanationNikhil Gupta, Dhivya Eswaran, Neil Shah, Leman Akoglu, and Christos FaloutsosIn European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases, 2018Why is a given point in a dataset marked as an outlier by an off-the-shelf detection algorithm? Which feature(s) explain it the best? What is the best way to convince a human analyst that the point is indeed an outlier? We provide succinct, interpretable, and simple pictorial explanations of outlying behavior in multi-dimensional real-valued datasets while respecting the limited attention of human analysts. Specifically, we propose to output a few focus-plots, i.e., pairwise feature plots, from a few, carefully chosen feature sub-spaces. The proposed LookOut makes four contributions: (a) problem formulation: we introduce an “analyst-centered” problem formulation for explaining outliers via focus-plots, (b) explanation algorithm: we propose a plot-selection objective and the LookOut algorithm to approximate it with optimality guarantees, (c) generality: our explanation algorithm is both domain- and detector-agnostic, and (d) scalability: LookOut scales linearly with the size of input outliers to explain and the explanation budget. Our experiments show that LookOut performs near-ideally in terms of maximizing explanation objective on several real datasets, while producing visually interpretable and intuitive results in explaining groundtruth outliers. Code related to this paper is available at: https://github.com/NikhilGupta1997/Lookout.
- SIGIR
 Did We Get It Right? Predicting Query Performance in E-commerce SearchRohan Kumar, Mohit Kumar, Neil Shah, and Christos FaloutsosIn ACM Special Interest Group on Information Retrieval, 2018
Did We Get It Right? Predicting Query Performance in E-commerce SearchRohan Kumar, Mohit Kumar, Neil Shah, and Christos FaloutsosIn ACM Special Interest Group on Information Retrieval, 2018In this paper, we address the problem of evaluating whether results served by an e-commerce search engine for a query are good or not. This is a critical question in evaluating any e-commerce search engine. While this question is traditionally answered using simple metrics like query click-through rate (CTR), we observe that in e-commerce search, such metrics can be misleading. Upon inspection, we find cases where CTR is high but the results are poor and vice versa. Similar cases exist for other metrics like time to click which are often also used for evaluating search engines. We aim to learn the quality of the results served by the search engine based on users’ interactions with the results. Although this problem has been studied in the web search context, this is the first study for e-commerce search, to the best of our knowledge. Despite certain commonalities with evaluating web search engines, there are several major differences such as underlying reasons for search failure, and availability of rich user interaction data with products (e.g. adding a product to the cart). We study large-scale user interaction logs from Flipkart’s search engine, analyze behavioral patterns and build models to classify queries based on user behavior signals. We demonstrate the feasibility and efficacy of such models in accurately predicting query performance. Our classifier is able to achieve an average AUC of 0.75 on a held-out test set.
- SNAM
 Reducing Large Graphs to Small Supergraphs: A Unified ApproachYike Liu, Tara Safavi, Neil Shah, and Danai KoutraIn Springer Social Network Analysis and Mining, 2018
Reducing Large Graphs to Small Supergraphs: A Unified ApproachYike Liu, Tara Safavi, Neil Shah, and Danai KoutraIn Springer Social Network Analysis and Mining, 2018Summarizing a large graph with a much smaller graph is critical for applications like speeding up intensive graph algorithms and interactive visualization. In this paper, we propose CONditional Diversified Network Summarization (CondeNSe), a Minimum Description Length-based method that summarizes a given graph with approximate “supergraphs” conditioned on a set of diverse, predefined structural patterns. CondeNSe features a unified pattern discovery module and a set of effective summary assembly methods, including a powerful parallel approach, k-Step, that creates high-quality summaries not biased toward specific graph structures. By leveraging CondeNSe ’s ability to efficiently handle overlapping structures, we contribute a novel evaluation of seven existing clustering techniques by going beyond classic cluster quality measures. Extensive empirical evaluation on real networks in terms of compression, runtime, and summary quality shows that CondeNSe finds 30–50% more compact summaries than baselines, with up to 75–90% fewer structures and equally good node coverage.
2017
- TKDD
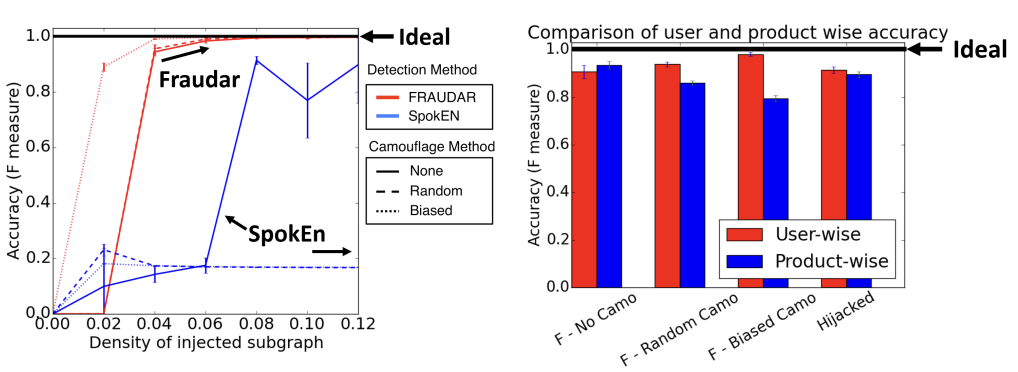 Graph-based Fraud Detection in the Face of CamouflageBryan Hooi, Kijung Shin, Hyun Ah Song, Alex Beutel, Neil Shah, and Christos FaloutsosIn ACM Transactions on Knowledge Discovery from Data, 2017
Graph-based Fraud Detection in the Face of CamouflageBryan Hooi, Kijung Shin, Hyun Ah Song, Alex Beutel, Neil Shah, and Christos FaloutsosIn ACM Transactions on Knowledge Discovery from Data, 2017Given a bipartite graph of users and the products that they review, or followers and followees, how can we detect fake reviews or follows? Existing fraud detection methods (spectral, etc.) try to identify dense subgraphs of nodes that are sparsely connected to the remaining graph. Fraudsters can evade these methods using camouflage, by adding reviews or follows with honest targets so that they look "normal." Even worse, some fraudsters use hijacked accounts from honest users, and then the camouflage is indeed organic. Our focus is to spot fraudsters in the presence of camouflage or hijacked accounts. We propose FRAUDAR, an algorithm that (a) is camouflage resistant, (b) provides upper bounds on the effectiveness of fraudsters, and (c) is effective in real-world data. Experimental results under various attacks show that FRAUDAR outperforms the top competitor in accuracy of detecting both camouflaged and non-camouflaged fraud. Additionally, in real-world experiments with a Twitter follower–followee graph of 1.47 billion edges, FRAUDAR successfully detected a subgraph of more than 4,000 detected accounts, of which a majority had tweets showing that they used follower-buying services.
-
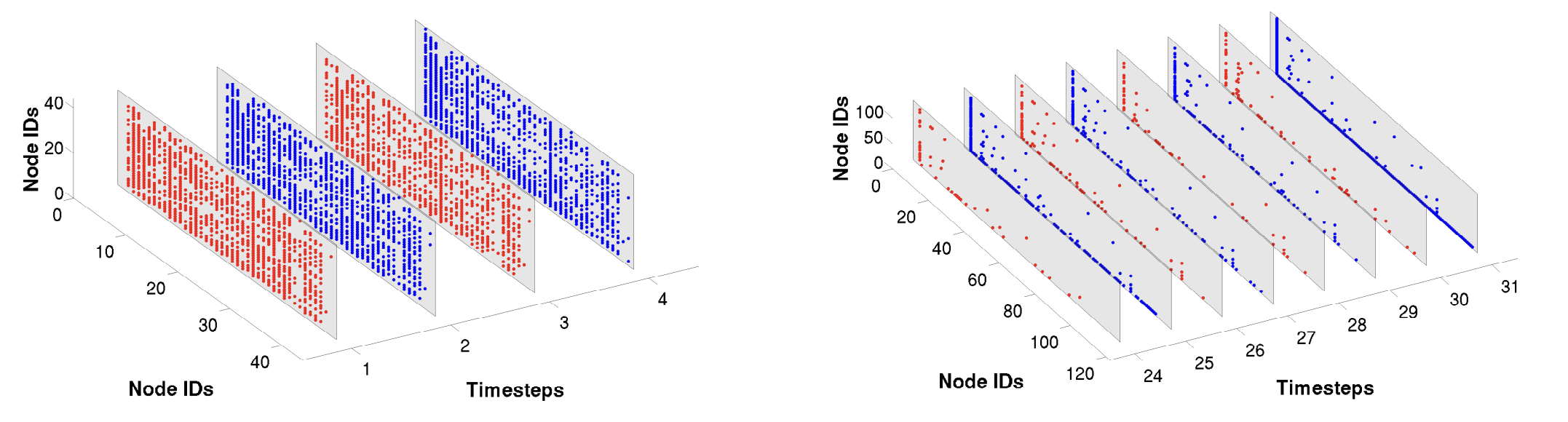 On Summarizing Large Scale Dynamic GraphsNeil Shah, Danai Koutra, Lisa Jin, Tianmin Zou, Brian Gallagher, and Christos FaloutsosIn IEEE Data Engineering Bulletin 2017, 2017
On Summarizing Large Scale Dynamic GraphsNeil Shah, Danai Koutra, Lisa Jin, Tianmin Zou, Brian Gallagher, and Christos FaloutsosIn IEEE Data Engineering Bulletin 2017, 2017How can we describe a large, dynamic graph over time? Is it random? If not, what are the most apparent deviations from randomness – a dense block of actors that persists over time, or perhaps a star with many satellite nodes that appears with some fixed periodicity? In practice, these deviations indicate patterns – for example, research collaborations forming and fading away over the years. Which patterns exist in real-world dynamic graphs, and how can we find and rank their importance? These are exactly the problems we focus on. Our main contributions are (a) formulation: we show how to formalize this problem as minimizing an information theoretic encoding cost, (b) algorithm: we propose TIMECRUNCH, an effective and scalable method for finding coherent, temporal patterns in dynamic graphs and (c) practicality: we apply our method to several large, diverse real-world datasets with up to 36 million edges and introduce our auxiliary ECOVIZ framework for visualizing and interacting with dynamic graphs which have been summarized by TIMECRUNCH. We show that TIMECRUNCH is able to compress these graphs by summarizing important temporal structures and finds patterns that agree with intuition.
- WWW
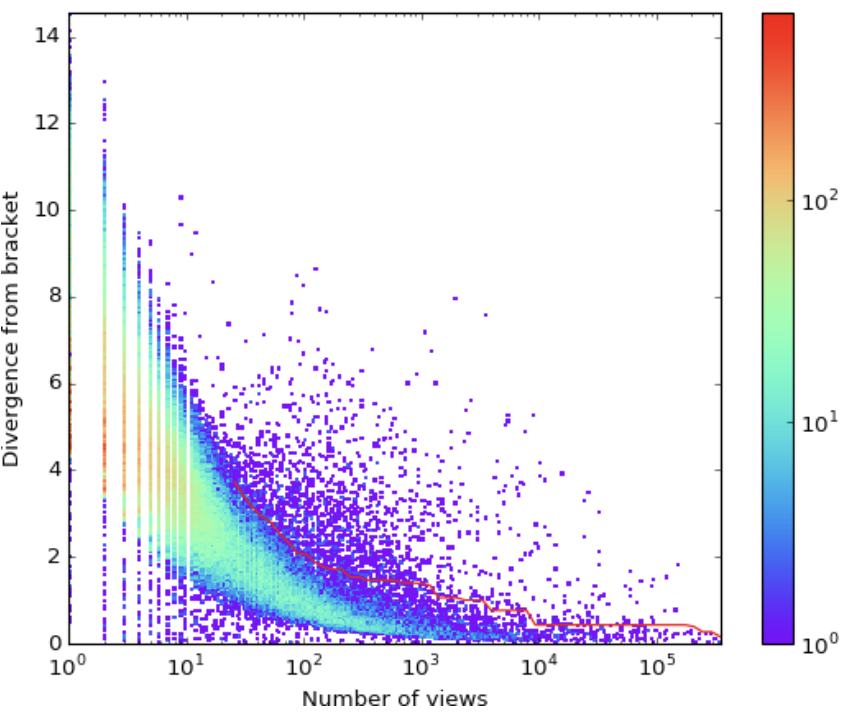 FLOCK: Combating Astroturfing on Livestreaming PlatformsNeil ShahIn ACM World Wide Web Conference, 2017
FLOCK: Combating Astroturfing on Livestreaming PlatformsNeil ShahIn ACM World Wide Web Conference, 2017Livestreaming platforms have become increasingly popular in recent years as a means of sharing and advertising creative content. Popular content streamers who attract large viewership to their live broadcasts can earn a living by means of ad revenue, donations and channel subscriptions. Unfortunately, this incentivized popularity has simultaneously resulted in incentive for fraudsters to provide services to astroturf, or artificially inflate viewership metrics by providing fake "live" views to customers. Our work provides a number of major contributions: (a) formulation: we are the first to introduce and characterize the viewbot fraud problem in livestreaming platforms, (b) methodology: we propose FLOCK, a principled and unsupervised method which efficiently and effectively identifies botted broadcasts and their constituent botted views, and (c) practicality: our approach achieves over 98% precision in identifying botted broadcasts and over 90% precision/recall against sizable synthetically generated viewbot attacks on a real-world livestreaming workload of over 16 million views and 92 thousand broadcasts. FLOCK successfully operates on larger datasets in practice and is regularly used at a large, undisclosed livestreaming corporation.
- ICDM
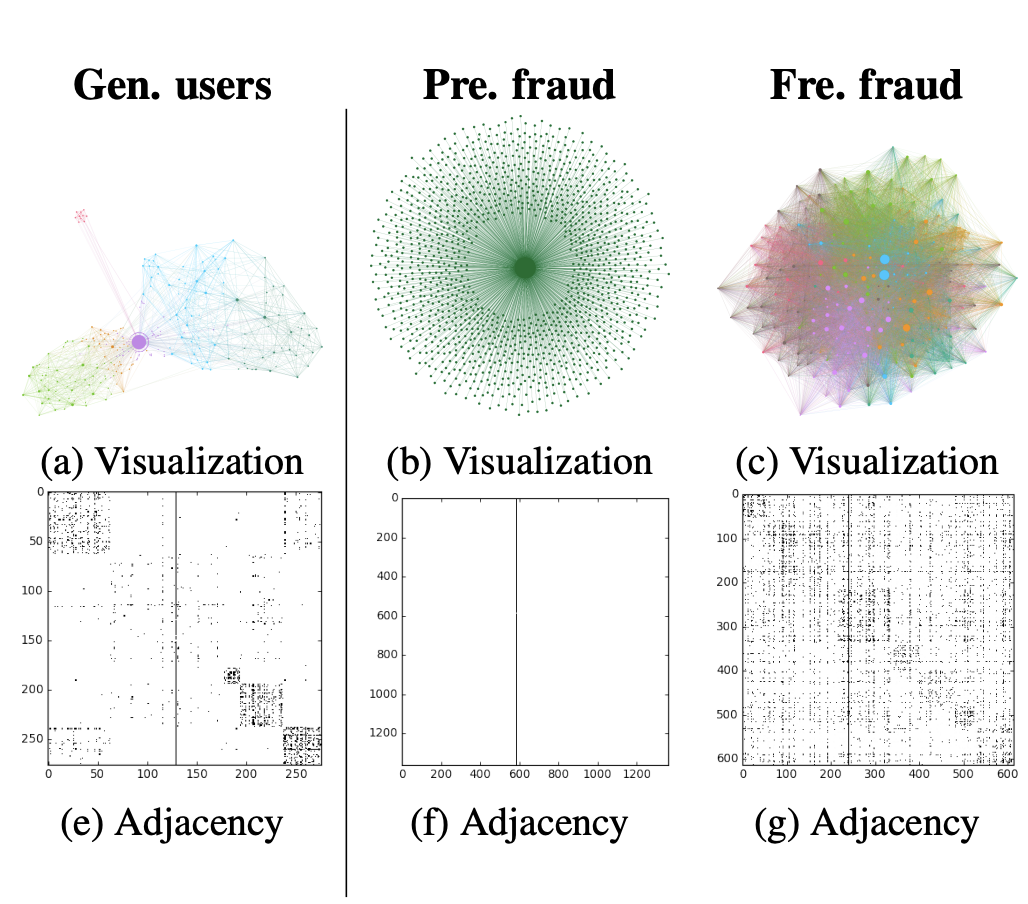 The Many Faces of Link FraudNeil Shah, Hemank Lamba, Alex Beutel, and Christos FaloutsosIn IEEE International Conference on Data Mining, 2017
The Many Faces of Link FraudNeil Shah, Hemank Lamba, Alex Beutel, and Christos FaloutsosIn IEEE International Conference on Data Mining, 2017Most past work on social network link fraud detection tries to separate genuine users from fraudsters, implicitly assuming that there is only one type of fraudulent behavior. But is this assumption true? And, in either case, what are the characteristics of such fraudulent behaviors? In this work, we set up honeypots ("dummy" social network accounts), and buy fake followers (after careful IRB approval). We report the signs of such behaviors including oddities in local network connectivity, account attributes, and similarities and differences across fraud providers. Most valuably, we discover and characterize several types of fraud behaviors. We discuss how to leverage our insights in practice by engineering strongly performing entropy-based features and demonstrating high classification accuracy. Our contributions are (a) instrumentation: we detail our experimental setup and carefully engineered data collection process to scrape Twitter data while respecting API rate-limits, (b) observations on fraud multimodality: we analyze our honeypot fraudster ecosystem and give surprising insights into the multifaceted behaviors of these fraudster types, and (c) features: we propose novel features that give strong (>0.95 precision/recall) discriminative power on ground-truth Twitter data.
- DSAA
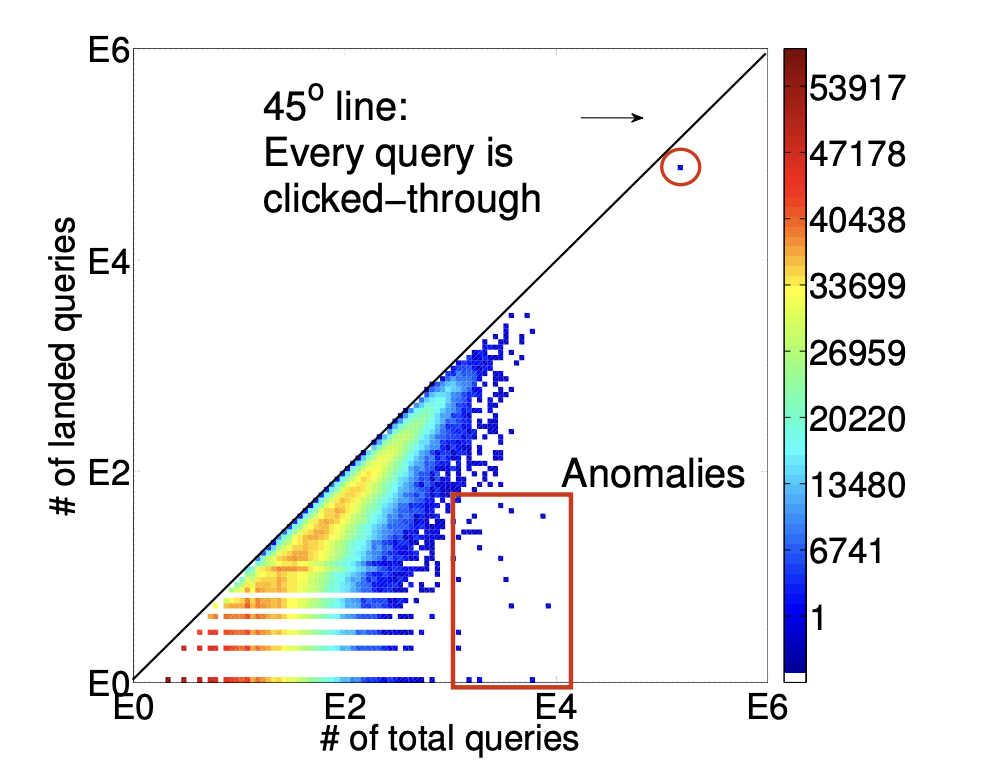 M3A: Model, MetaModel, and Anomaly Detection in Web SearchesDa-Cheng Juan, Neil Shah, Mingyu Tang, Zhiliang Qian, Diana Marculescu, and Christos FaloutsosIn IEEE International Conference on Data Science and Advanced Analytics, 2017
M3A: Model, MetaModel, and Anomaly Detection in Web SearchesDa-Cheng Juan, Neil Shah, Mingyu Tang, Zhiliang Qian, Diana Marculescu, and Christos FaloutsosIn IEEE International Conference on Data Science and Advanced Analytics, 2017’Alice’ is submitting one web search per five minutes, for three hours in a row - is it normal? How to detect abnormal search behaviors, among Alice and other users? Is there any distinct pattern in Alice’s (or other users’) search behavior? We studied what is probably the largest, publicly available, query log that contains more than 30 million queries from 0.6 million users. In this paper, we present a novel, user-and group-level framework, M3A: Model, MetaModel and Anomaly detection. For each user, we discover and explain a surprising, bi-modal pattern of the inter-arrival time (IAT) of landed queries (queries with user click-through). Specifically, the model Camel-Log is proposed to describe such an IAT distribution; we then notice the correlations among its parameters at the group level. Thus, we further propose the metamodel Meta-Click, to capture and explain the two-dimensional, heavy-tail distribution of the parameters. Combining Camel-Log and Meta-Click, the proposed M3A has the following strong points: (1) the accurate modeling of marginal IAT distribution, (2) quantitative interpretations, and (3) anomaly detection.
2016
- KDD
 Reducing Million-Node Graphs to a Few Structural Patterns: A Unified ApproachYike Liu, Tara Safavi, Neil Shah, and Danai KoutraIn ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2016
Reducing Million-Node Graphs to a Few Structural Patterns: A Unified ApproachYike Liu, Tara Safavi, Neil Shah, and Danai KoutraIn ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2016How do graph clustering techniques compare in terms of summarization power? How well can they summarize a million-node graph with a few representative structures? In this paper, we compare and contrast different techniques: METIS, LOUVAIN, SPECTRAL CLUSTERING, SLASHBURN, BIGCLAM, HYCOMFIT, and KCBC, our proposed k-core-based clustering method. Unlike prior work that focuses on various measures of cluster quality, we use vocabulary structures that often appear in real graphs and the Minimum Description Length (MDL) principle to obtain a graph summary per clustering method. Our main contributions are: (i) Formulation: we propose a summarization-based evaluation of clustering methods. Our method, VOG-OVERLAP, concisely summarizes graphs in terms of their important structures with small edge overlap and large node/edge coverage; (ii) Algorithm: we introduce KCBC, a graph decomposition technique based on the k-core algorithm. We also introduce STEP, a summary assembly heuristic that produces compact summaries, as well as two parallel approximations thereof; (iii) Evaluation: we compare the summarization power of seven clustering techniques on large real graphs and analyze their compression rates, summary statistics, and runtimes.
- KDD
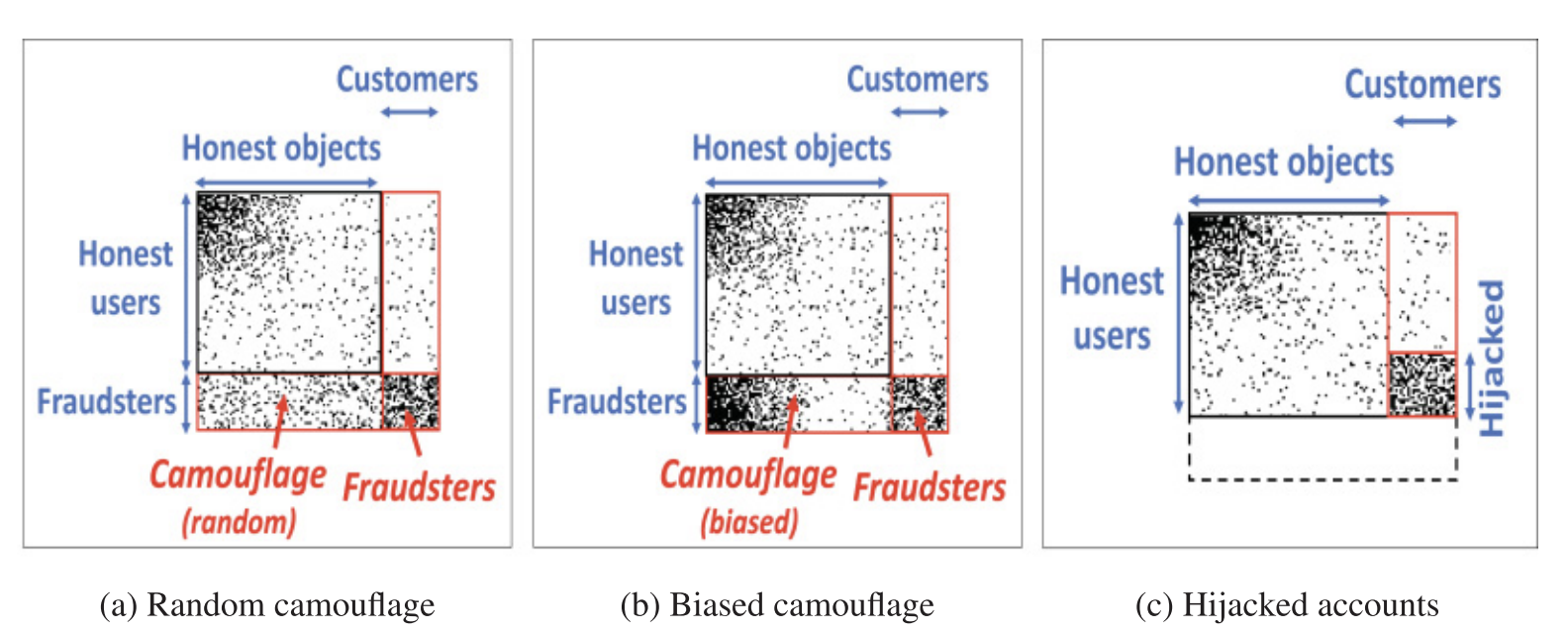 FRAUDAR: Bounding Graph Fraud in the Face of CamouflageBryan Hooi, Hyun Ah Song, Alex Beutel, Neil Shah, Kijung Shin, and Christos FaloutsosIn ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2016
FRAUDAR: Bounding Graph Fraud in the Face of CamouflageBryan Hooi, Hyun Ah Song, Alex Beutel, Neil Shah, Kijung Shin, and Christos FaloutsosIn ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2016Given a bipartite graph of users and the products that they review, or followers and followees, how can we detect fake reviews or follows? Existing fraud detection methods (spectral, etc.) try to identify dense subgraphs of nodes that are sparsely connected to the remaining graph. Fraudsters can evade these methods using camouflage, by adding reviews or follows with honest targets so that they look "normal". Even worse, some fraudsters use hijacked accounts from honest users, and then the camouflage is indeed organic. Our focus is to spot fraudsters in the presence of camouflage or hijacked accounts. We propose FRAUDAR, an algorithm that (a) is camouflage-resistant, (b) provides upper bounds on the effectiveness of fraudsters, and (c) is effective in real-world data. Experimental results under various attacks show that FRAUDAR outperforms the top competitor in accuracy of detecting both camouflaged and non-camouflaged fraud. Additionally, in real-world experiments with a Twitter follower-followee graph of 1.47 billion edges, FRAUDAR successfully detected a subgraph of more than 4000 detected accounts, of which a majority had tweets showing that they used follower-buying services.
- ICDM
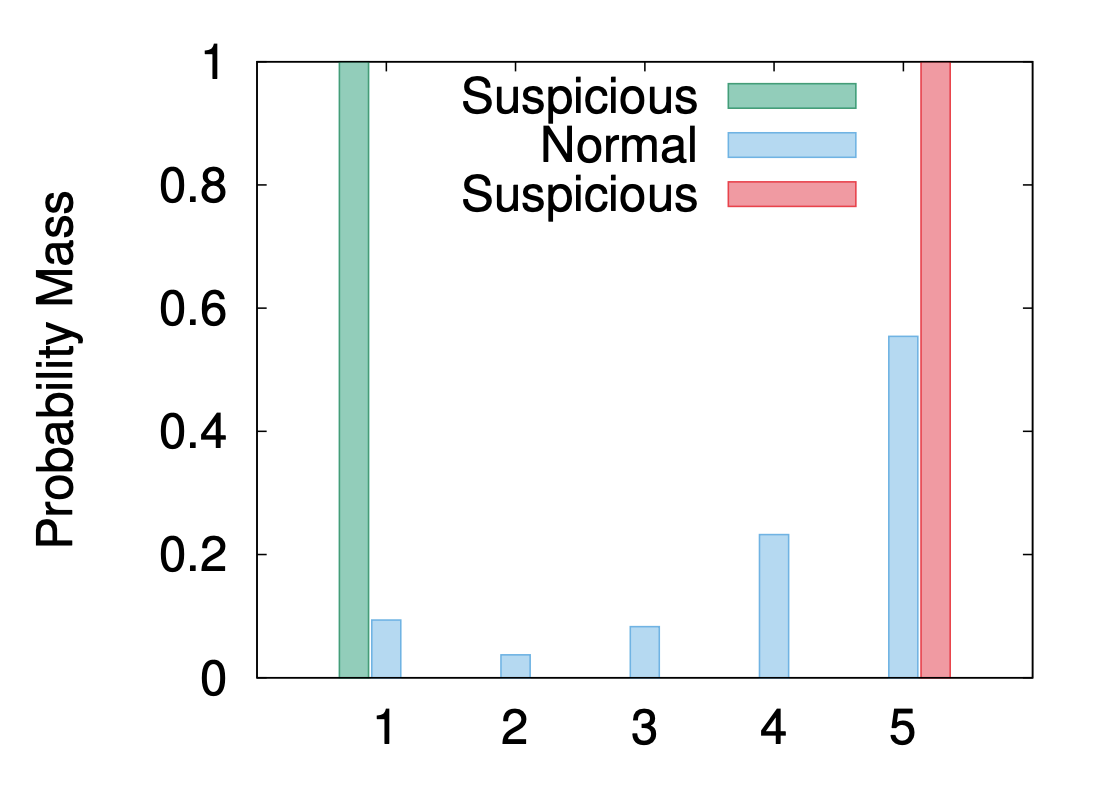 EdgeCentric: Anomaly Detection in Edge-Attributed NetworksNeil Shah, Alex Beutel, Bryan Hooi, Leman Akoglu, Stephan Gunnemann, Disha Makhija, Mohit Kumar, and Christos FaloutsosIn IEEE International Conference on Data Mining, 2016
EdgeCentric: Anomaly Detection in Edge-Attributed NetworksNeil Shah, Alex Beutel, Bryan Hooi, Leman Akoglu, Stephan Gunnemann, Disha Makhija, Mohit Kumar, and Christos FaloutsosIn IEEE International Conference on Data Mining, 2016Given a network with attributed edges, how can we identify anomalous behavior? Networks with edge attributes are commonplace in the real world. For example, edges in e-commerce networks often indicate how users rated products and services in terms of number of stars, and edges in online social and phonecall networks contain temporal information about when friendships were formed and when users communicated with each other – in such cases, edge attributes capture information about how the adjacent nodes interact with other entities in the network. In this paper, we aim to utilize exactly this information to discern suspicious from typical node behavior. Our work has a number of notable contributions, including (a) formulation: while most other graph-based anomaly detection works use structural graph connectivity or node information, we focus on the new problem of leveraging edge information, (b) methodology: we introduce EdgeCentric, an intuitive and scalable compression-based approach for detecting edge-attributed graph anomalies, and (c) practicality: we show that EdgeCentric successfully spots numerous such anomalies in several large, edge-attributed real-world graphs, including the Flipkart e-commerce graph with over 3 million product reviews between 1.1 million users and 545 thousand products, where it achieved 0.87 precision over the top 100 results.
- SDM
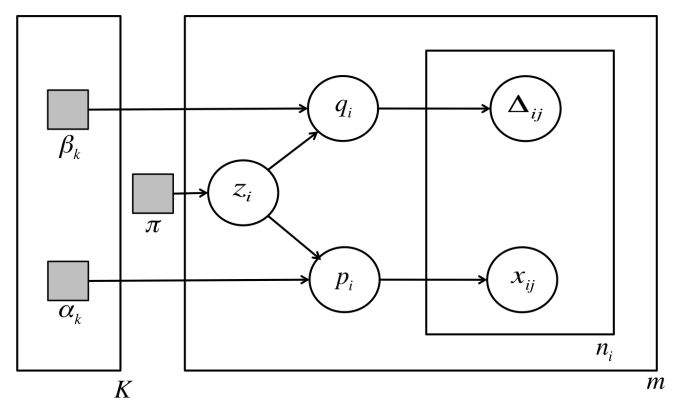 BIRDNEST: Bayesian Inference for Ratings-Fraud DetectionBryan Hooi, Neil Shah, Alex Beutel, Stephan Gunnemann, Leman Akoglu, Mohit Kumar, Disha Makhija, and Christos FaloutsosIn SIAM International Conference on Data Mining, 2016
BIRDNEST: Bayesian Inference for Ratings-Fraud DetectionBryan Hooi, Neil Shah, Alex Beutel, Stephan Gunnemann, Leman Akoglu, Mohit Kumar, Disha Makhija, and Christos FaloutsosIn SIAM International Conference on Data Mining, 2016Review fraud is a pervasive problem in online commerce, in which fraudulent sellers write or purchase fake reviews to manipulate perception of their products and services. Fake reviews are often detected based on several signs, including 1) they occur in short bursts of time; 2) fraudulent user accounts have skewed rating distributions. However, these may both be true in any given dataset. Hence, in this paper, we propose an approach for detecting fraudulent reviews which combines these 2 approaches in a principled manner, allowing successful detection even when one of these signs is not present. To combine these 2 approaches, we formulate our Bayesian Inference for Rating Data (BIRD) model, a flexible Bayesian model of user rating behavior. Based on our model we formulate a likelihood-based suspiciousness metric, Normalized Expected Surprise Total (NEST). We propose a linear-time algorithm for performing Bayesian inference using our model and computing the metric. Experiments on real data show that BIRDNEST successfully spots review fraud in large, real-world graphs: the 50 most suspicious users of the Flipkart platform flagged by our algorithm were investigated and all identified as fraudulent by domain experts at Flipkart.
2015
- NIPS
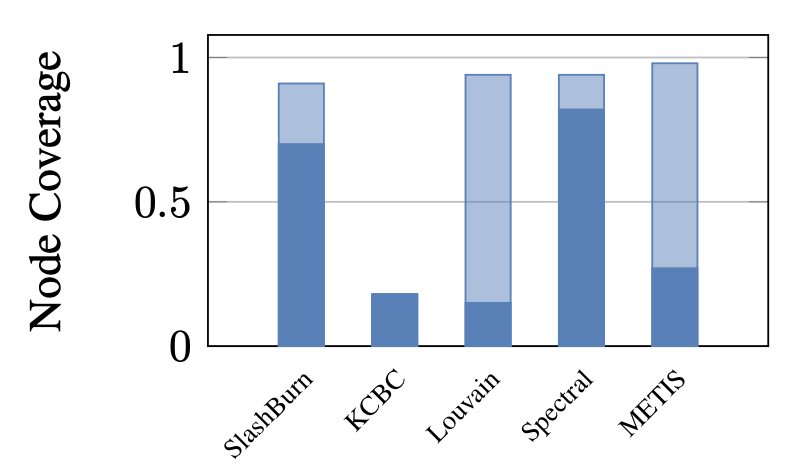 An Empirical Comparison of the Summarization Power of Graph Clustering MethodsYike Liu, Neil Shah, and Danai KoutraIn Neural Information Processing Systems, 2015
An Empirical Comparison of the Summarization Power of Graph Clustering MethodsYike Liu, Neil Shah, and Danai KoutraIn Neural Information Processing Systems, 2015How do graph clustering techniques compare with respect to their summarization power? How well can they summarize a million-node graph with a few representative structures? Graph clustering or community detection algorithms can summarize a graph in terms of coherent and tightly connected clusters. In this paper, we compare and contrast different techniques: METIS, Louvain, spectral clustering, SlashBurn and KCBC, our proposed k-core-based clustering method. Unlike prior work that focuses on various measures of cluster quality, we use vocabulary structures that often appear in real graphs and the Minimum Description Length (MDL) principle to obtain a graph summary per clustering method. Our main contributions are: (i) Formulation: We propose a summarization-based evaluation of clustering methods. Our method, VOG-OVERLAP, concisely summarizes graphs in terms of their important structures which lead to small edge overlap, and large node/edge coverage; (ii) Algorithm: we introduce KCBC, a graph decomposition technique, in the heart of which lies the k-core algorithm (iii) Evaluation: We compare the summarization power of five clustering techniques on large real graphs, and analyze their compression performance, summary statistics and runtimes.
- KDD
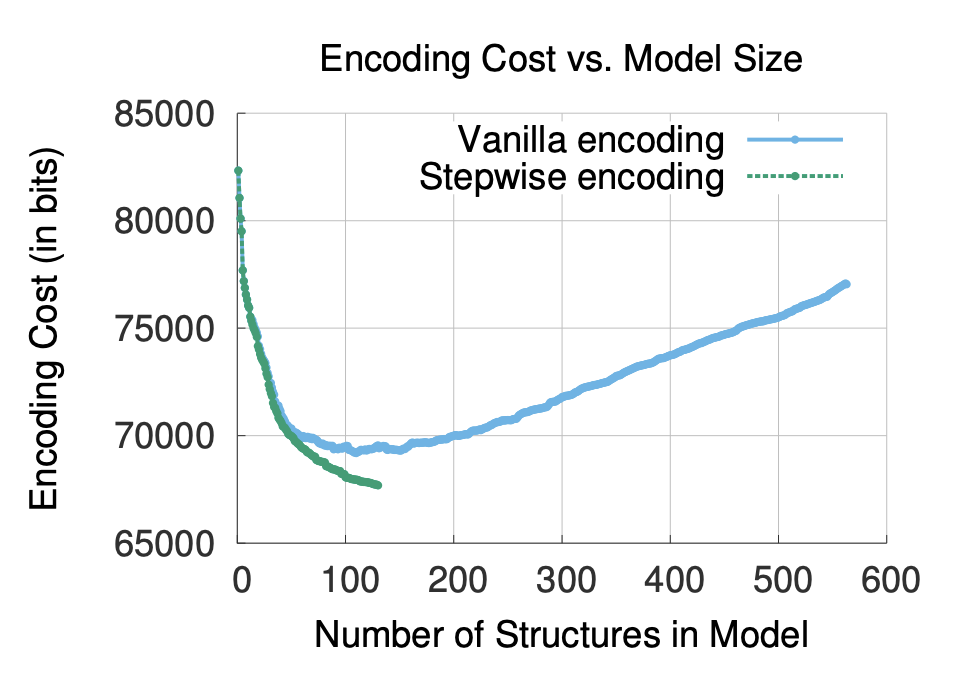 TimeCrunch: Interpretable Dynamic Graph SummarizationNeil Shah, Danai Koutra, Tianmin Zou, Brian Gallagher, and Christos FaloutsosIn ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2015
TimeCrunch: Interpretable Dynamic Graph SummarizationNeil Shah, Danai Koutra, Tianmin Zou, Brian Gallagher, and Christos FaloutsosIn ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2015How can we describe a large, dynamic graph over time? Is it random? If not, what are the most apparent deviations from randomness – a dense block of actors that persists over time, or perhaps a star with many satellite nodes that appears with some fixed periodicity? In practice, these deviations indicate patterns – for example, botnet attackers forming a bipartite core with their victims over the duration of an attack, family members bonding in a clique-like fashion over a difficult period of time, or research collaborations forming and fading away over the years. Which patterns exist in real-world dynamic graphs, and how can we find and rank them in terms of importance? These are exactly the problems we focus on in this work. Our main contributions are (a) formulation: we show how to formalize this problem as minimizing the encoding cost in a data compression paradigm, (b) algorithm: we propose TIMECRUNCH, an effective, scalable and parameter-free method for finding coherent, temporal patterns in dynamic graphs and (c) practicality: we apply our method to several large, diverse real-world datasets with up to 36 million edges and 6.3 million nodes. We show that TIMECRUNCH is able to compress these graphs by summarizing important temporal structures and finds patterns that agree with intuition.
- preprint
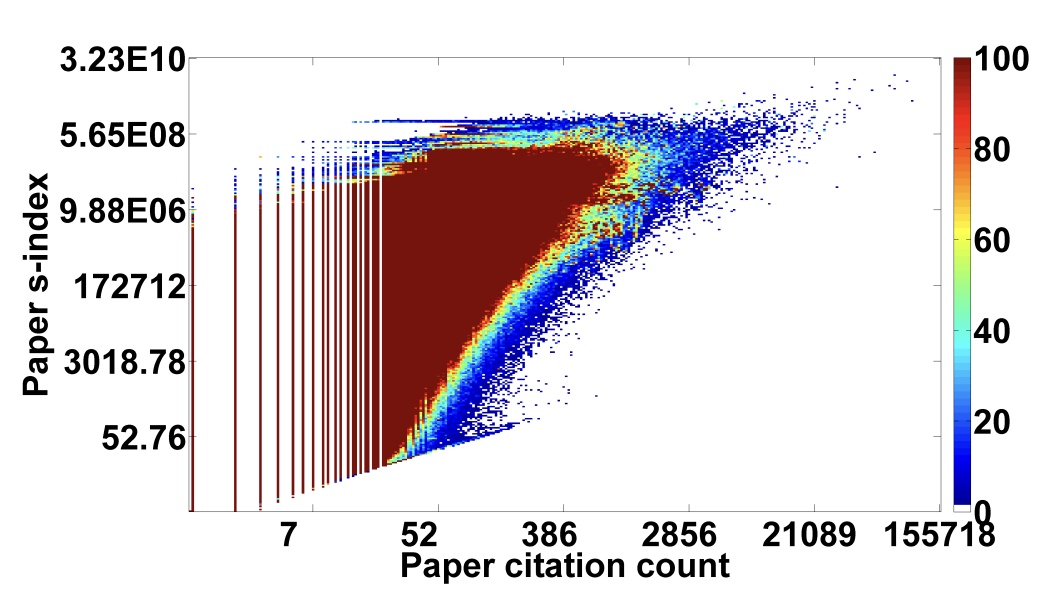 s-index: Towards Better Metrics for Quantifying Research ImpactNeil Shah and Yang SongarXiv preprint, 2015
s-index: Towards Better Metrics for Quantifying Research ImpactNeil Shah and Yang SongarXiv preprint, 2015The ongoing growth in the volume of scientific literature available today precludes researchers from efficiently discerning the relevant from irrelevant content. Researchers are constantly interested in impactful papers, authors and venues in their respective fields. Moreover, they are interested in the so-called recent "rising stars" of these contexts which may lead to attractive directions for future work, collaborations or impactful publication venues. In this work, we address the problem of quantifying research impact in each of these contexts, in order to better direct attention of researchers and streamline the processes of comparison, ranking and evaluation of contribution. Specifically, we begin by outlining intuitive underlying assumptions that impact quantification methods should obey and evaluate when current state-of-the-art methods fail to satisfy these properties. To this end, we introduce the s-index metric which quantifies research impact through influence propagation over a heterogeneous citation network. s-index is tailored from these intuitive assumptions and offers a number of desirable qualities including robustness, natural temporality and straightforward extensibility from the paper impact to broader author and venue impact contexts. We evaluate its effectiveness on the publicly available Microsoft Academic Search citation graph with over 119 million papers and 1 billion citation edges with 103 million and 21 thousand associated authors and venues respectively.
- TKDD
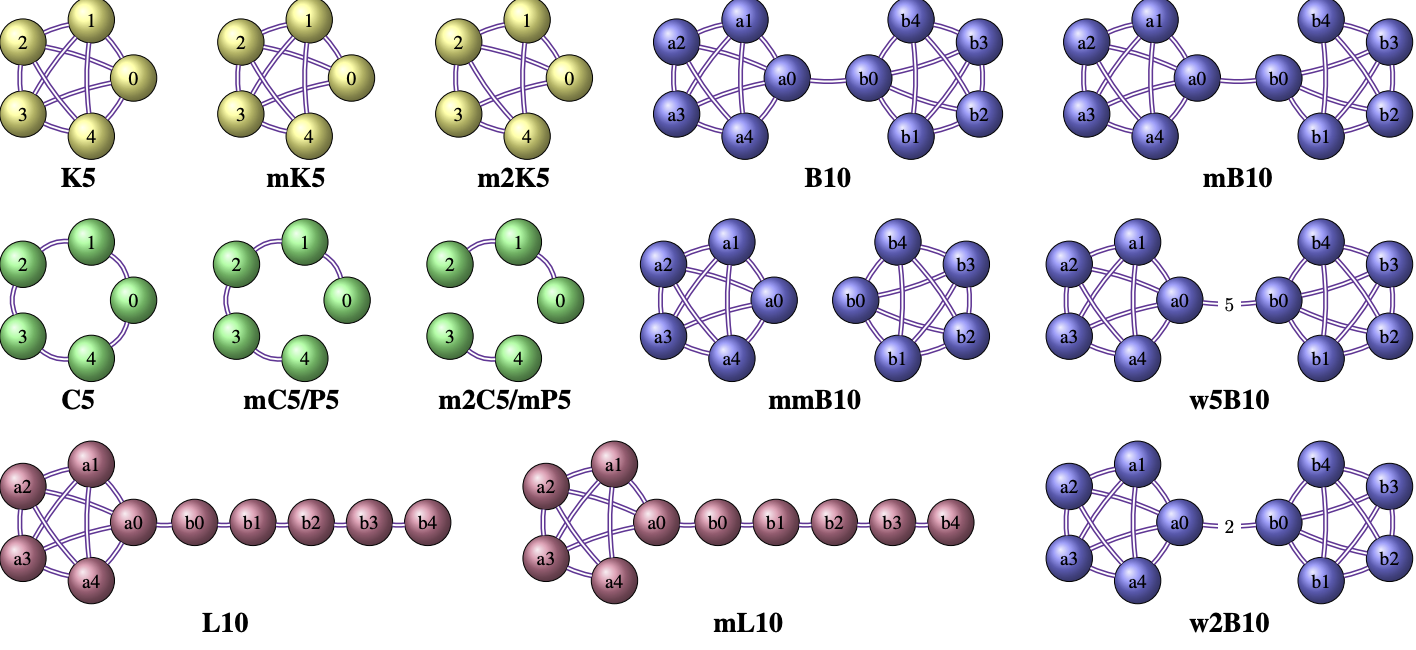 DeltaCon: A Principled Massive-Graph Similarity Function with AttributionDanai Koutra, Neil Shah, Joshua T. Vogelstein, Brian Gallagher, and Christos FaloutsosIn Transactions on Knowledge Discovery from Data, 2015
DeltaCon: A Principled Massive-Graph Similarity Function with AttributionDanai Koutra, Neil Shah, Joshua T. Vogelstein, Brian Gallagher, and Christos FaloutsosIn Transactions on Knowledge Discovery from Data, 2015How much has a network changed since yesterday? How different is the wiring of Bob’s brain (a left-handed male) and Alice’s brain (a right-handed female), and how is it different? Graph similarity with given node correspondence, i.e., the detection of changes in the connectivity of graphs, arises in numerous settings. In this work, we formally state the axioms and desired properties of the graph similarity functions, and evaluate when state-of-the-art methods fail to detect crucial connectivity changes in graphs. We propose DeltaCon, a principled, intuitive, and scalable algorithm that assesses the similarity between two graphs on the same nodes (e.g., employees of a company, customers of a mobile carrier). In conjunction, we propose DeltaCon-Attr, a related approach that enables attribution of change or dissimilarity to responsible nodes and edges. Experiments on various synthetic and real graphs showcase the advantages of our method over existing similarity measures. Finally, we employ DeltaCon and DeltaCon-Attr on real applications: (a) we classify people to groups of high and low creativity based on their brain connectivity graphs, (b) do temporal anomaly detection in the who-emails-whom Enron graph and find the top culprits for the changes in the temporal corporate email graph, and (c) recover pairs of test-retest large brain scans ( ∼17M edges, up to 90M edges) for 21 subjects.
- PAKDD
 Retweeting activity on Twitter: Signs of DeceptionMaria Giatsoglou, Despoina Chatzakou, Neil Shah, Christos Faloutsos, and Athena VakaliIn Pacific-Asia Conference on Knowledge Discovery and Data Mining, 2015
Retweeting activity on Twitter: Signs of DeceptionMaria Giatsoglou, Despoina Chatzakou, Neil Shah, Christos Faloutsos, and Athena VakaliIn Pacific-Asia Conference on Knowledge Discovery and Data Mining, 2015Given the re-broadcasts (i.e. retweets) of posts in Twitter, how can we spot fake from genuine user reactions? What will be the tell-tale sign — the connectivity of retweeters, their relative timing, or something else? High retweet activity indicates influential users, and can be monetized. Hence, there are strong incentives for fraudulent users to artificially boost their retweets’ volume. Here, we explore the identification of fraudulent and genuine retweet threads. Our main contributions are: (a) the discovery of patterns that fraudulent activity seems to follow (the “triangles ” and “homogeneity ” patterns, the formation of micro-clusters in appropriate feature spaces); and (b) “RTGen ”, a realistic generator that mimics the behaviors of both honest and fraudulent users. We present experiments on a dataset of more than 6 million retweets crawled from Twitter.
- PAKDD
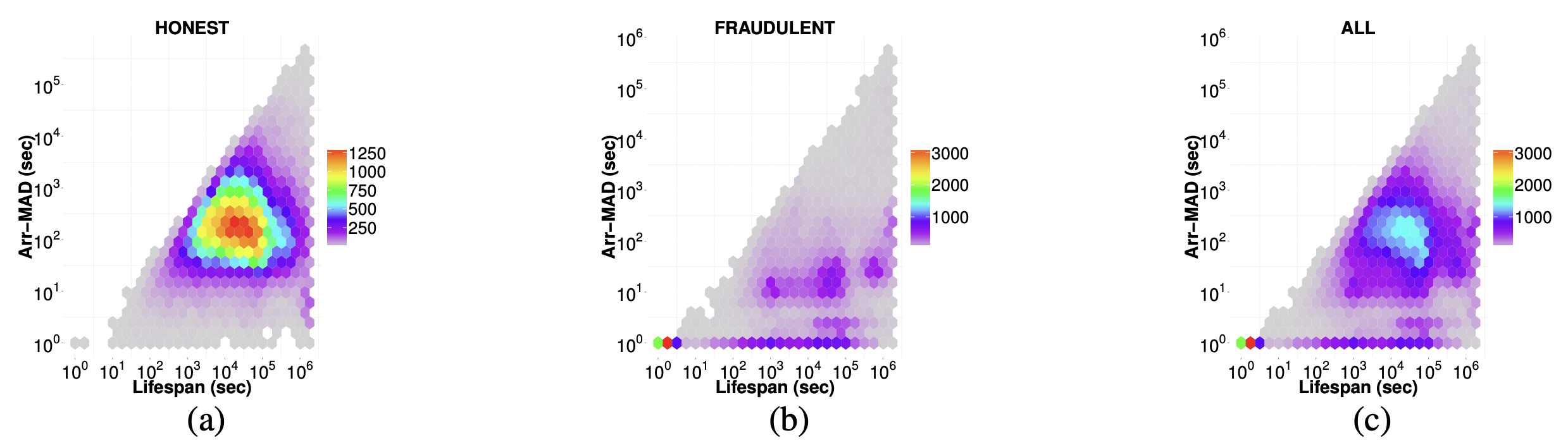 ND-SYNC: Detecting Synchronized Fraud ActivitiesMaria Giatsoglou, Despoina Chatzakou, Neil Shah, Alex Beutel, Christos Faloutsos, and Athena VakaliIn Pacific-Asia Conference on Knowledge Discovery and Data Mining, 2015
ND-SYNC: Detecting Synchronized Fraud ActivitiesMaria Giatsoglou, Despoina Chatzakou, Neil Shah, Alex Beutel, Christos Faloutsos, and Athena VakaliIn Pacific-Asia Conference on Knowledge Discovery and Data Mining, 2015Given the retweeting activity for the posts of several Twitter users, how can we distinguish organic activity from spammy retweets by paid followers to boost a post’s appearance of popularity? More generally, given groups of observations, can we spot strange groups? Our main intuition is that organic behavior has more variability, while fraudulent behavior, like retweets by botnet members, is more synchronized. We refer to the detection of such synchronized observations as the Synchonization Fraud problem, and we study a specific instance of it, Retweet Fraud Detection, manifested in Twitter. Here, we propose: (A) ND-Sync, an efficient method for detecting group fraud, and (B) a set of carefully designed features for characterizing retweet threads. ND-Sync is effective in spotting retweet fraudsters, robust to different types of abnormal activity, and adaptable as it can easily incorporate additional features. Our method achieves a 97% accuracy on a real dataset of 12 million retweets crawled from Twitter.
2014
- ICDM
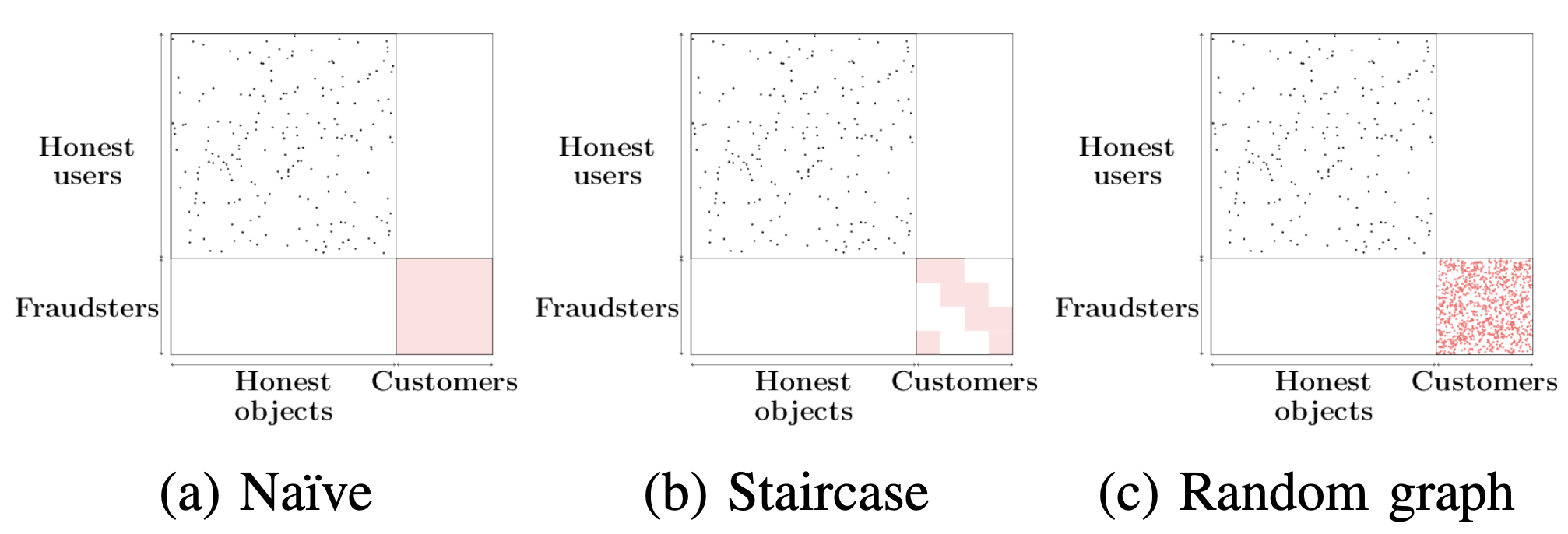 Spotting Suspicious Link Behavior with fBox: An Adversarial PerspectiveNeil Shah, Alex Beutel, Brian Gallagher, and Christos FaloutsosIn IEEE International Conference on Data Mining, 2014
Spotting Suspicious Link Behavior with fBox: An Adversarial PerspectiveNeil Shah, Alex Beutel, Brian Gallagher, and Christos FaloutsosIn IEEE International Conference on Data Mining, 2014How can we detect suspicious users in large online networks? Online popularity of a user or product (via follows, page-likes, etc.) can be monetized on the premise of higher ad click-through rates or increased sales. Web services and social networks which incentivize popularity thus suffer from a major problem of fake connections from link fraudsters looking to make a quick buck. Typical methods of catching this suspicious behavior use spectral techniques to spot large groups of often blatantly fraudulent (but sometimes honest) users. However, small-scale, stealthy attacks may go unnoticed due to the nature of low-rank eigenanalysis used in practice. In this work, we take an adversarial approach to find and prove claims about the weaknesses of modern, state-of-the-art spectral methods and propose fBox, an algorithm designed to catch small-scale, stealth attacks that slip below the radar. Our algorithm has the following desirable properties: (a) it has theoretical underpinnings, (b) it is shown to be highly effective on real data and (c) it is scalable (linear on the input size). We evaluate fBox on a large, public 41.7 million node, 1.5 billion edge who-follows-whom social graph from Twitter in 2010 and with high precision identify many suspicious accounts which have persisted without suspension even to this day.
2012
-
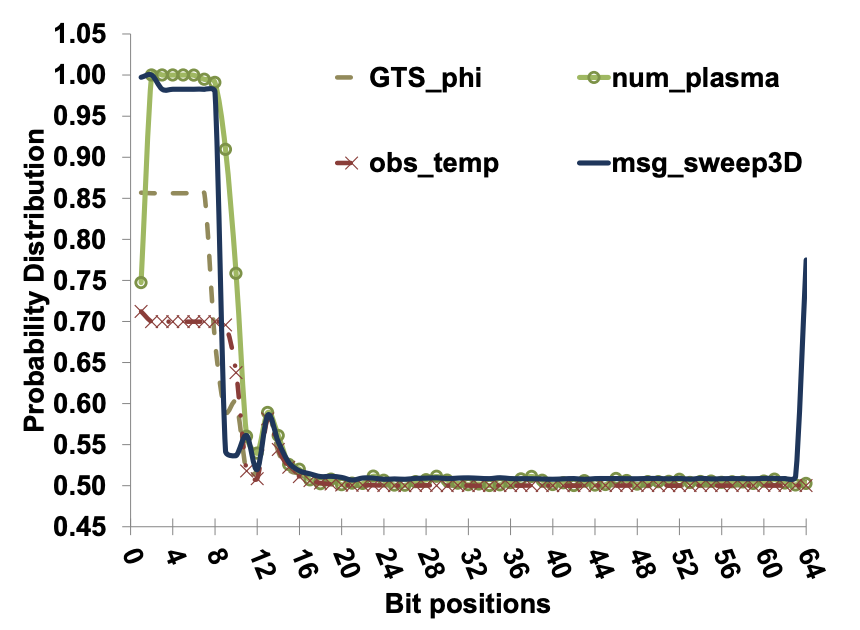 Improving I/O Throughput with PRIMACY: Preconditioning ID-Mapper for Compressing IncompressibilityNeil Shah, Eric R. Schendel, Sriram Lakshminarasimhan, Saurabh V. Pendse, Terry Rogers, and Nagiza F. SamatovaIn IEEE Cluster 2012, 2012
Improving I/O Throughput with PRIMACY: Preconditioning ID-Mapper for Compressing IncompressibilityNeil Shah, Eric R. Schendel, Sriram Lakshminarasimhan, Saurabh V. Pendse, Terry Rogers, and Nagiza F. SamatovaIn IEEE Cluster 2012, 2012The ability to efficiently handle massive amounts of data is necessary for the continuing development towards exascale scientific data-mining applications and database systems. Unfortunately, recent years have shown a growing gap between the size and complexity of data produced from scientific applications and the limited I/O bandwidth available on modern high-performance computing systems. Utilizing data compression in order to lower the degree of I/O activity offers a promising means to addressing this problem. However, the standard compression algorithms previously explored for such use offer limited gains on both the end-to-end throughput and storage fronts. In this paper, we introduce an in-situ compression scheme aimed at improving end-to-end I/O throughput as well as reduction of dataset size. Our technique, PRIMACY (Preconditioning Id-MApper for Compressing incompressibility), acts as a preconditioner for standard compression libraries by modifying representation of original floating-point scientific data to increase byte-level repeatability, allowing standard loss less compressors to take advantage of their entropy-based byte-level encoding schemes. We additionally present a theoretical model for compression efficiency in high-performance computing environments and evaluate the efficiency of our approach via comparative analysis. Based on our evaluations on 20 real-world scientific datasets, PRIMACY achieved up to 38% and 22% improvements upon standard end-to-end write and read throughputs respectively in addition to a 25% increase in compression ratios paired with 3-to-4-fold improvement in both compression and decompression throughput over general purpose compressors.
- DEXA
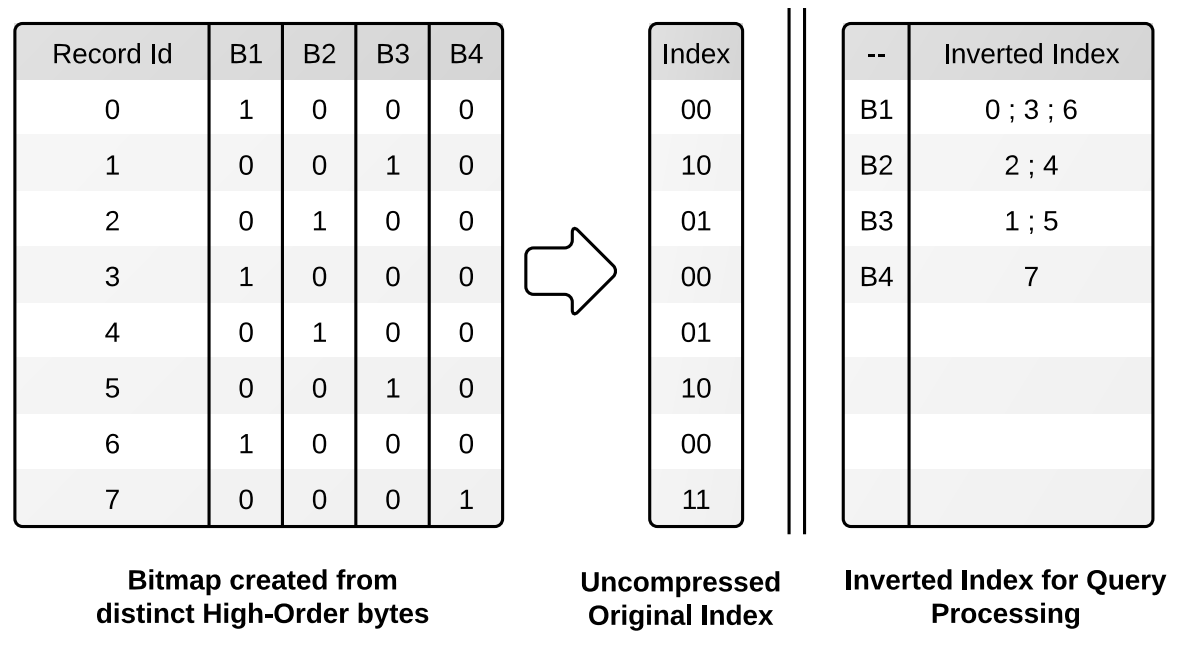 Analytics-driven Lossless Data Compression for Rapid In-situ Indexing, Storing, and QueryingIsha Arkatkar, John Jenkins, Sriram Lakshminarasimhan, Neil Shah, Eric R. Schendel, Stephane Ethier, CS Chang, Jackie Chen, and 4 more authorsIn International Conference on Database and Expert Systems Applications, 2012
Analytics-driven Lossless Data Compression for Rapid In-situ Indexing, Storing, and QueryingIsha Arkatkar, John Jenkins, Sriram Lakshminarasimhan, Neil Shah, Eric R. Schendel, Stephane Ethier, CS Chang, Jackie Chen, and 4 more authorsIn International Conference on Database and Expert Systems Applications, 2012The analysis of scientific simulations is highly data-intensive and is becoming an increasingly important challenge. Peta-scale data sets require the use of light-weight query-driven analysis methods, as opposed to heavy-weight schemes that optimize for speed at the expense of size. This paper is an attempt in the direction of query processing over losslessly compressed scientific data. We propose a co-designed double-precision compression and indexing methodology for range queries by performing unique-value-based binning on the most significant bytes of double precision data (sign, exponent, and most significant mantissa bits), and inverting the resulting metadata to produce an inverted index over a reduced data representation. Without the inverted index, our method matches or improves compression ratios over both general-purpose and floating-point compression utilities. The inverted index is light-weight, and the overall storage requirement for both reduced column and index is less than 135%, whereas existing DBMS technologies can require 200-400%. As a proof-of-concept, we evaluate univariate range queries that additionally return column values, a critical component of data analytics, against state-of-the-art bitmap indexing technology, showing multi-fold query performance improvements.
- ICDE
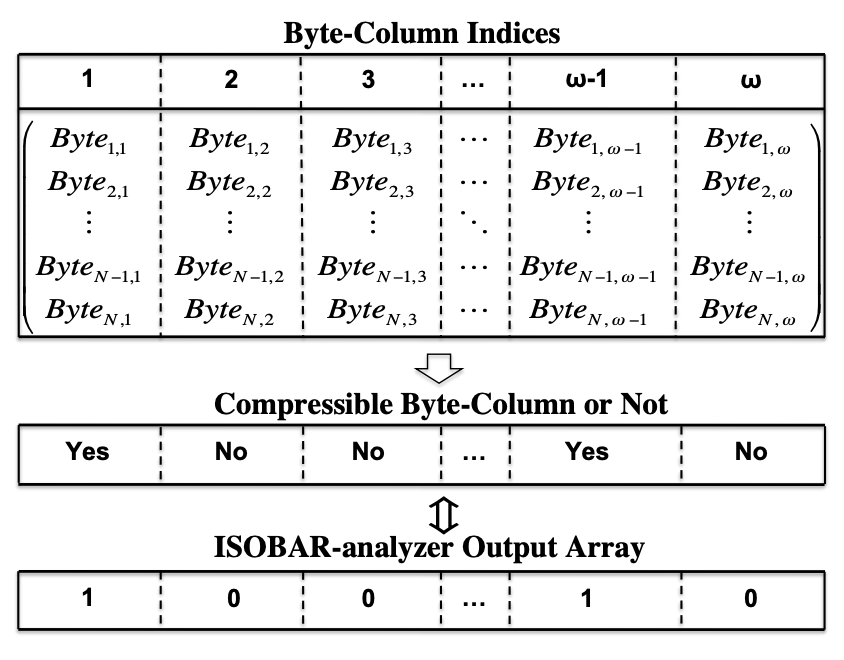 ISOBAR Preconditioner for Effective and High-throughput Lossless Data CompressionEric R. Schendel, Ye Jin, Neil Shah, Jackie Chen, CS Chang, Seung-Hoe Ku, Stephane Ethier, Scott Klasky, and 3 more authorsIn IEEE International Conference on Data Engineering, 2012
ISOBAR Preconditioner for Effective and High-throughput Lossless Data CompressionEric R. Schendel, Ye Jin, Neil Shah, Jackie Chen, CS Chang, Seung-Hoe Ku, Stephane Ethier, Scott Klasky, and 3 more authorsIn IEEE International Conference on Data Engineering, 2012Efficient handling of large volumes of data is a necessity for exascale scientific applications and database systems. To address the growing imbalance between the amount of available storage and the amount of data being produced by high speed (FLOPS) processors on the system, data must be compressed to reduce the total amount of data placed on the file systems. General-purpose loss less compression frameworks, such as zlib and bzlib2, are commonly used on datasets requiring loss less compression. Quite often, however, many scientific data sets compress poorly, referred to as hard-to-compress datasets, due to the negative impact of highly entropic content represented within the data. An important problem in better loss less data compression is to identify the hard-to-compress information and subsequently optimize the compression techniques at the byte-level. To address this challenge, we introduce the In-Situ Orthogonal Byte Aggregate Reduction Compression (ISOBAR-compress) methodology as a preconditioner of loss less compression to identify and optimize the compression efficiency and throughput of hard-to-compress datasets.
2011
-
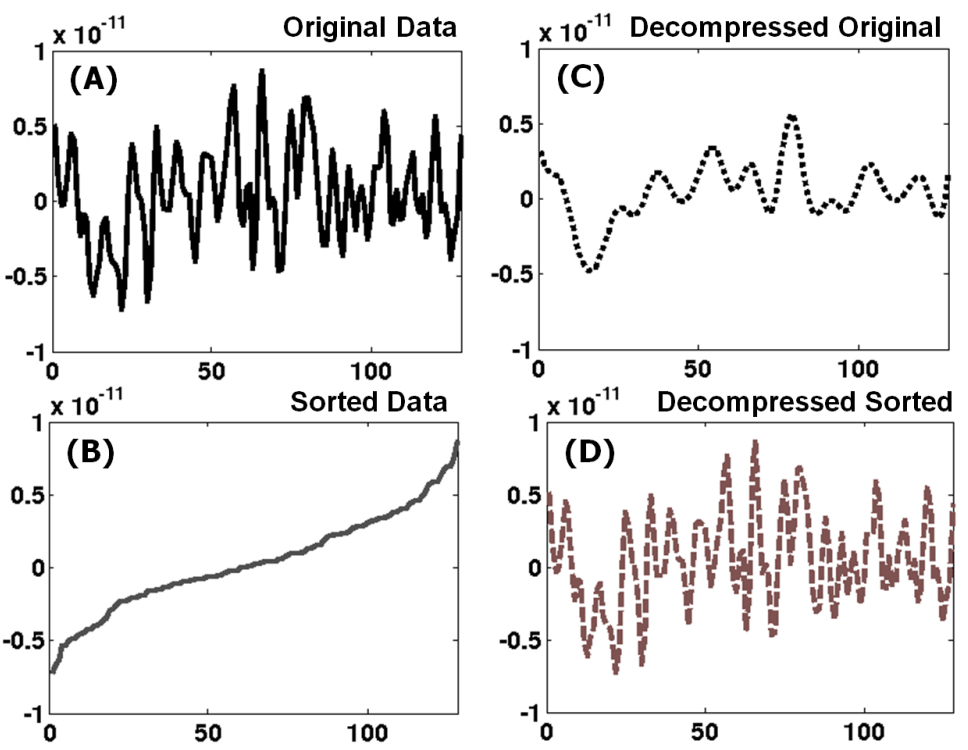 Compressing the Incompressible with ISABELA: In-situ Reduction of Spatio-Temporal DataSriram Lakshminarasimhan, Neil Shah, Stephane Ethier, Seung-Hoe Ku, C.S. Chang, Scott Klasky, Rob Latham, Rob Ross, and 1 more authorIn Euro-Par 2011, 2011
Compressing the Incompressible with ISABELA: In-situ Reduction of Spatio-Temporal DataSriram Lakshminarasimhan, Neil Shah, Stephane Ethier, Seung-Hoe Ku, C.S. Chang, Scott Klasky, Rob Latham, Rob Ross, and 1 more authorIn Euro-Par 2011, 2011Modern large-scale scientific simulations running on HPC systems generate data in the order of terabytes during a single run. To lessen the I/O load during a simulation run, scientists are forced to capture data infrequently, thereby making data collection an inherently lossy process. Yet, lossless compression techniques are hardly suitable for scientific data due to its inherently random nature; for the applications used here, they offer less than 10% compression rate. They also impose significant overhead during decompression, making them unsuitable for data analysis and visualization that require repeated data access. To address this problem, we propose an effective method for In-situ Sort-And-B-spline Error-bounded Lossy Abatement (ISABELA) of scientific data that is widely regarded as effectively incompressible. With ISABELA, we apply a preconditioner to seemingly random and noisy data along spatial resolution to achieve an accurate fitting model that guarantees a ≥0.99 correlation with the original data. We further take advantage of temporal patterns in scientific data to compress data by ≈ 85%, while introducing only a negligible overhead on simulations in terms of runtime. ISABELA significantly outperforms existing lossy compression methods, such as Wavelet compression. Moreover, besides being a communication-free and scalable compression technique, ISABELA is an inherently local decompression method, namely it does not decode the entire data, making it attractive for random access.
- ICDM
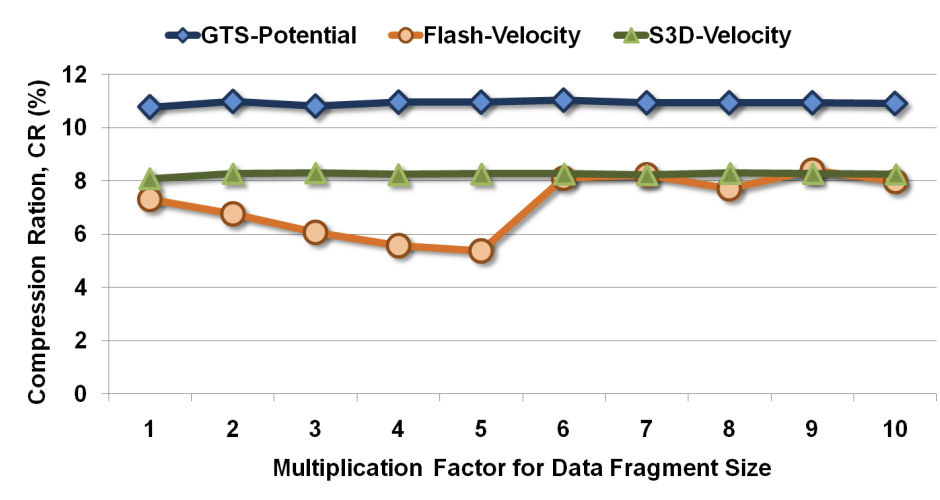 S-preconditioner for Multi-fold Data Reduction with Guaranteed User-controlled AccuracyYe Jin, Sriram Lakshminarasimhan, Neil Shah, Zhenhuan Gong, CS Chang, Jackie Chen, Stephane Ethier, Hemant Kolla, and 6 more authorsIn IEEE International Conference on Data Mining, 2011
S-preconditioner for Multi-fold Data Reduction with Guaranteed User-controlled AccuracyYe Jin, Sriram Lakshminarasimhan, Neil Shah, Zhenhuan Gong, CS Chang, Jackie Chen, Stephane Ethier, Hemant Kolla, and 6 more authorsIn IEEE International Conference on Data Mining, 2011The growing gap between the massive amounts of data generated by petascale scientific simulation codes and the capability of system hardware and software to effectively analyze this data necessitates data reduction. Yet, the increasing data complexity challenges most, if not all, of the existing data compression methods. In fact, lossless compression techniques offer no more than 10% reduction on scientific data that we have experience with, which is widely regarded as effectively incompressible. To bridge this gap, in this paper, we advocate a transformative strategy that enables fast, accurate, and multi-fold reduction of double-precision floating-point scientific data. The intuition behind our method is inspired by an effective use of preconditioners for linear algebra solvers optimized for a particular class of computational "dwarfs" (e.g., dense or sparse matrices). Focusing on a commonly used multi-resolution wavelet compression technique as the underlying "solver" for data reduction we propose the S-preconditioner, which transforms scientific data into a form with high global regularity to ensure a significant decrease in the number of wavelet coefficients stored for a segment of data. Combined with the subsequent EQ-calibrator, our resultant method (called S-Preconditioned EQ-Calibrated Wavelets (SPEQC-Wavelets)), robustly achieved a 4- to 5-fold data reduction-while guaranteeing user-defined accuracy of reconstructed data to be within 1% point-by-point relative error, lower than 0.01 Normalized RMSE, and higher than 0.99 Pearson Correlation. In this paper, we show the results we obtained by testing our method on six petascale simulation codes including fusion, combustion, climate, astrophysics, and subsurface groundwater in addition to 13 publicly available scientific datasets. We also demonstrate that application-driven data mining tasks performed on decompressed variables or their derived quantities produce results of comparable quality with the ones for the original data.
2010
- SciDAC
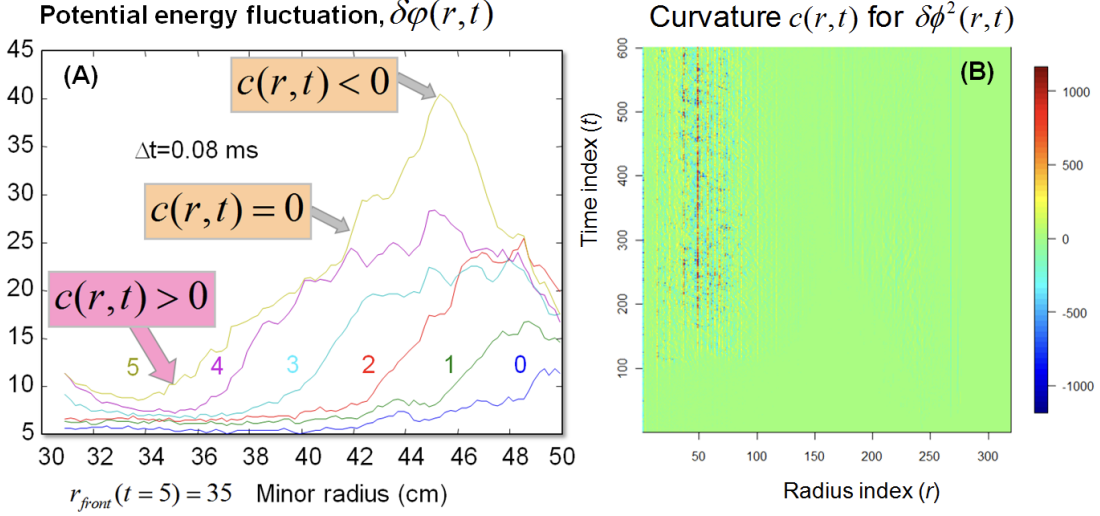 Automatic and Statistically Robust Spatio-Temporal Detection and Tracking of Fusion Plasma Turbulent FrontsNeil Shah, Yekaterina Shpanskaya, CS Chang, Seung-Hoe Ku, Anatoli V. Melechko, and Nagiza F. SamatovaIn Scientific Discovery through Advanced Computing, 2010
Automatic and Statistically Robust Spatio-Temporal Detection and Tracking of Fusion Plasma Turbulent FrontsNeil Shah, Yekaterina Shpanskaya, CS Chang, Seung-Hoe Ku, Anatoli V. Melechko, and Nagiza F. SamatovaIn Scientific Discovery through Advanced Computing, 2010The controlled production of thermo-nuclear fusion energy is critical for providing an alternative, environmentally friendly, and renewable energy source on our planet. The technical challenge is to stabilize the dynamic turbulent flow of hot plasma in magnetic fields in a fusion energy reactor. More specifically, the issue is how to control fusion plasma instabilities, or turbulence–an analogy comparable to learning how to “Hold the Sun.” To address this issue, we create computational and mathematical methodology to discover and track–both in space and time–the intricate patterns of dynamic plasma turbulence during fusion energy production in a reactor simulated on a supercomputer. In doing so, we establish several aims. First, from extreme scale data, we automatically discover the structure of fronts, or patterns where the turbulence starts, and analyze their dynamic behaviour including speed and direction of front propagation. To do this, we create an algorithm for automatic turbulent front detection, track and quantify front propagation in space and time, and assess the predictability of the proposed methodology. Comprehensively, this process can potentially predict the structure, dynamics, and function of fusion plasma turbulence. It could also enable similar analyses required in other fields, such as astrophysics and combustion
2009
-
 pR: Automatic Parallelization of Data-parallel Statistical Computing Codes for R in Hybrid Multi-node and Multi-core EnvironmentsPaul Breimyer, Guruprasad Kora, William Hendrix, Neil Shah, and Nagiza F. SamatovaIn IADIS International Conference on Applied Computing 2009, 2009
pR: Automatic Parallelization of Data-parallel Statistical Computing Codes for R in Hybrid Multi-node and Multi-core EnvironmentsPaul Breimyer, Guruprasad Kora, William Hendrix, Neil Shah, and Nagiza F. SamatovaIn IADIS International Conference on Applied Computing 2009, 2009The increasing size and complexity of modern scientific data sets challenge the capabilities of traditional statistical computing. High-Performance Statistical Parallel Computing is a promising strategy to address these challenges, especially as multi-core parallel computing architectures become increasingly prevalent. However, parallel statistical computing introduces implementation complexities and, therefore, an automatic parallelization approach would be ideal. Data-parallel statistical computations that aim to evaluate the same function on different subsets of data represent natural candidates for automatic parallelization due to their inherent inter-process independence. In this paper, we extend the pR middleware for the R open-source statistical environment to support automatic parallelization of data-parallel tasks in multi-node, multi-core, and hybrid environments. pR requires few or no changes to existing serial codes and yielded over 50% end-to-end execution time improvements in our tests, compared to the commonly used snow R package.